匈牙利算法、KM算法
PS:其实不用理解透增广路,交替路,网上有对代码的形象解释,看懂也能做题,下面我尽量把原理说清楚
-
二分图: 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B
),则称图G为一个二分图。

匹配: 一个匹配即一个包含若干条边的集合,且其中任意两条边没有公共端点。下图标红的边即为匹配

最大匹配: 匹配数最大,如下图有4条匹配边
完全匹配: 即所有的顶点都是匹配点,上图(Fig.4)即为完全匹配,不是所有的图都存在完全匹配
交替路: 从未匹配点出发,依次经过未匹配的边和已匹配的边,即为交替路,如Fig.3:3 -> 5 -> 1 -> 7 -> 4 -> 8
增广路(也称增广轨或交错轨): 如果交替路经过除出发点外的另一个未匹配点,则这条交替路称为增广路,如交替路概念的例子,其途径点8,即为增广路
匈牙利算法
由增广路的定义推出下面三个结论(设P为一条增广路):
1). P的路径长度一定为奇数,第一条边和最后一条边都是未匹配的边(根据要途经已匹配的边和要经过另一个未匹配点,这个结论可以理解成第一个点和最后一个点都是未匹配点,可以在Fig.3上的增广路观察到)
2). P经过取反操作可以得到一个更大的匹配图(取反操作即,未匹配的边变成匹配的边,匹配的边变成未匹配的边,这个结论根据结论1).和交替路概念可得该结论)
3). 当且仅当不存在关于图M的增广路径,则图M为最大匹配
算法思路:不停找增广路,并增加匹配的个数
代码过程模拟(图片来源)
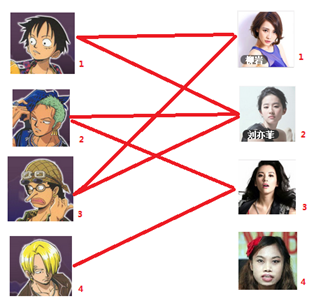
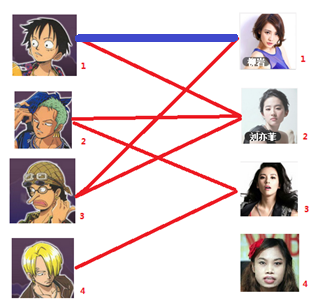
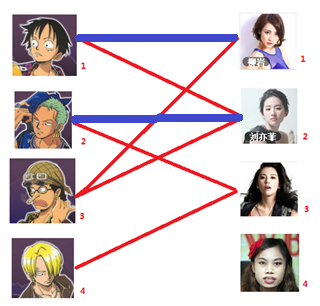
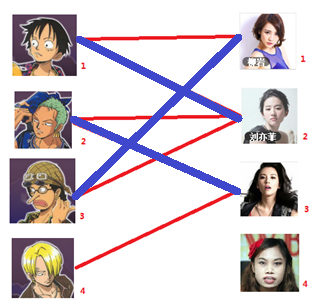
这里就解释第三幅图到第四幅图的过程,注意这里的过程就是找增广路。图三开始,男3可以匹配女1,(男3 -> 女1),发现女1已经跟男1匹配(男3 -> 女1 -> 男1),看到男1可以跟女2匹配(注意从开始到现在的是未匹配边,匹配边,未匹配边)这样走下去,路径是男3 -> 女1 -> 男1 -> 女2 -> 男2 -> 女3,此时是以未匹配边结束且找不到匹配边了。
求最大匹配的模板
#include <iostream>
#include <algorithm>
using namespace std;
const int MAXN = 105;
int x, y, mp[MAXN][MAXN];
int mx[MAXN], my[MAXN];//x 跟哪个 y 匹配s
int vis[MAXN];//一条增广路中哪些 y 点被访问过
int dfs(int a)
{
for(int i = 1;i <= n;++i)
{
//先找出与 a 点有联系且没被访问过的 y 点
if(!vis[i] && mp[a][i])
{
vis[i] = 1;
//然后从就是 x -> i -> my[i] 构造这条增广路,接着就是 dfs(my[i]),重复以上操作
//根据增广路的结论,如果存在增广路,那么最后 my[i] == 0,即为未匹配点
//然后将其赋新值,根据 DFS 递归各层,该赋值即为增广路中进行取反操作,未匹配边变为匹配边
//至于匹配边变为未匹配边,my[i] 被赋新值
//若不存在增广路,那么就没进行赋值,即不取反
if(!my[i] || dfs(my[i]))
{
my[i] = a;
return 1;
}
}
}
return 0;
}
int solve()
{
int ret = 0;
fill(mx, mx + MAXN, 0);
fill(my, my + MAXN, 0);
//刚开始的 x 都是未匹配点
//vis 每次清零,vis 就是增广路中的 y 点
for(int i = 1;i <= x;++i)
{
fill(vis, vis + MAXN, 0);
ret += dfs(i);
}
return ret;
}
#include <iostream>
#include <cstring>
using namespace std;
const int MAXN = 505;//这题数组要开大
int x, y, mp[MAXN][MAXN];
int mx[MAXN], my[MAXN];//x 跟哪个 y 匹配s
int vis[MAXN];//一条增广路中哪些 y 点被访问过
