教程 | 使用 Apache SeaTunnel 同步本地文件到阿里云 OSS

一直以来,大数据量一直是爆炸性增长,每天几十 TB 的数据增量已经非常常见,但云存储相对来说还是不便宜的。众多云上的大数据用户特别希望可以非常简单快速的将文件移动到更实惠的 S3、OSS 上进行保存,这篇文章就来介绍如何使用 SeaTunnel 来进行到 OSS 的数据同步。
首先简要介绍一下 Apache SeaTunnel,SeaTunnel 专注于数据集成和数据同步,主要解决以下问题:
数据源多样:常用的数据源有数百种,版本不兼容。随着新技术的出现,出现了更多的数据源。用户很难找到能够全面快速支持这些数据源的工具。
复杂同步场景:数据同步需要支持离线-全量同步、离线-增量同步、CDC、实时同步、全库同步等多种同步场景。
资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或 JDBC 连接资源来完成海量小表的实时同步。这在一定程度上加重了企业的负担。
缺乏质量和监控:数据集成和同步过程经常会丢失或重复数据。同步过程缺乏监控,无法直观了解任务过程中数据的真实情况
SeaTunnel 支持海量数据的高效离线/实时同步, 每天可稳定高效同步数百亿级数据,已经有 B 站,腾讯云,微博,360,Shopee 等数百家公司生产使用。
下面步入今天的正题,今天具体来说是讲 Apache SeaTunnel 产品与阿里云 OSS 的集成。
在阿里云 OSS 产品界面,开通 Bucket:
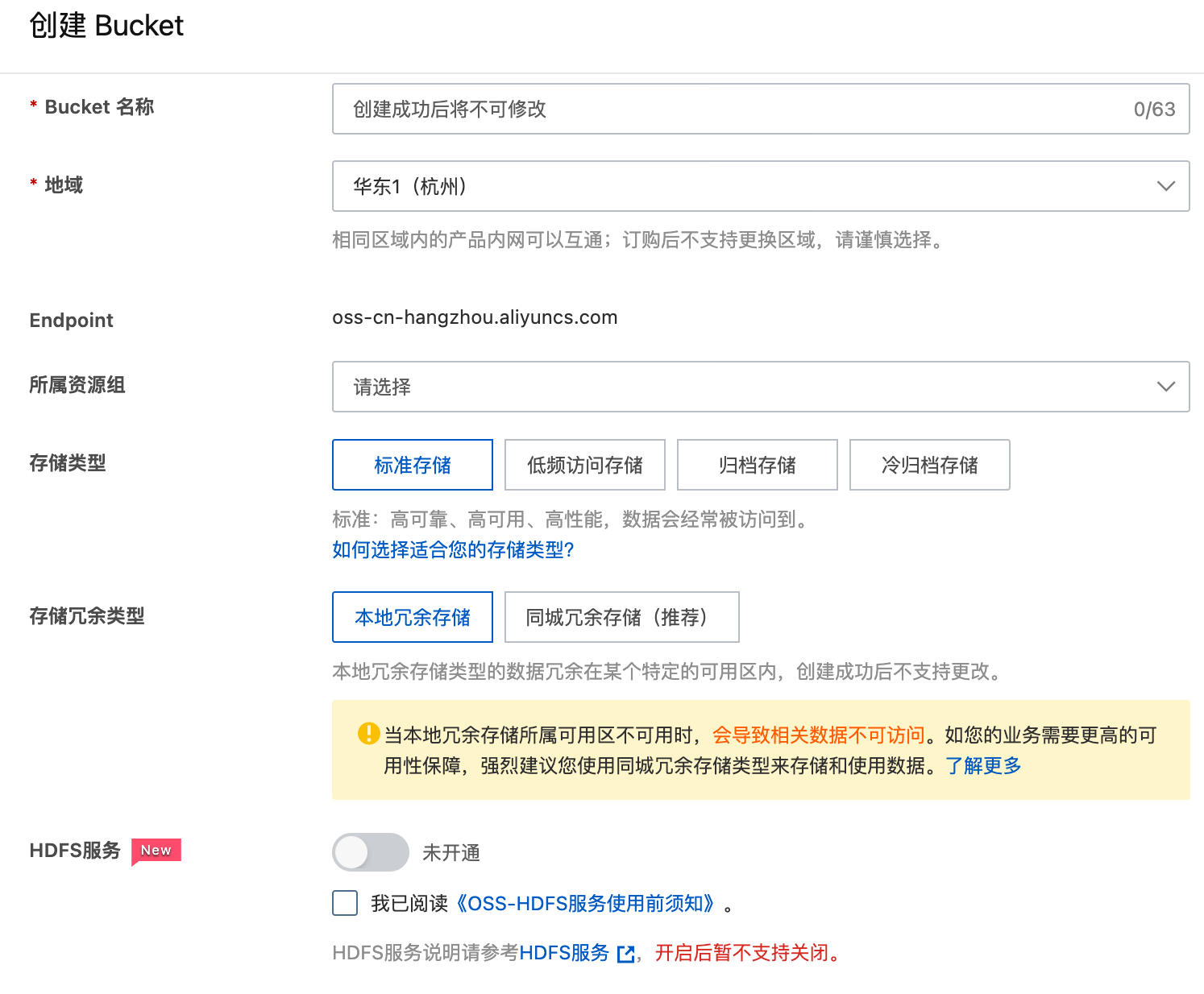
