Sqoop简介安装及使用
Sqoop简介
sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。
核心的功能有两个:
导入、迁入
导出、迁出
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论。
sqoop:
工具:本质就是迁移数据, 迁移的方式:就是把sqoop的迁移命令转换成MR程序
hive
工具,本质就是执行计算,依赖于HDFS存储数据,把SQL转换成MR程序
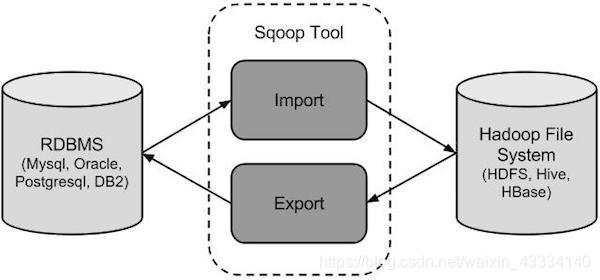
将导入或导出命令翻译成 MapReduce 程序来实现 在翻译出的 MapReduce 中主要是对 InputFormat 和 OutputFormat 进行定制
Sqoop安装
一、安装部署
(1)、下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.7/
解压到/opt/cdh5/sqoop
(2)、拷贝MySQL的jdbc驱动包mysql-connector-Java-5.1.31-bin.jar到sqoop/lib目录下。
(3)、配置环境变量
#sqoop
export SQOOP_HOME=/opt/cdh5/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
(4)、复制sqoop/conf/sqoop-env-template.sh为sqoop-env.sh
添加相关的配置
#Setpath to where bin/Hadoop is available
exportHADOOP_COMMON_HOME=/opt/cdh5/hadoop
#Setpath to where hadoop-*-core.jar isavailable
exportHADOOP_MAPRED_HOME=/opt/cdh5/hadoop
#setthe path to where bin/Hbase isavailable
exportHBASE_HOME=/opt/cdh5/hbase
#Setthe path to where bin/Hive is available
exportHIVE_HOME= /opt/cdh5/hive
#Setthe path for where zookeper config diris
exportZOOCFGDIR= /opt/cdh5/zookeeper
(5)、测试Sqoop
sqoop version
测试之前先测试mysql能不能远程连接
Sqoop语法
导入hdfs
Sqoop import
--connect jdbc:mysql://192.168.104.200:3306/database (连接数据库的IP地址 、指定数据库)
--username root (mysql用户名)
--password root (mysql密码)
--table user (表名)
--columns “id,name”(指定需要查找的列)
--where “id >3” (条件)
--fields-terminated-by “\t” (列间隔)
--split-by id (以哪个字段分割)
--query ‘select id,name from user where $CONDITIONS and id >3’ (也可直接写查询语句,写条件语句时必须写$CONDITIONS ,查询语句外必须用单引号,否则得在$之前加转义字符 \)
--delete-target-dir (删除掉存在的路径)
--target-dir /hdfs (写入hdfs的路径)
-m 1 (开启几个maptask任务)
增量导入
Sqoop import
--connect jdbc:mysql://192.168.104.200:3306/database (连接数据库的IP地址 、指定数据库)
--username root (mysql用户名)
--password root (mysql密码)
--table user
--incremental append (追加)
--check-column order_date (根据哪一列)
--last-value ‘2018-11-12’ (大于这个日期的追加)
--target-dir /hdfs
--m 1
导入hive
先将hive-common-2.3.2.jar 导入sqoop的lib下
Sqoop import
--connect jdbc:mysql://192.168.104.200:3306/database (连接数据库的IP地址 、指定数据库)
--username root (mysql用户名)
--password root (mysql密码)
--table user
--hive-import (指定导入hive)
--fields-terminated-by “\t”
--lines-terminated-by “\n”
--hive-overwrite
--create-hive-table
--delete-target-dir
--hive-database (指定导入hive的哪个数据库)
--hive-table (默认和mysql的表名一样)
--target-dir /hdfs
--check-column uid
--last-value 2
-m 1
导出export
Sqoop export
--connect ‘jdbc:mysql://192.168.104.200:3306/database?useUnicode=true&characterEncoding=utf-8’ (连接数据库的IP地址 、指定数据库、指定编码格式)
--username root (mysql用户名)
--password root (mysql密码)
--export-dir /hive/warehouse/userinfo/part-m-00000 (指定导出的hdfs路径)
--table userinfo
-input-fields-terminated-by “,”(指定导出的字段间隔,必须是逗号)
因为sqoop1不支持导入hbse,可以先导入hdfs,然后执行批量导入的命令导入hbase
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=, -Dimporttsv.columns="HBASE_ROW_KEY,info:name,order:no,order:date" customer /input/hbase/hbase_import_data.csv
Sqoop简介安装及使用的更多相关文章
- Sqoop 简介与安装
一.Sqoop 简介 Sqoop是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出: 导入数据:从MySQL,Oracle等关系型数据库中导入数据到HDFS.Hive.HBase ...