int dfs(int a)
{
for(int i = 1;i <= y;++i)
{
if(!vis[i] && mp[a][i])
{
vis[i] = 1;
if(!my[i] || dfs(my[i]))
{
my[i] = a;
return 1;
}
}
}
return 0;
}
int solve()
{
int ret = 0;
memset(mx, 0, sizeof(mx));
memset(my, 0, sizeof(my));
for(int i = 1;i <= x;++i)
{
fill(vis, vis + MAXN, 0);
ret += dfs(i);
}
return ret;
}
int main()
{
int n;
cin >> n;
while(n--)
{
cin >> x >> y;
memset(mp, 0, sizeof(mp));
int num, t;
for(int i = 1;i <= x;++i)
{
cin >> num;
while(num--)
{
cin >> t;
mp[i][t] = 1;
}
}
if(solve() == x)
cout << "YES" << endl;
else
cout << "NO" << endl;
}
return 0;
}
时间复杂度:邻接矩阵最坏O(n ^ 3), 邻接表O(nm)
空间复杂度:邻接矩阵O(n ^ 2), 邻接表O(n + m)
扩展:匈牙利算法也可以看成DFS过程,参考
KM算法
该算法是求带权二分图的最大权完美匹配
此篇易懂,新概念少,没代码,概念看不懂的,建议先看左边易懂那篇再来,这个是代码篇
顶标:设顶点 Xi 的顶标为 A[i],顶点 Yi 的顶标为 B[j],顶点 Xi 与 Yj 之间的边权为 w[i][j],初始化时,A[i] 的值为与该点关联的最大边权值,B[j] 的值为0
相等子图:选择 A[i] + B[j] = w[i][j] 的边 <i, j> 构成的子图,就是相等子图
算法执行过程中,对任一条边<i, j>,A[i] + B[j] >= w[i][j] 恒成立,这个下面图示解释清楚
这里的算法介绍是用slack[j]数组优化过,slack数组存的数是Y部的点相等子图时,最小要增加的值
没有优化过的容易理解,代码量也短,去原博客先看完没有优化的会更容易理解优化过的代码
算法图示:
给个二分图,只取边权跟顶标相等的边,边权值跟顶标理解为工作效率

看到员工B,B与c以外的其他工作尝试匹配后,顶标和,即上面说的A[i] + B[j] >= w[i][j],并且最小的差值为1,该差值存在slack数组里,当B与c尝试匹配,因为A -> c,就能找到一条增广路,B -> c -> A -> a,此时A只有找到a匹配,但是A -> a 的顶标和 = 4 也是大于边权值 3,与slack数组比较,存储最小的差值1。
因为能够进行匹配的是相等子图,即不存在此相等子图的减少量,所以遍历未匹配的Y部的slack数组,找出最小的减少量minz。我们要使总的工作效率尽可能地高,即减少地少。
若X部的点还未匹配,就将增光路中X部减去minz,即下图中A、B都减去1,Y部加上minz,把不在增广路中的Y部的点的slack值减去minz,再进行尝试匹配,注意,匹配成功的话,A[i] + B[j] = w[i][j]

其实下面这图不符合匈牙利算法的具体过程,由于这里只要理解结果,就拿下面这图了,这里X部+Y部的顶标值 = 对应点的边权值。正确的连接应该是(看上图),B -> c, A -> a,因为根据匈牙利算法所形成的增广路应该是 B -> c -> A -> a, 在这条增广路中只有 A -> c是匹配的,然后取反,就B -> c, A -> a

由于图到此就错了,所以就不继续贴流程图,直接上结果图,具体过程如上重复

下面是以上推荐博客的代码
#include<iostream>
#include<cstring>
#include<cstdio>
#include<vector>
#include<map>
using namespace std;
typedef long long ll;
const int maxn = 300 + 10;
const int INF = 0x3f3f3f3f; int wx[maxn], wy[maxn];//每个点的顶标值(需要根据二分图处理出来)
int cx[maxn], cy[maxn];//每个点所匹配的点
int visx[maxn], visy[maxn];//每个点是否加入增广路
