MaxCompute中如何通过logview诊断慢作业
建模服务,在MaxCompute执行sql任务的时候有时候作业会很慢,本文通过查看logview排查具体任务慢的原因
在这里把任务跑的慢的问题划分为以下几类
- 资源不足导致的排队(一般是包年包月项目)
- 数据倾斜,数据膨胀
- 用户自身逻辑导致的运行效率低下
一、资源不足
一般的SQL任务会占用CPU、Memory这两个维度的资源,logview如何查看参考链接
1.1 查看作业耗时和执行的阶段


1.2 提交任务的等待
如果提交任务以后一直显示“Job Queueing...”则有可能是由于其他人的任务占用了资源组的资源,使得自己的任务在排队。
在SubStatusHistory中看Waiting for scheduling就是等待的时间

1.3 任务提交后的资源不足
这里还有另一种情况,虽然任务可以提交成功,但是由于所需的资源较大,当前的资源组不能同时启动所有的实例,导致出现了任务虽然有进度,但是执行并不快的情况。这种可以通过logview中的latency chart功能观察到。latency chart可以在detail中点击相应的task看到

上图显示的是一个资源充足的任务运行状态,可以看到蓝色部分的下端都是平齐的,表示几乎在同一时间启动了所有的实例。

而这个图形的下端呈现阶梯向上的形态,表示任务的实例是一点一点的调度起来的,运行任务时资源并不充足。如果任务的重要性较高,可以考虑增加资源,或者调高任务的优先级。
1.4资源不足的原因
1.通过cu管家查看cu是否占满,点到对应的任务点,找到对应时间看作业提交的情况

按cpu占比进行排序
(1)某个任务占用cu特别大,找到大任务看logview是什么原因造成(小文件过多、数据量确实需要这么多资源)。
(2)cu占比均匀说明是同时提交多个大任务把cu资源直接打满。

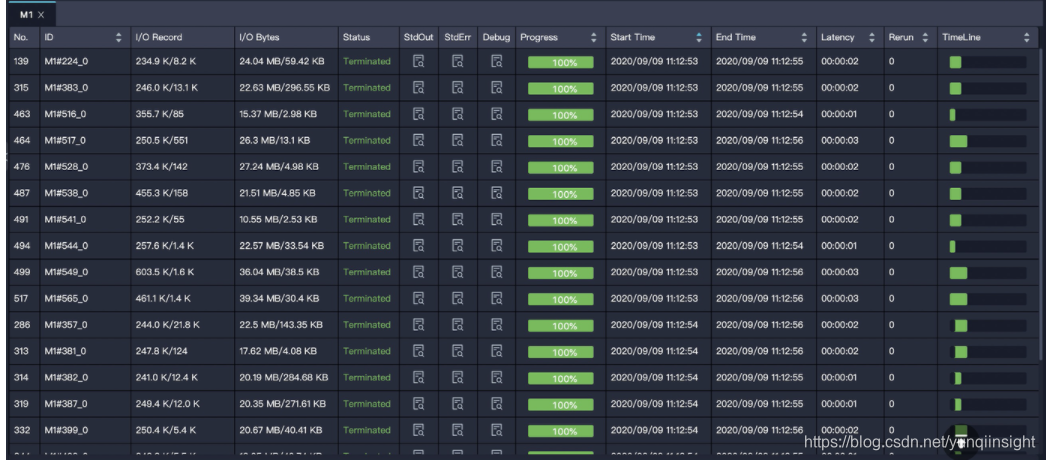
2.由于小文件过多导致cu占慢
map阶段的并行度是根据输入文件的分片大小,从而间接控制每个Map阶段下Worker的数量。默认是256m。如果是小文件会当作一个块读取如下图map阶段m1每个task的i/o bytes都只有1m或者几十kb,所以造成2500多个并行度瞬间把资源打满,说明该表下文件过多需要合并小文件