下面是 SeaTunnel 的部署, SeaTunnel 支持多种部署方式: 单机,集群,K8s 等方式。由于 SeaTunnel 不依赖 Zookeeper 等第三方组件,所以整体部署非常简单,具体请参考其官网:https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/deployment
接下来是 SeaTunnel 使用过程,使用命令:
./bin/seatunnel.sh -m local -c ./config/localfile-oss.config
在 SeaTunnel 中,用户可以通过 config 文件定制自己的数据同步需求,最大限度地发挥 SeaTunnel 的潜力。那么接下来就给大家介绍一下如何配置 Config 文件
可以看到,config 文件包含几个部分:env、source、transform、sink。不同的模块有不同的功能。了解这些模块后,您将了解 SeaTunnel 的工作原理。
用于添加一些引擎可选参数,无论是哪个引擎(Spark或Flink),这里都要填写相应的可选参数。
source 用于定义 SeaTunnel 需要从哪里获取数据,并将获取的数据用于下一步。可以同时定义多个源。现在支持的来源检查 SeaTunnel 的来源。每个 Source 都有自己特定的参数来定义如何取数据,SeaTunnel 也提取了每个 source 会用到的参数,比如parameter,用来指定 result_table_name 当前 source 产生的数据的名称,方便供其他模块后续使用。
本例中的 localfile-oss.config 配置文件内容介绍:
env {
# You can set SeaTunnel environment configuration here
execution.parallelism = 10
job.mode = "BATCH"
checkpoint.interval = 10000
