hdfs disk balancer 磁盘均衡器
1、背景
在我们的hadoop集群运行一段过程中,由于多种原因,数据在DataNade的磁盘之间的分布可能是不均匀。比如: 我们刚刚给某个DataNode新增加了一块磁盘或者集群上存在大批量的write & deltete操作等灯。那么有没有一种工具,能够使单个DataNode中的多个磁盘的数据均衡呢?借助Hadoop提供的Diskbalancer命令行工具可以实现。
2、hdfs balancer和 hdfs disk balancer有何不同?
hdfs balancer: 是为了集群中DataNode的数据均衡,即针对多个DataNode的。
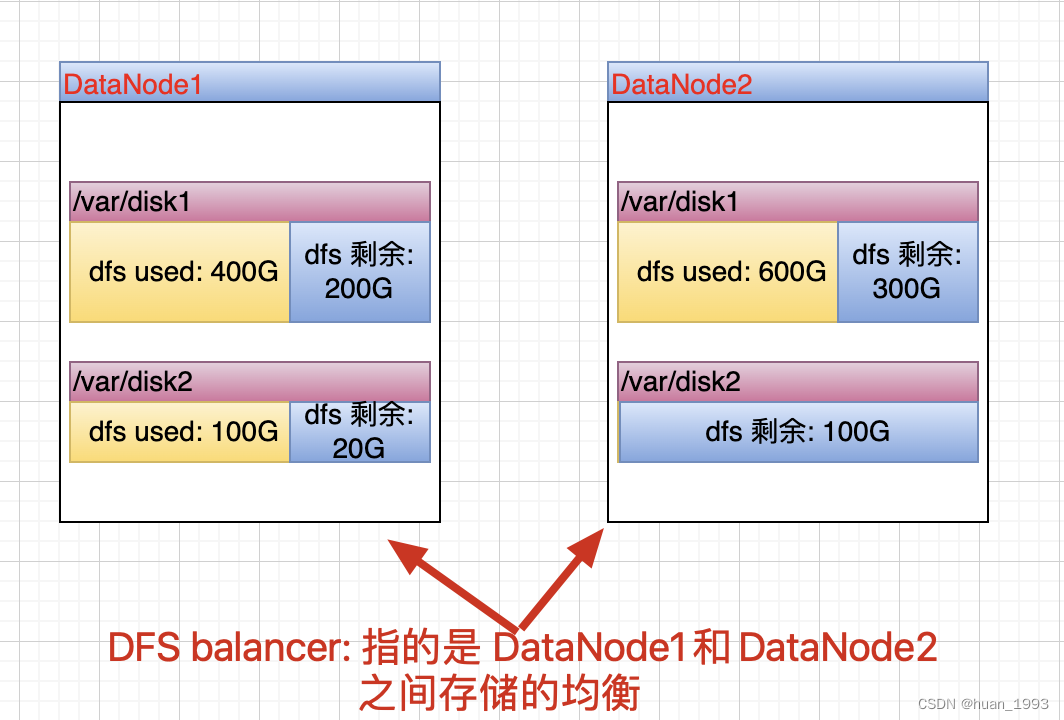
hdfs disk balancer: 是为了使单台DataNode中的多个磁盘中的数据均衡。
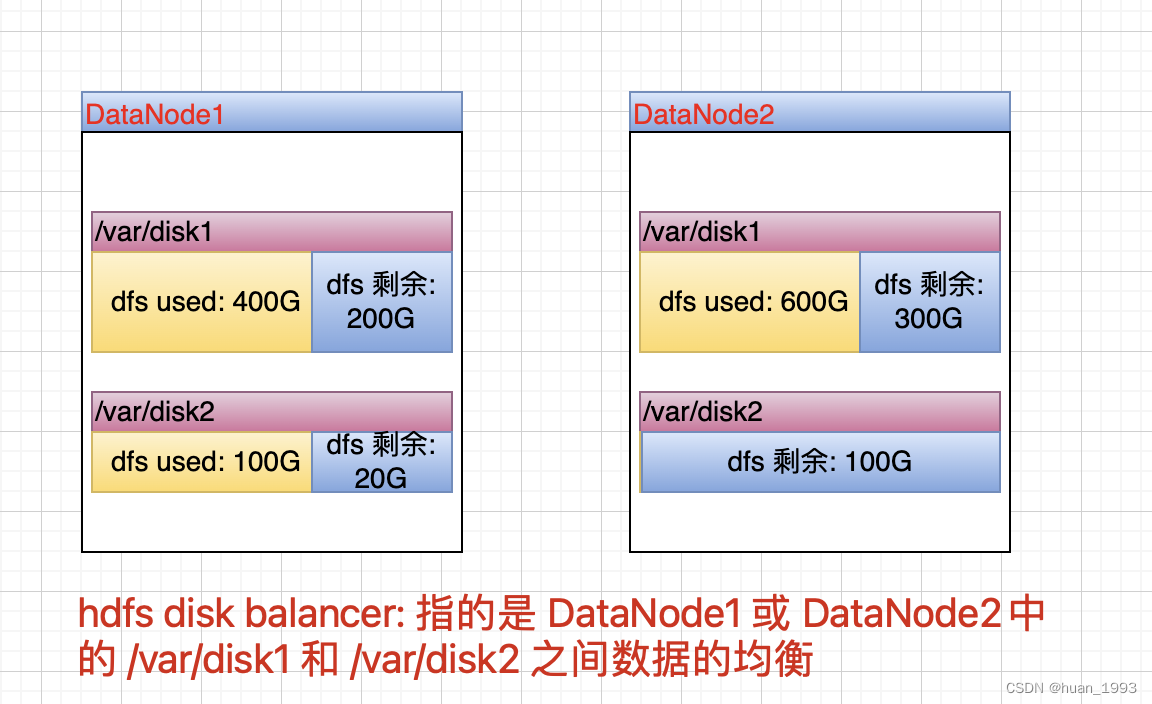
注意: 目前DiskBalancer不支持跨存储介质(SSD、DISK等)的数据转移,所以磁盘的均衡都是要求在一个storageType下的。因为hdfs中存在异构存储。
3、操作
3.1 生成计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -plan hadoop01 -out hadoop01-plan.json
-plan: 后面接的是主机名。
-out: 指定计划文件的输出位置。