3.数据量大导致资源占满
可以增加购买资源,如果是临时作业可以加set odps.task.quota.preference.tag=payasyougo;参数,可以让指定作业临时跑到按量付费大资源池,
1.5任务并行度如何调节
MaxCompute的并行度会根据输入的数据和任务复杂度自动推测执行,一般不需要调节,理想情况并行度越大速度处理越快但是对于包年包月资源组可能会把资源组占满,导致任务都在等待资源这种情况会导致任务变慢
map阶段并行度
odps.stage.mapper.split.size :修改每个Map Worker的输入数据量,即输入文件的分片大小,从而间接控制每个Map阶段下Worker的数量。单位MB,默认值为256 MB
reduce的并行度
odps.stage.reducer.num :修改每个Reduce阶段的Worker数量
odps.stage.num:修改MaxCompute指定任务下所有Worker的并发数,优先级低于odps.stage.mapper.split.size、odps.stage.reducer.mem和odps.stage.joiner.num属性。
odps.stage.joiner.num:修改每个Join阶段的Worker数量。
二、数据倾斜
数据倾斜
【特征】task 中大多数 instance 都已经结束了,但是有某几个 instance 却迟迟不结束(长尾)。如下图中大多数(358个)instance 都结束了,但是还有 18 个的状态是 Running,这些 instance 运行的慢,可能是因为处理的数据多,也可能是这些instance 处理特定数据慢。

