Kafka学习之(一)了解一下Kafka及关键概念和处理机制
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模小打的网站中所有动作流数据。
优势
- 高吞吐量:非常普通的硬件Kafka也可以支持每秒100W的消息,即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持通过Kafka服务器和消费机集群来区分消息,也就是可以对消息进行分类,然后使用不同分类的服务器消费机去消费不同分类的消息。
- 支持Hadoop并行数据加载。
- 以时间复杂度为O(1)的方式提供消息持久化能力,并保证即使对TB级以上数据也能保证常数时间的访问性能
- 支持Kafka Server间的消息分区,及分布式消息消费,同时保证每个partition内的消息顺序传输;producter、broker、consumer均支持水平扩展
- 同时支持离线数据处理和实时数据处理
- 消息持久化,所有的消息均被持久化到磁盘,无消息丢失,支持消息重放
Kafka和其他主流分布式消息系统的对比
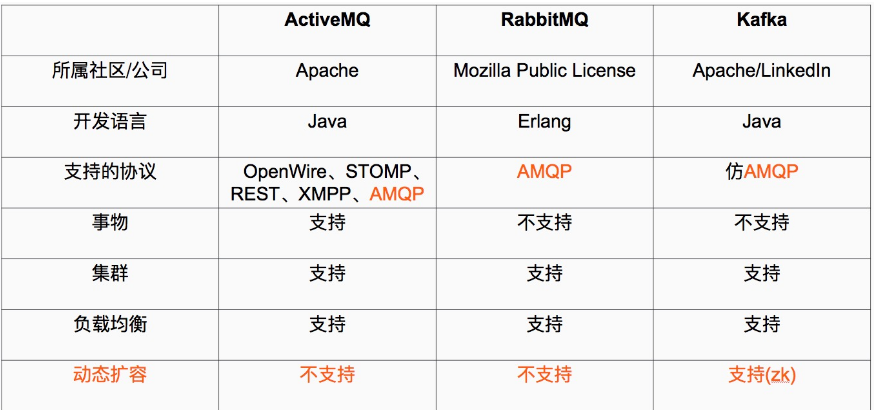
阿里巴巴的Metal,RocketMQ都有Kafka的影子,他们要么改造了Kafka或者借鉴了Kafka,最后Kafka的动态扩容是通过Zookeeper来实现的。
关键概念:
Broker:kafka集群中的一台或者多台服务器统称为broker。
Topic:Kafka处理的消息源(feeds of messages)的不同分类,可以理解为消息分类。
Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。rartition中的每条消息都会被分配一个有序的id(offset)。也就是可以理解为一个群的群名称或者群号,因为大家都在这个群里面消费,成为分类,然后消费topic的时候进行物理分组,比如一个partition不够用,可以分配给多个partition。
Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
Producers:消息和数据的生产者,向Kafka的一个topic发布消息的过程叫做producers。
Consumers:消息和数据消费者,订阅topics并处理其发布的消息过程叫做consumers。
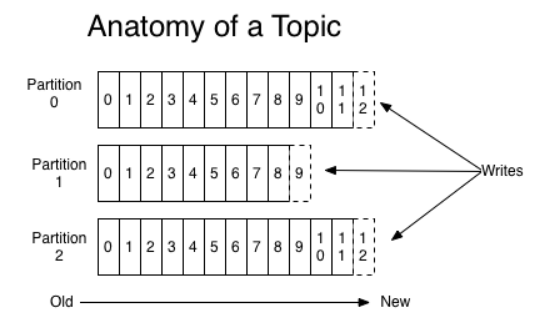
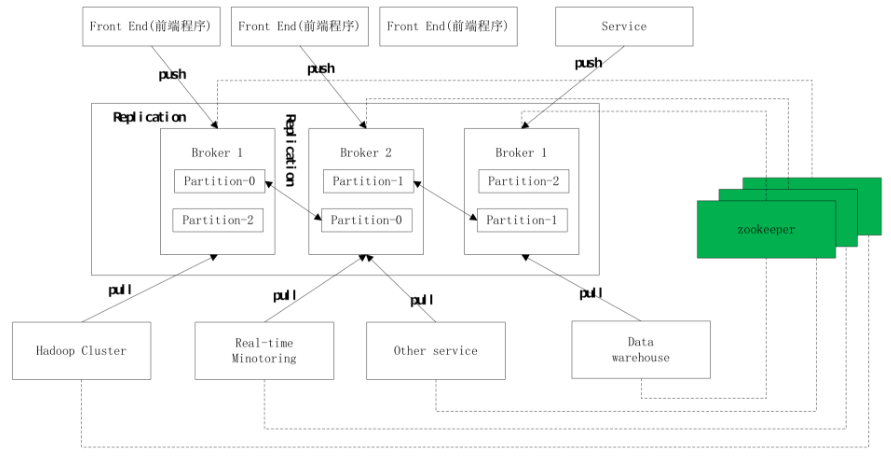
图示说明
最上面的是Producer,也就是消费的生产者,生产好数据之后push到Broker中,也就是Kafka的服务器,push好之后下面有Consumer去消费Kafka的队列,可以看到图中是Consumer去拽Kafka中的消息,然后消费。整体是通过Zookeeper管理。
Kafka学习之(一)了解一下Kafka及关键概念和处理机制的更多相关文章
- kafka学习笔记(四)kafka的日志模块
概述 日志段及其相关代码是 Kafka 服务器源码中最为重要的组件代码之一.你可能会非常关心,在 Kafka 中,消息是如何被保存和组织在一起的.毕竟,不管是学习任何消息引擎,弄明白消息建模方式都是首 ...
