抢占GPU的脚本
前言
同样的,这篇博客也源自于我在做组内2030项目所产生的结果。当时,5个硕士生需要进行类似的微调工作,偶尔还会有博士生使用服务器上的GPU,但服务器上仅有8块GPU。
因此,如何快速抢占到 \(n\) 块GPU,从而高效完成手里的工作,便是一个很重要的问题啦~^ _ ^
问题
我首先在网上看了下现有的抢GPU的脚本,但发现简单的脚本要么只能抢1块GPU,要么是一个复杂项目操作起来较麻烦。
于是便萌生了自己写个Python脚本,这样以后凡是涉及到需要抢GPU的场景,我都可以通过运行该脚本抢占到 \(n\) 块GPU后,便开始我的模型训练或是其他。
这样一种一劳永逸的工作,何乐而不为呢?
闲话少叙,下面开始介绍实现方法。
解决方法
我主要利用Python多进程编程,通过占用GPU内存,从而达到占用GPU的目的。关于代码的解释以及整个完成过程详见我的个人博客,以下主要介绍如何使用该脚本。
我的Python版本为3.11,执行命令如下
python grab_gpu.py --n 3 --otime 30 --spath ./train.sh
其中n表示需要占用的GPU个数,otime表示占用时间,spath表示一旦释放GPU后,我们需要执行的脚本。
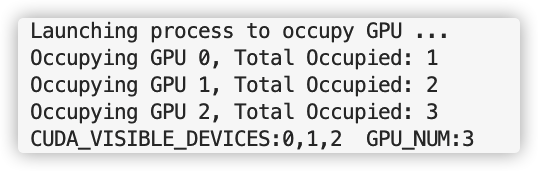
运行结果如下:
完整代码如下
import os
import subprocess
import time
import argparse
from multiprocessing import Process, Value, Lock, Array
def get_gpu_mem(gpu_id):
gpu_query = subprocess.check_output(['nvidia-smi', '--query-gpu=memory.used', '--format=csv,nounits,noheader'])
gpu_memory = [int(x) for x in gpu_query.decode('utf-8').split('\n')[:-1]]
return gpu_memory[gpu_id]
def get_free_gpus()->list:
gpu_query = subprocess.check_output(['nvidia-smi', '--query-gpu=memory.used', '--format=csv,nounits,noheader'])
gpu_memory = [int(x) for x in gpu_query.decode('utf-8').split('\n')[:-1]]
free_gpus = [i for i, mem in enumerate(gpu_memory) if mem < 100]
return free_gpus
def occupy_gpu(gpu_id:int, n, occupy_num, ocpy_gpus, lock, a_dim=140000):
with lock:
if get_gpu_mem(gpu_id) < 100 and occupy_num.value < n:
import torch
a = torch.ones((a_dim,a_dim)).cuda(gpu_id)
ocpy_gpus[occupy_num.value]= gpu_id
occupy_num.value += 1
print(f"Occupying GPU {gpu_id}, Total Occupied: {occupy_num.value}")
while True:
time.sleep(10)
def occupy_all_gpus(n:int, occupy_num, ocpy_gpus, interval=10):
print("Launching process to occupy GPU ...")
lock = Lock()
processes = [] #List to store the processes
while occupy_num.value < n:
free_gpus = get_free_gpus()
will_occupy_num = min(n, max(0,len(free_gpus)))
for i in range(will_occupy_num):
if occupy_num.value < n:
p = Process(target=occupy_gpu, args=(free_gpus[i], n, occupy_num, ocpy_gpus, lock))
p.start()
processes.append(p)
time.sleep(interval) # enough time to occupy gpus and update nvidia-smi
return processes, ocpy_gpus
def run_my_program(n, desired_script, processes, ocpy_gpus, occupy_num):
for p in processes:
p.terminate()
ocpy_gpus_list = list(ocpy_gpus[:occupy_num.value])
cuda_visible_devices = ",".join(map(str, ocpy_gpus_list))
os.environ['CUDA_VISIBLE_DEVICES'] = cuda_visible_devices
subprocess.run([desired_script, str(n)])
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Arguments for Occupy GPUs")
parser.add_argument(
"--n", type=int, default=2, help="Number of GPUs to occupy"
)
parser.add_argument(
"--otime", type=int, default=10, help="Time of occupying gpu"
)
parser.add_argument(
"--spath", type=str, default='./train.sh', help="the execute script path"
)
args = parser.parse_args()
n = args.n
occupy_time = args.otime
desired_script = args.spath
occupy_num = Value('i', 0) # Shared variable to count occupied GPUs
ocpy_gpus = Array('i', [-1 for _ in range(8)])# Shared array to store occupied gpu
processes,ocpy_gpus = occupy_all_gpus(n, occupy_num, ocpy_gpus)
time.sleep(occupy_time)
run_my_program(n, desired_script, processes, ocpy_gpus, occupy_num)
抢占GPU的脚本的更多相关文章
- ubuntu12.04通过Ganglia利用NVML模块进行GPU监控
1.安装Ganglia,这里安装的是3.1*版本,因为监控GPU的模块只支持3.1*版本系列的 apt-get install ganglia* 2.下载并安装PyNVML和NVML模块,下载地址ht ...