int cntx, cnty;//分别是X和Y的点数
int Map[maxn][maxn];//二分图边的权值
int slack[maxn];//边权和顶标最小的差值 bool dfs(int u)//进入DFS的都是X部的点
{
visx[u] = 1;//标记进入增广路
for(int v = 1; v <= cnty; v++)
{
if(!visy[v] && Map[u][v] != INF)//如果Y部的点还没进入增广路,并且存在路径
{
int t = wx[u] + wy[v] - Map[u][v];
if(t == 0)//t为0说明是相等子图
{
visy[v] = 1;//加入增广路 //如果Y部的点还未进行匹配
//或者已经进行了匹配,可以从原来的匹配反向找到增广路
//那就可以进行匹配
if(cy[v] == -1 || dfs(cy[v]))
{
cx[u] = v;
cy[v] = u;//进行匹配
return 1;
}
}
else if(t > 0)//此处t一定是大于0,因为顶标之和一定>=边权
{
slack[v] = min(slack[v], t);
//slack[v]存的是Y部的点需要变成相等子图顶标值最小增加多少
}
}
}
return false;
} int KM()
{
memset(cx, -1, sizeof(cx));
memset(cy, -1, sizeof(cy));
memset(wx, 0, sizeof(wx));//wx的顶标为该点连接的边的最大权值
memset(wy, 0, sizeof(wy));//wy的顶标为0
for(int i = 1; i <= cntx; i++)//预处理出顶标值
{
for(int j = 1; j <= cnty; j++)
{
if(Map[i][j] == INF)continue;
wx[i] = max(wx[i], Map[i][j]);
}
}
for(int i = 1; i <= cntx; i++)//枚举X部的点
{
memset(slack, INF, sizeof(slack));
while(1)
{ memset(visx, 0, sizeof(visx));
memset(visy, 0, sizeof(visy));
if(dfs(i))break;//已经匹配正确 int minz = INF;
for(int j = 1; j <= cnty; j++)
if(!visy[j] && minz > slack[j])
//找出还没经过的点中,需要变成相等子图的最小额外增加的顶标值
minz = slack[j];
//和全局变量不同的是,全局变量在每次while循环中都需要赋值成INF,每次求出的是所有点的最小值
//而slack数组在每个while外面就初始化好,每次while循环slack数组的每个值都在用到
//在一次增广路中求出的slack值会更准确,循环次数比全局变量更少 //还未匹配,将X部的顶标减去minz,Y部的顶标加上minz
for(int j = 1; j <= cntx; j++)
if(visx[j])wx[j] -= minz;
for(int j = 1; j <= cnty; j++)
//修改顶标后,要把所有不在交错树中的Y顶点的slack值都减去minz
if(visy[j])wy[j] += minz;
else slack[j] -= minz;
}
} int ans = 0;//二分图最优匹配权值
for(int i = 1; i <= cntx; i++)
if(cx[i] != -1)ans += Map[i][cx[i]];
return ans;
}
int n, k;
int main()
{
while(scanf("%d", &n) != EOF)
{
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= n; j++)
scanf("%d", &Map[i][j]);
}
cntx = cnty = n;
printf("%d\n", KM());
}
return 0;
}
匈牙利算法、KM算法的更多相关文章
- 二分图的最大匹配以及带权匹配【匈牙利算法+KM算法】
二分图算法包括 匈牙利算法 与 KM算法. 匈牙利算法 在这里写上模板. 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2063 #include< ...