- ELK+Kafka学习笔记之搭建ELK+Kafka日志收集系统集群
0x00 概述 关于如何搭建ELK部分,请参考这篇文章,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html. 该篇用户为非root,使用用 ...
- Kafka学习笔记(6)----Kafka使用Producer发送消息
1. Kafka的Producer 不论将kafka作为什么样的用途,都少不了的向Broker发送数据或接受数据,Producer就是用于向Kafka发送数据.如下: 2. 添加依赖 pom.xml文 ...
- Kafka学习笔记(1)----Kafka的简介和Linux下单机安装
1. Kafka简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设计实现上完全不 ...
- 【kafka学习笔记】PHP接入kafka
安装扩展 # 先安装rdkfka库文件 git clone https://github.com/edenhill/librdkafka.git 或者: wget https://gitee.com/ ...
- kafka学习笔记(三)kafka的使用技巧
概述 上一篇随笔主要介绍了kafka的基本使用包括集群参数,生产者基本使用,consumer基本使用,现在来介绍一下kafka的使用技巧. 分区机制 我们在使用 Apache Kafka 生产和消费消 ...
- kafka学习笔记(七)kafka的状态机模块
概述 这一篇随笔介绍kafka的状态机模块,Kafka 源码中有很多状态机和管理器,比如之前我们学过的 Controller 通道管理器 ControllerChannelManager.处理 Con ...
- kafka学习笔记(六)kafka的controller模块
概述 今天我们主要看一下kafka的controller的代码,controller代码是kafka的非常重要的代码,需要我们深入学习.从某种意义上来说,它是kafka最核心的组件,一方面,他要为集群 ...
- kafka学习笔记(五)kafka的请求处理模块
概述 现在介绍学习一下kafka的请求处理模块,请求处理模块就是网络请求处理和api处理,这是kafka无论是对客户端还是集群内部都是非常重要的模块.现在我们对他进行源码深入探讨.当我们说到 Kafk ...
随机推荐
- weX5如何绑定KO对象
define(function(require){ var $ = require("jquery"); var justep = require("$UI/system ...
- 【BZOJ1135】[POI2009]Lyz 线段树
[BZOJ1135][POI2009]Lyz Description 初始时滑冰俱乐部有1到n号的溜冰鞋各k双.已知x号脚的人可以穿x到x+d的溜冰鞋. 有m次操作,每次包含两个数ri,xi代表来了x ...
- 【BZOJ4518】[Sdoi2016]征途 斜率优化
[BZOJ4518][Sdoi2016]征途 Description Pine开始了从S地到T地的征途. 从S地到T地的路可以划分成n段,相邻两段路的分界点设有休息站. Pine计划用m天到达T地.除 ...
- Angular2+ 基本知识汇总
Angular是Google推出的Web前端开发框架,从12年发布起就受到了强烈的关注,他首次提出了双向绑定的概念,让人耳目一新. Angular 2特性 就在2016年9月中旬,时隔4年,Googl ...
- C#全角半角转换输出解决方法
Microsoft.VisualBasic 命名空间 Strings 模块 StrConv 函数就具有大写/小写.全角/半角.中文简体/繁体等转换功能,字符串转换应该说是VB.NET的强项,是这样的: ...
- arcgis server 无法手动删除切片
背景 问题 场景如下: 切片放置在专门的文件服务器上,通过unc共享路径对外共享.文件服务器的OS为windows server2008R2 想手动更新切片服务的切片.发现同一切片服务,有的比例级别文 ...
- 原!mysql存储过程 批量导入数据
mysql需要导入某前缀例如12345为前缀的,后缀扩展2位 即00-99. 利用存储过程插入数据. DROP PROCEDURE IF EXISTS insert_popsms_code;DELIM ...
- 《iOS Human Interface Guidelines》——Popover
弹出框 弹出框是当人们点击一个控件或屏幕上一个区域时显示的一个暂时的界面. API NOTE 在iOS 8及以后的系统中.你能够使用UIPopoverPresentationController来显示 ...
- SQL Server 排名函数
个函数进行的解释. 以下是对这4个函数的解释: RANK() 返回结果集的分区内每行的排名.行的排名是相关行之前的排名数加一. 假设两个或多个行与一个排名关联,则每一个关联行将得到同样的排名. 比如, ...
- pytorch调参经验(一)
个人博客:https://yifdu.github.io/2018/11/18/pytorch%E8%B0%83%E5%8F%82%E7%BB%8F%E9%AA%8C%EF%BC%88%E4%B8%8 ...