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
}
source {
LocalFile {
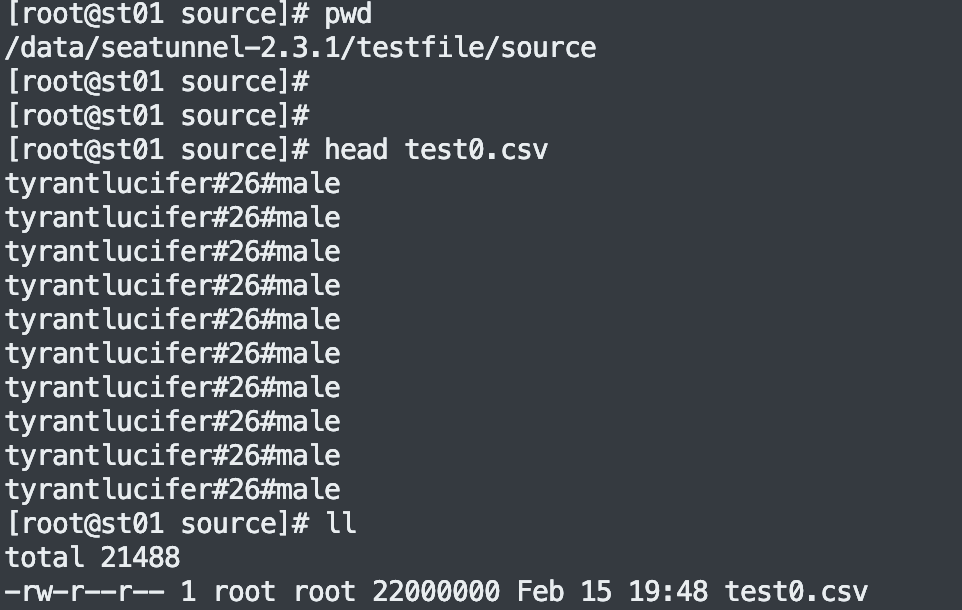
#本地待同步的数据文件夹, 本例子中只有一个 test0.csv 文件,具体内容参考下图
path = "/data/seatunnel-2.3.1/testfile/source"
type = "csv"
delimiter = "#"
schema {
fields {
name = string
age = int
gender = string
}
}
}
}
sink {
OssJindoFile {
path="/seatunnel/oss03"
bucket = "oss://bucket123456654321234.cn-hangzhou.oss-dls.aliyuncs.com"
access_key = "I5t7VZyZSmMNwKsNv1LTADxW"
access_secret = "BinZ9J0zYxRbvG9wQUi6LiUjZElLTA"
endpoint = "cn-hangzhou.oss-dls.aliyuncs.com"
}
}
注:下图本地待同步的数据文件夹, 本例子中只有一个 test0.csv 文件,具体内容
特别注意:如果是开通了 HDFS 的 OSS,有 2 个地方是不一样的:1 是 bucket,1 是 endpoint 。如下红色部分是开通了 HDFS 后的,被 “#” 注释掉的是未开通 HDFS 的情况。
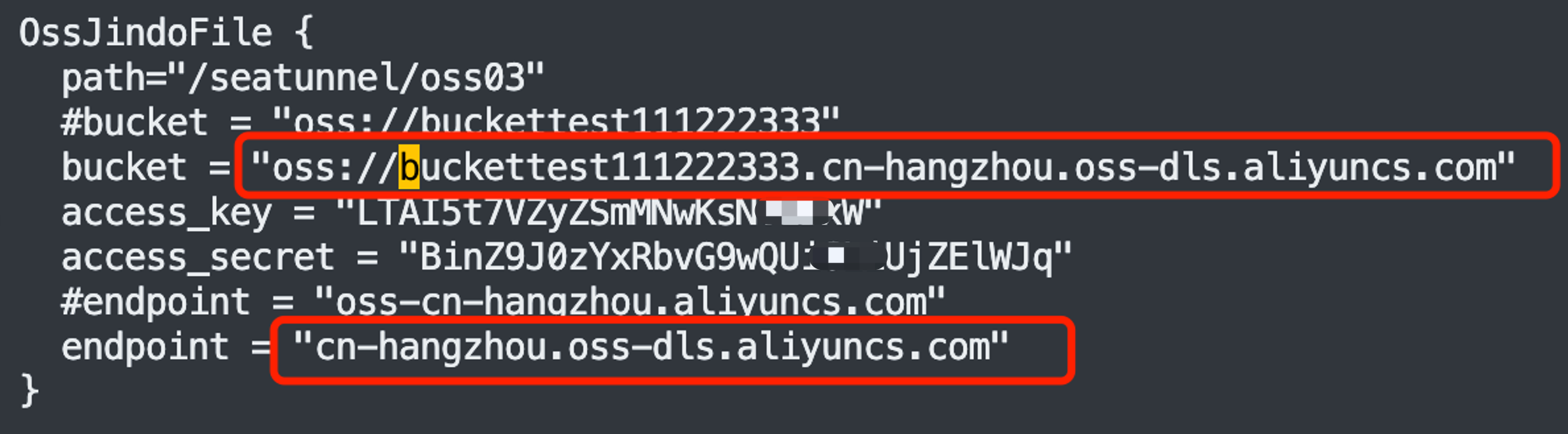
SeaTunnel 对这 2 种情况都是支持的,只是大家要注意一下配置 bucket 和 endpoint 时的不同!