- 【原创】我的KM算法详解
0.二分图 二分图的概念 二分图又称作二部图,是图论中的一种特殊模型. 设G=(V, E)是一个无向图.如果顶点集V可分割为两个互不相交的子集X和Y,并且图中每条边连接的两个顶点一个在X中,另一个在Y ...
- KM算法详解[转]
KM算法详解 原帖链接:http://www.cnblogs.com/zpfbuaa/p/7218607.html#_label0 阅读目录 二分图博客推荐 匈牙利算法步骤 匈牙利算法博客推荐 KM算 ...
- 二分图匹配--KM算法
Kuhn-Munkres算法 KM算法,求完备匹配下的最大权匹配,时间复杂度O(\(n^3\)) 所谓的完备匹配就是在二部图中,x点集中的所有点都有对应的匹配 且 y点集中所有的点都有对应的匹配 ,则 ...
- 匈牙利算法与KM算法
匈牙利算法 var i,j,k,l,n,m,v,mm,ans:longint; a:..,..]of longint; p,f:..]of longint; function xyl(x,y:long ...
- (转)二分图匹配匈牙利算法与KM算法
匈牙利算法转自于: https://blog.csdn.net/dark_scope/article/details/8880547 匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名 ...
- hdu 2255 奔小康赚大钱--KM算法模板
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2255 题意:有N个人跟N个房子,每个人跟房子都有一定的距离,现在要让这N个人全部回到N个房子里面去,要 ...
- KM算法(二分图的最佳完美匹配)
KM算法大概过程: (1)初始化Lx数组为该boy的一条权值最大的出边.初始化Ly数组为 0. (2)对于每个boy,用DFS为其找到一个girl对象,顺路记录下S和T集,并更新每个girl的slac ...
- KM算法详解+模板
http://www.cnblogs.com/wenruo/p/5264235.html KM算法用来求二分图最大权完美匹配. 本文配合该博文服用更佳:趣写算法系列之--匈牙利算法 现在有N男N女,男 ...
随机推荐
- asp.net webform过滤器(注意我们可以在拦截请求的同时设置回调函数)
.过滤器代码 public class PageFilter : IHttpModule { public String ModuleName { get { return "PageFil ...
- paperfree
主题:免费的论文查重网站 正文:给大家推荐一个免费的论文查重网站PaperFree:http://www.paperfree.cn
- java TimeZone类
TimeZone类主要是对时区的操作 下面是一个简单的例子 public static void main(String[] args) { // TODO Auto-generated method ...
- javascript的那些事儿你都懂了吗
javascript从开始的验证表单的脚本语言发展到现在能运行在服务器上,其影响力不断的提升.自己作为一个做前端的,编写js是必不可少,从自己学习js的历程来看其实也是比较吃力.要 学好它,还是的花费 ...
- C# Timer 用法
System.Timers.Timer,通过.NET Thread Pool实现的,轻量,计时精确,对应用程序.消息没有特别的要求. using Timer = System.Timers.Tim ...
- MFC 错误异常,用vs添加资源并为资源定义类后报错:error C2065 : 未声明的标识符
添加了一个Dialog资源,修改了ID之后右击资源添加了一个类,在类里面有一个成员变量: // 对话框数据 enum { IDD = IDD_GETIN }; 而在编译过程中出现报错,错误代号是 ...
- Linux系统root密码修改
重启系统. 进入系统引导界面: 按下e键: 选择第二项,内核启动参数设置,按下e键: 在结尾处,输入数字 1或者 英文 " single",再回车: 按下b键启动,此时以单用户模式 ...
- Delphi 中调用JS文件中的方法
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- 转载C#中Trim()、TrimStart()、TrimEnd()的用法
C#中Trim().TrimStart().TrimEnd()的用法: 这三个方法用于删除字符串头尾出现的某些字符.Trim()删除字符串头部及尾部出现的空格,删除的过程为从外到内,直到碰到一个 ...
- MVC断点续传
using System;using System.Collections.Generic;using System.Linq;using System.Web;using System.Web.Mv ...