3.2 执行计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -execute hadoop01-plan.json

3.3 查询计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -query hadoop01
-query 后面跟的是 主机名

3.4 取消计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -cancel hadoop01-plan.json

4、和disk balancer相关的配置
| 配置 | 描述 |
|---|---|
dfs.disk.balancer.enabled |
此参数控制是否为集群启用diskbalancer。如果未启用,任何执行命令都将被DataNode拒绝。默认值为true。 |
dfs.disk.balancer.max.disk.throughputInMBperSec |
这控制了diskbalancer在复制数据时消耗的最大磁盘带宽。如果指定了10MB之类的值,则diskbalancer平均只会复制10MB/S。默认值为10MB/S。 |
dfs.disk.balancer.max.disk.errors |
设置能够容忍的在指定的移动过程中出现的最大错误次数,超过此阈值则失败。例如,如果一个计划有3对磁盘要在其中复制,并且第一个磁盘集遇到超过5个错误,那么我们放弃第一个副本并启动计划中的第二个副本。最大错误的默认值设置为5。 |
dfs.disk.balancer.block.tolerance.percent |
设置磁盘之间进行数据均衡操作时,各个磁盘的数据存储量与理想状态之间的差异阈值。取值范围[1-100],默认为10。例如,各个磁盘的理想数据存储量为100 GB,此参数设置为10。那么,当目标磁盘的数据存储量达到90 GB时,则认为该磁盘的存储状态就已经达到预期。 |
dfs.disk.balancer.plan.threshold.percent |
设置在磁盘数据均衡中可容忍的两磁盘之间的数据密度域值差,取值范围[1-100],默认为10。如果任意两个磁盘数据密度差值的绝对值超过了阈值,则说明需要对该的磁盘进行数据均衡。例如,如果一个2盘节点上的总数据为100 GB,那么磁盘均衡器计算每个磁盘上的期望值为50 GB。如果容差为10%,则单个磁盘上的数据需要大于60 GB(50 GB + 10%容差值),DiskBalancer才能开始工作。 |
dfs.disk.balancer.plan.valid.interval |
磁盘平衡器计划有效的最大时间。支持以下后缀(不区分大小写):ms(milis)、s(sec)、m(min)、h(h)、d(day)以指定时间(例如2s、2m、1h等)。如果未指定后缀,则假定为毫秒。默认值为1d |
5、额外知识点
5.1 新的block存储到那个磁盘(卷)中
当数据写入新的block时,DataNode会根据策略选择不同的磁盘来存储。
循环策略: 默认策略,将新的块均匀的分布在可用的磁盘上,可能造成数据倾斜。
可用空间策略: 选择更多可用空间(按百分比)的磁盘。可能造成在某段时间内,某个磁盘的IO压力变大。
5.2 磁盘数据密度度量标准