执行运行命令后,我们可以从 SeaTunnel 控制台看下以下 SeaTunnel 本次同步情况的数据:
Job Statistic Information
Start Time : 2023-02-22 17:12:19
End Time : 2023-02-22 17:12:37
Total Time(s) : 18
Total Read Count : 10000000
Total Write Count : 10000000
Total Failed Count : 0
从阿里云界面上可以看到 OSS 端的监控数据:
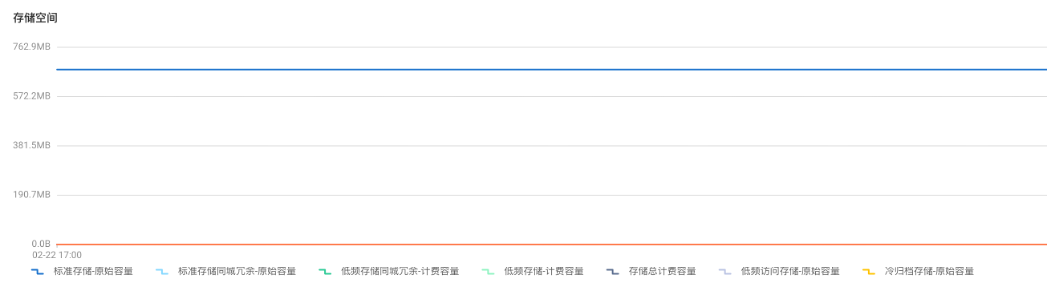
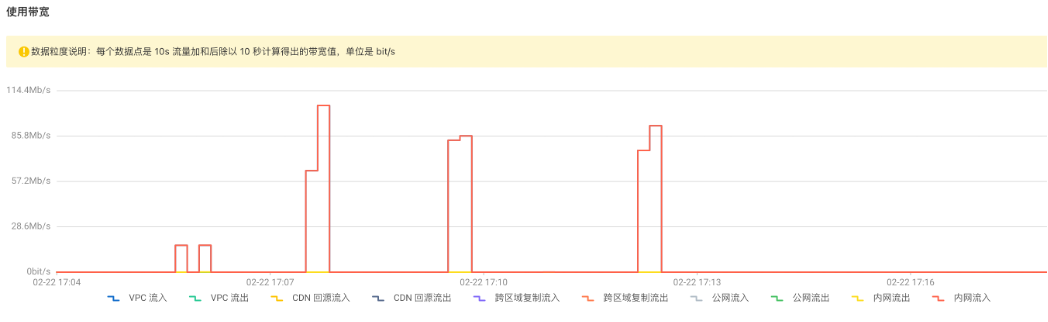
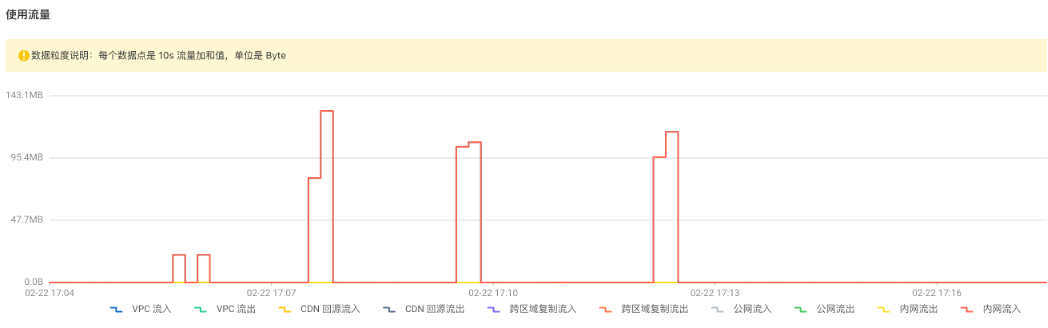
可以看出来 SeaTunnel 快速高效地同步了 1000万数据量的本地文件!
最后,Apache SeaTunnel 目前已经支持了过百种数据源,并发布了 SeaTunnel Zeta 同步引擎,性能巨佳,还有群进行技术支持,欢迎对比,欢迎一试!感兴趣的伙伴欢迎联系社区志愿者微信: seatunnel1
参考:
1、https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/deployment
2、https://seatunnel.apache.org/docs/2.3.0/start-v2/locally/quick-start-seatunnel-engine
3、https://seatunnel.apache.org
本文由 白鲸开源 提供发布支持!
教程 | 使用 Apache SeaTunnel 同步本地文件到阿里云 OSS的更多相关文章
- 关于富文本编辑器ueditor(jsp版)上传文件到阿里云OSS的简单实例,适合新手
关于富文本编辑器ueditor(jsp版)上传文件到阿里云OSS的简单实例,适合新手 本人菜鸟一枚,最近公司有需求要用到富文本编辑器,我选择的是百度的ueditor富文本编辑器,闲话不多说,进入正 ...
- PHP 上传文件至阿里云OSS对象存储
简述 1.阿里云开通对象存储服务 OSS 并创建Bucket 2.下载PHP SDK至框架扩展目录,点我下载 3.码上code 阿里云操作 开通对象存储服务 OSS 创建 Bucket 配置Acces ...