- 谁在使用GPU?
nvidia-smi命令可以查看GPU使用情况,但是只能看到占用每个GPU的进程ID.根据进程ID可以得到进程详情,进程详情中包括用户ID,根据用户ID可以获取用户名称,从而知道哪个用户在使用GPU. ...
- keepalived 配置文件参数详解
global_defs 全局配置vrrpd 1. vrrp_script添加一个周期性执行的脚本.脚本的退出状态码会被调用它的所有的VRRP Instance记录. 2. vrrp_sync_grou ...
- Ogre 整体框架入门
ogre 是面向对象的3d图形引擎. root 是引擎的一个界面类,包含很多快捷的调用其他类的接口. 在ogre中,广泛的使用了单件模式,同时最大的保证了你不需要自己管理资源,除了是你自己new的对象 ...
- Keepalived+nginx高可用
这种方法会把Keepalived进程结束掉,在教育机构学习到的方法,我个人对这种方法不认可. 参考: https://www.cnblogs.com/gshelldon/p/14504236.html ...
- 从 PyTorch DDP 到 Accelerate 到 Trainer,轻松掌握分布式训练
概述 本教程假定你已经对于 PyToch 训练一个简单模型有一定的基础理解.本教程将展示使用 3 种封装层级不同的方法调用 DDP (DistributedDataParallel) 进程,在多个 G ...
- [转]各种移动GPU压缩纹理的使用方法
介绍了各种移动设备所使用的GPU,以及各个GPU所支持的压缩纹理的格式和使用方法.1. 移动GPU大全 目前移动市场的GPU主要有四大厂商系列:1)Imagination Technologies的P ...
- Caffe学习笔记2--Ubuntu 14.04 64bit 安装Caffe(GPU版本)
0.检查配置 1. VMWare上运行的Ubuntu,并不能支持真实的GPU(除了特定版本的VMWare和特定的GPU,要求条件严格,所以我在VMWare上搭建好了Caffe环境后,又重新在Windo ...
- GPU深度发掘(一)::GPGPU数学基础教程
作者:Dominik Göddeke 译者:华文广 Contents 介绍 准备条件 硬件设备要求 软件设备要求 两者选择 初始化OpenGL GLUT OpenGL ...
- Linux后台执行脚本文件,nohup
看运维人员执行nohup命令后,把程序放在后台执行,很高大上,就研究了一下,这个命令. nohup命令及其输出文件 nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么 ...
随机推荐
- Python中节省内存的方法之二:弱引用weakref
弱引用和引用计数息息相关,在介绍弱引用之前首先简单介绍一下引用计数. 引用计数 Python语言有垃圾自动回收机制,所谓垃圾就是没有被引用的对象.垃圾回收主要使用引用计数来标记清除. 引用计数:pyt ...
- 文件描述符&文件句柄
一.概念 1.1 文件描述符&文件描述符表 文件描述符(file descriptor, fd)是Linux系统中对已打开文件的一个抽象标记,所有I/O系统调用对已打开文件的操作都要用到它.这 ...
- 【每日一题】10.树(DFS 序)
补题链接:Here DFS序列 (非树形DP),这道题成功被骗... 贴一下学姐讲解: 这个题表面上看起来像是个 树上dp,但是你会发现,当xy同色的时候要求x到y的路径上所有点颜色一样这个事情非常难 ...
- 面试重点:webpack
webpack 熟练掌握Webpack的常用配置,能够自己构建前端环境,并进行项目优化; 001.谈谈你对webpack的看法: webpack是一个模块打包工具,可以使用它管理项目中的模块依赖,并编 ...
- uni-app安卓手机无法连接到调试服务
uni-app连接安卓真机,发现接口调不通,打开Hbuilder下方的调试.可查看失败原因:如下图 解决方法:电脑变热点,手机连这个热点,就能解决手机和pc在同一局域网.具体操作,参照以下网站: ht ...
- loadrunner12的安装教程
一.LR12安装包: 链接:https://pan.baidu.com/s/1UU304e-nP7qAL-fV8T39YQ 密码:jpln 二.LR12安装: 1.下载完成后点击解压
- 理解 docker volume
1. docker volume 简介 文章 介绍了 docker image,它由一系列只读层构成,通过 docker image 可以提高镜像构建,存储和分发的效率,节省时间和存储空间.然而 do ...
- Python-函数-算术函数
#python-函数-算术函数 #(1)加减乘除 #加法 add(),减法 subtract(),乘法 multiply(),除法 divide() #作用:数组间的加减乘除 import numpy ...
- Angular系列教程之变更检测与性能优化
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- [转帖]小米Redis的K8s容器化部署实践
https://juejin.cn/post/6844904196924276743 背景 Why K8S How K8s Why Proxy Proxy带来的问题 K8s带来的好处 遇到的问 ...