上图来自 https://www.bilibili.com/video/BV11N411d7Zh/?p=81
6、参考文档
1、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSDiskbalancer.html
2、https://help.aliyun.com/document_detail/467585.html
3、https://www.bilibili.com/video/BV11N411d7Zh/?p=81
hdfs disk balancer 磁盘均衡器的更多相关文章
- Azure ARM (18) 将Azure RM Manage Disk托管磁盘的Image,跨订阅迁移
<Windows Azure Platform 系列文章目录> 先挖一个坑,以后再埋. 最近遇到一个客户需求,客户使用了Azure RM Manage Disk托管磁盘,然后捕获镜像做成了 ...
- hdfs的balancer
参考: https://blog.csdn.net/mnasd/article/details/80369603 在CDH中选一个资源多的节点,安装 HDFS->添加角色到实例 启动后状态是灰的 ...
- CDH版HDFS Block Balancer方法
命令: sudo -u hdfs hdfs balancer 默认会检查每个datanode的磁盘使用情况,对磁盘使用超过整个集群10%的datanode移动block到其他datanode达到均衡作 ...
- Disk:磁盘管理之LVM和系统磁盘扩容
简介 小伙伴们好,好久不见,今天想给大家介绍一下关于磁盘管理的方法和心得:磁盘管理可谓运维工作中的重要内容,主要包括磁盘的合理规划以及扩缩容 常用的磁盘管理方法为LVM(Logical Volume ...
- Acronis.Disk.Director磁盘分区管理
Acronis.Disk.Director分为for 专业版和服务器版的,我在生产环境中调整Windows2003跳板机使用的是Acronis.Disk.Director Server 10.0.20 ...
- HDFS数据平衡
一.datanode之间的数据平衡 1.1.介绍 Hadoop 分布式文件系统(Hadoop Distributed FilSystem),简称 HDFS,被设计成适合运行在通用硬件上的分布式文件 ...
- Hadoop常见重要命令行操作及命令作用
关于Hadoop [root@master ~]# hadoop --help Usage: hadoop [--config confdir] COMMANDwhere COMMAND is one ...
- CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式)
@ 目录 前言 预先设置 修改主机名 关闭防火墙 创建hadoop用户 SSH安装免密登陆 单机免密登陆--linux配置ssh免密登录 linux环境配置Java变量 配置Java环境变量 安装Ha ...
- 运用ASMIOSTAT脚本监控asm disk磁盘性能
1,脚本作用: 类似于OS的iostat检查磁盘的I/O性能,ASMIOSTAT 脚本用来检查ASM磁盘的性能, 2,下载AMSIOSTAT脚本http://files.cnblogs.com/fil ...
- Hadoop Balancer源代码解读
前言 近期在做一些Hadoop运维的相关工作,发现了一个有趣的问题,我们公司的Hadoop集群磁盘占比数值參差不齐,高的接近80%.低的接近40%.并没有充分利用好上面的资源,可是balance的操作 ...
随机推荐
- JS Leetcode 451. 根据字符出现频率排序题解分析
壹 ❀ 引 大前天做的一道题,昨天发版到11点,前天聚餐,一直没时间整理,今天下班闲来无事,还是做个简单思路整理.本题来自LeetCode 451. 根据字符出现频率排序,难度中等,其实整理下思路,其 ...
- 从零开始手写 mybatis(四)- mybatis 事务管理机制详解
前景回顾 第一节 从零开始手写 mybatis(一)MVP 版本 中我们实现了一个最基本的可以运行的 mybatis. 第二节 从零开始手写 mybatis(二)mybatis interceptor ...
- 《深入理解JAVA虚拟机》(一) JVM 结构 + 栈帧 详解
1.程序计数器(Program Counter Register) 线程独有,每个线程都有自己的计数器:由于CPU的任意时刻只能执行所有线程中的一条,所以需要使用程序计数器来支持J ...
- 跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA) 介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材.中医各 ...
- leetcode - 中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 . 示例 1: 输入:root = [1,null,2,3] 输出:[1,3,2] 示例 2: 输入:root = [] 输出:[] 示例 ...
- python字符串模板文本处理之Template
from string import Template s = Template('$who 在 $do') ts = s.substitute(who="张三", do=&quo ...
- 【防忘笔记】一个例子理解Pytorch中一维卷积nn.Conv1d
一维卷积层的各项参数如下 torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1 ...
- 名校 AI 课程|斯坦福 CS25:Transformers United 专题讲座
自 2017 年提出后,Transformer 名声大噪,不仅颠覆了自然语言处理(NLP)领域,而且在计算机视觉(CV).强化学习(RL).生成对抗网络(GANs).语音甚至是生物学等领域也大显锋芒, ...
- 【Azure 媒体服务】使用编码预设文件(Preset.json)来自定义编码任务 -- 创建视频缩略图
问题描述 在Azure门户上创建Transform Encoding时候,只能选择 Built-in Preset 编码方式(如:H265ContentAwareEncoding) 在创建编码任务时, ...
- 云原生基础设施实践:NebulaGraph 的 KubeBlocks 集成故事
像是 NebulaGraph 这类基础设施上云,通用的方法一般是将线下物理机替换成云端的虚拟资源,依托各大云服务厂商实现"服务上云".但还有一种选择,就是依托云数据基础设施,将数据 ...