- 上传指定url文件到阿里云oss
好处是不用下载到本地,也不用删除本地文件.省事! 先下载阿里云官方代码 https://github.com/aliyun/aliyun-oss-csharp-sdk 引用其中的 aliyun-os ...
- vue + elementUi + upLoadIamge组件 上传文件到阿里云oss
<template> <div class="upLoadIamge"> <el-upload action="https://jsonpl ...
- 上传文件到阿里云 oss,前端 browser.js 笔记
Web端常见的上传方法是用户在浏览器或App端上传文件到应用服务器,应用服务器再把文件上传到OSS. 和数据直传到OSS相比,有以下缺点 上传慢:用户数据需先上传到应用服务器,之后再上传到OSS 费用 ...
- php调接口批量同步本地文件到cos或者oss
代码: <?php namespace Main\Controller; use Common\Library\Vendor\ElasticSearch; use Common\Library\ ...
- koa中上传文件到阿里云oss实现点击在线预览和下载
比较好的在线预览的方法: 跳转一个新的页面,里面放一个iframe标签,或者object标签 <iframe src="xxx"></iframe> < ...
- PHP上传文件到阿里云OSS,nginx代理访问
1. 阿里云OSS创建存储空间Bucket(读写权限为:公共读) 2. 拿到相关配置 accessKeyId:********* accessKeySecret:********* endpoint: ...
- Typora配置本地图片自动上传阿里云OSS
一.下载Typora Gitee下载地址 二.下载Picgo.app Github下载地址 三.配置Picgo 打开Typora,格式→图像→图像全局设置: 四.图床设置 注册阿里云账号 打开 ...
- 第2-3-3章 文件处理策略-文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss
目录 5.2 文件处理策略 5.2.1 FileStrategy 5.2.2 AbstractFileStrategy 5.2.3 LocalServiceImpl 5.2.4 FastDfsServ ...
随机推荐
- 简约博客新主题Sina上线 - 魔改新浪
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` 简约博客新主题Sina上线 - 魔改新浪 日期:2018- ...
- 内网服务器通过单台外网服务器实现外网访问,iptables NAT
环境: servera: 外网服务器 serverb: 内网服务器 servera内网网关(GATEWAY)要设置为外网IP,其IP地址作为其它内网服务器的网关 servera 内网网卡配置 ...
- [翻译].NET 8 的原生AOT及高性能Web开发中的应用[附性能测试结果]
原文: [A Dive into .Net 8 Native AOT and Efficient Web Development] 作者: [sharmila subbiah] 引言 随着 .NET ...
- 04-Python文件操作
打开文件 f=open("我的文件.txt","r",encoding="utf8") #打开一个文件(读模式) f.close() #关闭 ...
- Chrome插件:Vue.js Devtools 高效地开发和调试
在现代前端开发中,Vue.js因其灵活性和性能优势,受到越来越多开发者的青睐.然而,随着项目规模的扩大,调试和优化变得愈发复杂.幸运的是,Vue.js Devtools的出现,为开发者提供了一套强 ...
- 在WPF中使用WriteableBitmap对接工业相机及常用操作
写作背景 写这篇文章主要是因为工业相机(海康.大恒等)提供的.NET开发文档和示例程序都是用WinForm项目来说明举例的,而在WPF项目中对图像的使用和处理与在WinForm项目中有很大不同.在Wi ...
- docker部署微服务之注册中心
1.首先要对对应服务的pom.xml文件进行修改,添加如下配置. 2.在微服务的pom.xml目录下建立Dockerfile文件 3.在Dockerfile当前目录下执行mvn clean insta ...
- Linux 应用案例开发手册——基于Zynq-7010/20工业开发板
目 录 1 开发案例说明 4 2 Linux 常用开发案例 4 2.1 tl_led_flash 案例 4 2.2 tl_key_test 案例 7 2.3 tl_can_echo 案例 11 2.4 ...
- VulnHub-DC-8渗透流程
DC-8 kali:192.168.157.131 靶机:192.168.157.152 信息收集 SQL注入 Drupal 7是有sql注入漏洞的,这里也能看到?nid=1,那测试一下?nid=1' ...
- SpringBoot集成Knife4j
Knife4j简介 Knife4j 官网地址:https://doc.xiaominfo.com/ knife4j 是为Java MVC框架集成Swagger生成Api文档的增强解决方案. Knife ...