python统计喜欢的小说主角出场次数
这周老师布置了一项作业,让我们回去将自己喜欢的小说里面的主角出场次数统计出来,我对这个充满了兴趣,但我遇到了三个问题:
(1)一开始选了一部超长的小说(最爱之一),但是运行时老是不行,老是显示下图错误:

(2)我一开始是像书本那样直接把txt文件名打上去,类似于open(‘two.txt’,'r').read(),但总是出现一下一行字:

(3)三个字的人名总是会有几个人只打了两个字
一、撇开这些问题,开始写代码:
我刚开始以为是小说太长了,运行不了,就找了一部短一些的小说,我最爱的小说——《我和你差之微毫的世界》
结果成功了
代码如下:
import jieba
txt=open("d:\\《我和你差之微毫的世界》北倾.txt","r").read()
others={'有些','自己','已经','知道','时候','刚刚','一下','看着','没有','像是','一个','一眼','好像','什么','声音','这样','起来','这么','回来','就是','微微','一声',
'这个','这才','目光','看见','觉得','过来','不是','怎么','现在','突然','一会','还是','几分','一起','顿时','回去','眼神','安然','只是','原本','出去','似乎',
'眼睛','下来','整个','手指','两个','因为','一直','电话','语气','问道','出来','心里','开始','门口','这里','那么','房间','那个','格外','灯光','时间','回答','一般','转身',
'几乎','事情','坐在','说话','表情'} words= jieba.lcut(txt) #jieba将txt分成多个分词
counts={} #建立一个空字典
for word in words: #这里的word是指遍历从txt的第一个分词到最后一个分词
if len(word)==1:
continue
elif word=="小叔" or word=='温少远'or word=='温少':
rword="小叔"
else:
rword=word
counts[rword]=counts.get(rword,0)+1
for word in others:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True) for i in range(5):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
结果:

实在是太开心啦啦啦啦,虽然others那里耗费了很长时间,做出来还是很开心的。
二、解决问题(1)
我还是对第一篇小说百思不得其解,上网百度了后才知道,原来是我第一篇小说另存为是选择编码方式不是utf-8,只要改成utf-8就可以了
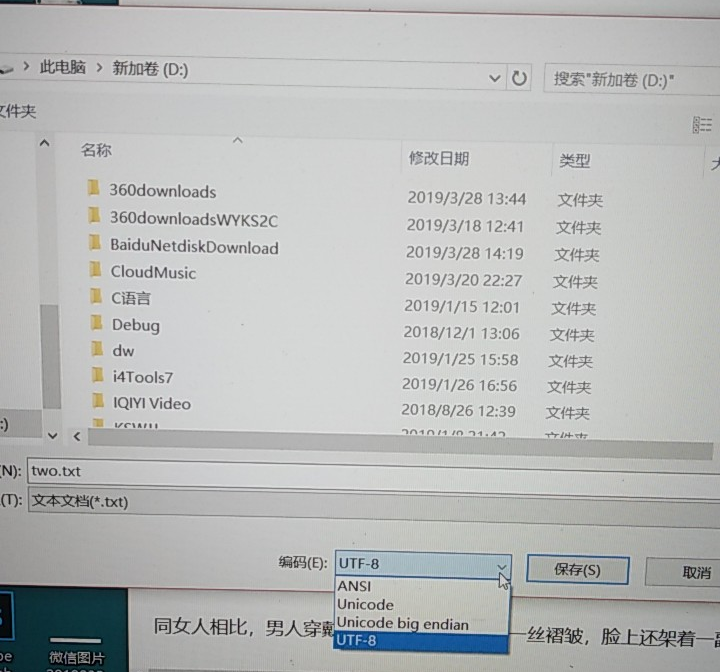
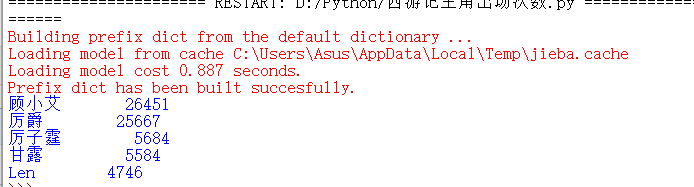
我改了一下代码,换成了第一部超长小说的统计,代码就不贴了,类似的,但不知道为什么厉爵风只出现了厉爵(有待考证???):
三、解决问题(2)
上百度搜一下,找到了一个解决方法:把命令改为txt=open(‘d:\\two.txt’,'r').read()就可以了
原因:在python中‘\’为转义字符,要想输出‘\’,要么多加一个"\",写成\\,要么在字符串前加r,txt=open(r'd:\\two.txt','r').read()
四、解决问题(3)
只要在程序里添加一个jieba.add_word()就可以自定义一个新的分词了,但该新的分词只对该程序有效,并不是永久添加
import jieba
jieba.add_word('厉爵风')
txt=open("d://two.txt","r",encoding='utf-8').read()
others={'有些','自己','已经','知道','时候','刚刚','一下','看着','没有','像是','一个','一眼','好像','什么','声音','这样','起来','这么','回来','就是','微微','一声','说道',
'这个','这才','目光','看见','觉得','过来','不是','怎么','现在','突然','一会','还是','几分','一起','顿时','回去','眼神','安然','只是','原本','出去','似乎',
'眼睛','下来','整个','手指','两个','因为','一直','电话','语气','问道','出来','心里','开始','门口','这里','那么','房间','那个','格外','灯光','时间','回答','一般','转身',
'几乎','事情','坐在','说话','表情'} words= jieba.lcut(txt) #jieba将txt分成多个分词
counts={} #建立一个空字典
for word in words: #这里的word是指遍历从txt的第一个分词到最后一个分词
if len(word)==1:
continue
elif word=="厉子霆" or word=='Len'or word=='LG':
rword="LG"
else:
rword=word
counts[rword]=counts.get(rword,0)+1
for word in others:
del(counts[word])
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True) for i in range(5):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
结果如图:
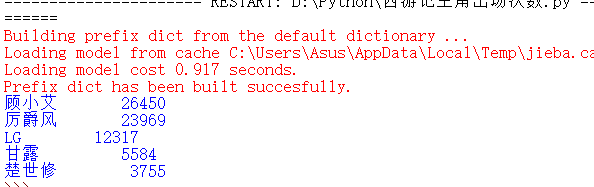
小结:问题都解决啦,超级开心的
python统计喜欢的小说主角出场次数的更多相关文章
- Python统计日志中每个IP出现次数
介绍了Python统计日志中每个IP出现次数的方法,实例分析了Python基于正则表达式解析日志文件的相关技巧,需要的朋友可以参考下 本脚本可用于多种日志类型 #-*- coding:utf-8 -* ...
- python 统计字符串中指定字符出现次数的方法
python 统计字符串中指定字符出现次数的方法: strs = "They look good and stick good!" count_set = ['look','goo ...
- python统计英文首字母出现的次数
使用python解析有道词典导出的xml格式单词,统计各个首字母出现的次数,并按次数由多到少进行排序 相关实现 导出的xml格式如下 <wordbook> <item> < ...
- python统计字符串里每个字符的次数
方法一: 推导式 dd="ewq4aewtaSDDSFDTFDSWQrtewtyufashas" print {i:dd.count(i) for i in dd} 方法二: co ...
- 使用python统计《三国演义》小说里人物出现次数前十名,并实现可视化。
一.安装所需要的第三方库 jieba (jieba是优秀的中文分词第三分库) pyecharts (一个优秀的数据可视化库) <三国演义>.txt下载地址(提取码:kist ) 使用pyc ...
- 如何用Python统计《论语》中每个字的出现次数?10行代码搞定--用计算机学国学
编者按: 上学时听过山师王志民先生一场讲座,说每个人不论干什么,都应该学习国学(原谅我学了计算机专业)!王先生讲得很是吸引我这个工科男,可能比我的后来的那些同学听课还要认真些,当然一方面是兴趣.一方面 ...
- python统计元素重复次数
python统计元素重复次数 # !/usr/bin/python3.4 # -*- coding: utf-8 -*- from collections import Counter arr = [ ...
- Python统计列表中的重复项出现的次数的方法
本文实例展示了Python统计列表中的重复项出现的次数的方法,是一个很实用的功能,适合Python初学者学习借鉴.具体方法如下:对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在 ...
- python统计文本中每个单词出现的次数
.python统计文本中每个单词出现的次数: #coding=utf-8 __author__ = 'zcg' import collections import os with open('abc. ...
随机推荐
- ajax中 XmlHttp的open( )方法
博客分类: Ajax XML open 创建一个新的http请求,并指定此请求的方法.URL以及验证信息 语法 oXMLHttpRequest.open(bstrMethod, bstrUrl, ...
- java 中toString()方法详解
1.toString()方法 Object类具有一个toString()方法,你创建的每个类都会继承该方法.它返回对象的一个String表示,并且对于调试非常有帮助.然而对于默认的toString() ...
- [GO]文件的读写
首先写一个文件 package main import ( "os" "fmt" ) func WriteFile(path string) { //打开文件, ...
- 使用jasmine-node 进行NodeJs单元测试 环境搭建
关于jasmine就不多说了,关于语法请参加官方文档.http://pivotal.github.io/jasmine/ 关于NodeJS的单元测试框架有多种,如果要在NodeJS中使用jasmine ...
- unittest测试框架详谈及实操(四)
测试套件 应用unittest的Test Suite特性,可以将不同的测试组成一个逻辑组,然后设置统一的测试套来一起执行测试.通过TestSuite.TestLoader类来创建测试套件,最后用Tes ...
- CodeForces 408E Curious Array(组合数学+差分)
You've got an array consisting of n integers: a[1], a[2], ..., a[n]. Moreover, there are m queries, ...
- Java 实现 WC.exe
Github:https://github.com/YJOED/Code/tree/master/WC/src 一.题目:实现一个统计程序,它能正确统计程序文件中的字符数.单词数.行数,以及还具备其他 ...
- c# 用户输入一个字符串,求字符串的长度
C# 用户输入一个字符串,求字符串的长度使用字符串的length: class Program { static void Main(string[] args) { Console.WriteLi ...
- Java 访问修饰符使用规则
作用域 当前类 同一package 子孙类 其他package public √ √ √ √ protected √ √ √ × friendly √ √ × × private √ × × × 1. ...
- SPOJ distinct subtrings
题目链接:戳我 后缀自动机模板? 求不同的子串数量. 直接\(\sum t[i].len-t[t[i].ff].len\)即可 代码如下: #include<iostream> #incl ...