- 入门大数据---Sqoop简介与安装
一.Sqoop 简介 Sqoop 是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出: 导入数据:从 MySQL,Oracle 等关系型数据库中导入数据到 HDFS.Hive.H ...
- Hadoop 2.6.0-cdh5.4.0集群环境搭建和Apache-Hive、Sqoop的安装
搭建此环境主要用来hadoop的学习,因此我们的操作直接在root用户下,不涉及HA. Software: Hadoop 2.6.0-cdh5.4.0 Apache-hive-2.1.0-bin Sq ...
- sqoop的安装
Sqoop是一个用来完成Hadoop和关系型数据库中的数据相互转移的工具, 他可以将关系型数据库(MySql,Oracle,Postgres等)中的数据导入Hadoop的HDFS中, 也可以将HDFS ...
- Spark简介安装和简单例子
Spark简介安装和简单例子 Spark简介 Spark是一种快速.通用.可扩展的大数据分析引擎,目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL.Spark S ...
- Hive/Hbase/Sqoop的安装教程
Hive/Hbase/Sqoop的安装教程 HIVE INSTALL 1.下载安装包:https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3 ...
- Sqoop的安装及简单使用
SQOOP是用于对数据进行导入导出的. (1)把MySQL.Oracle等数据库中的数据导入到HDFS.Hive.HBase中 (2)把HDFS.Hive.HBase中的数据导出到MySQL.Or ...
- Sqoop的安装配置及使用
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- Python 3 mysql 简介安装
Python 3 mysql 简介安装 一.数据库是什么 1. 什么是数据库(DataBase,简称DB) 数据库(database,DB)是指长期存储在计算机内的,有组织,可共享的数据的集合.数据 ...
- Sqoop环境安装
环境下载 首先将下载的 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz放到 /usr/hadoop/目录下(该目录可以自定义,一般为Hadoop集群安装目录),然 ...
随机推荐
- 机器学习:详解是否要使用端到端的深度学习?(Whether to use end-to-end learning?)
详解是否要使用端到端的深度学习? 假设正在搭建一个机器学习系统,要决定是否使用端对端方法,来看看端到端深度学习的一些优缺点,这样就可以根据一些准则,判断的应用程序是否有希望使用端到端方法. 这里是应用 ...
- sql语句排序无效的问题
数据可视化时因为数据类型排序无效的问题:这是由于你要排序的类型是String类型的而ORDER BY 方法排序要求整数型. 这就需要在ORDER BY 后加 CAST(需要排序的字段 AS UNSIG ...
- vue3 + ts 中出现 类型“typeof import(".........../node_modules/vue/dist/vue")”的参数不能赋给类型“Component<any, any, any, ComputedOptions, MethodOptions>”的参数。
错误示例截图 解决方法 修改shims-vue.d.ts中的内容 declare module "*.vue" { import { defineComponent } from ...
- 【Nexus】Linux上的Maven私服搭建
[1.安装Nexus] 需要Linux安装JDK运行,Nexus2版本JDK7,3版本JDK8 首先需要Nexus服务器文件 nexus-2.12.0-01-bundle.tar.gz 解压 tar ...
- 【Spring-Mail】
需要的pom依赖: <dependency> <groupId>org.springframework</groupId> <artifactId>sp ...
- 什么样的AI计算框架才是受用户喜欢的?
说明,本文是个人的一些胡想. 背景: AI计算框架现在从国外的百家争鸣过度到了国内百家争鸣的局面了.在7.8年前的时候,国外的AI计算框架简直是数不胜数,从14.15年前Nvidia公司的显卡需要手动 ...
- 对国产AI计算框架要有一定的包容力——记“mindspore”使用过程中的“不良反应”
看mindspore的官方文档,居然有502错误,恶心到了: 打开Eager模式的链接,报错:
- 推荐一款.NET开源、功能强大的二维码生成类库
前言 在日常开发需求中,生成二维码以分享文本内容或跳转至指定网站链接等场景是比较常见的.今天大姚给大家分享一款.NET开源(MIT License).免费.简单易用.功能强大的二维码生成类库:QrCo ...
- 恭喜社区迎来新PMC成员!
恭喜Apache SeaTunnel社区又迎来一位PMC Member@liugddx!在社区持续活跃的两年间,大家经常看到这位开源爱好者出现在社区的各种活动中,为项目和社区发展添砖加瓦.如今成为项目 ...
- Java学习笔记1--JDK,JRE和JVM
1.Java开发环境 Java开发环境是指Java程序员开发.编写.测试和调试Java程序所使用的所有工具和技术.Java开发环境通常由以下几个部分组成: JDK(Java Development K ...