 解决方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
解决方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
三、逻辑问题
这里指用户的SQL或者UDF逻辑低效,或者没有使用最优的参数设定。表现出来的现象时一个Task的运行时间很长,而且每个实例的运行时间也比较均匀。这里的情况更加多种多样,有些是确实逻辑复杂,有些则有较大的优化空间。
数据膨胀
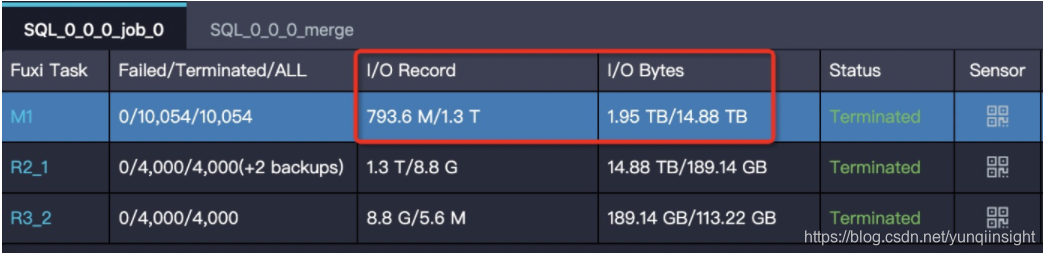
【特征】task 的输出数据量比输入数据量大很多。
比如 1G 的数据经过处理,变成了 1T,在一个 instance 下处理 1T 的数据,运行效率肯定会大大降低。输入输出数据量体现在 Task 的 I/O Record 和 I/O Bytes 这两项:
解决方法:确认业务逻辑确实需要这样,增大对应阶段并行度
UDF执行效率低
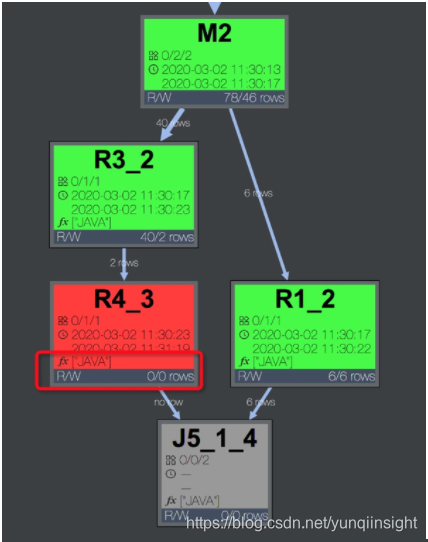
【特征】某个 task 执行效率低,且该 task 中有用户自定义的扩展。甚至是 UDF 的执行超时报错:“Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance”。
首先确定udf位置,点看慢的fuxi task, 可以看到operator graph 中是否包含udf,例如下图说明有java 的udf。
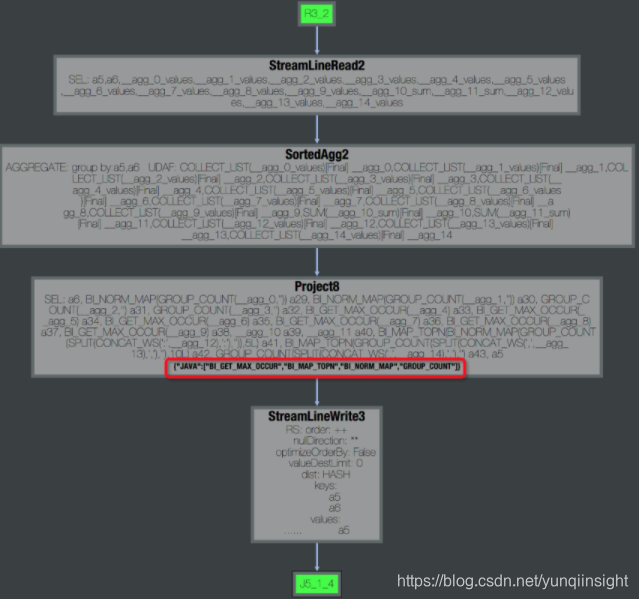
通过查看logview 中fuxi instance 的stdout 可以查看该operator 运行速度,正常情况 Speed(records/s) 在百万或者十万级别。
解决方法:检查udf逻辑尽量使用内置函数
本文为阿里云原创内容,未经允许不得转载。
MaxCompute中如何通过logview诊断慢作业的更多相关文章
- 在MaxCompute中利用bitmap进行数据处理
很多数据开发者使用bitmap技术对用户数据进行编码和压缩,然后利用bitmap的与/或/非的极速处理速度,实现类似用户画像标签的人群筛选.运营分析的7日活跃等分析.本文给出了一个使用MaxCompu ...
- 在MaxCompute中配置Policy策略遇到结果不一致的问题
背景信息: 本文以如下场景为基准进行编写,如下: 用户通过DataWorks-简单模式使用MaxCompute: 用户具有DataWorks默认角色,如DataWorks开发者角色: 用户通过cons ...
- 【监控笔记】【2.4】SQL Server中的 Ring Buffer 诊断各种系统资源压力情况
SQL Server 操作系统(SQLOS)负责管理特定于SQL Server的操作系统资源. 其中相关的动态管理试图sys.dm_os_ring_buffers将被标识为仅供参考.不提供支持.不保证 ...
- Hive中SQL查询转换成MapReduce作业的过程
- 一探究竟:善用 MaxCompute Studio 分析 SQL 作业
头疼的问题 MaxCompute 用户一个常见的问题是:同一个周期任务,为什么最近几天比之前慢了很多?或者为什么之前都能按时产出的作业最近经常破线? 通常来说,引起作业执行变慢的原因有:quota 组 ...
- 一条SQL在 MaxCompute 分布式系统中的旅程
摘要:2019杭州云栖大会大数据技术专场,由阿里云资深技术专家侯震宇.阿里云高级技术专家陈颖达以及阿里云资深技术专家戴谢宁共同以“SQL在 MaxCompute 分布式系统中的旅程 ”为题进行了演讲. ...
- 如何清除 DBA_DATAPUMP_JOBS 视图中的异常数据泵作业
解决方案 用于这个例子中的作业: - 导出作业 SCOTT.EXPDP_20051121 是一个正在运行的 schema 级别的导出作业 - 导出作业 SCOTT.SYS_EXPORT_TABLE_0 ...
- Yarn源码分析之MapReduce作业中任务Task调度整体流程(一)
v2版本的MapReduce作业中,作业JOB_SETUP_COMPLETED事件的发生,即作业SETUP阶段完成事件,会触发作业由SETUP状态转换到RUNNING状态,而作业状态转换中涉及作业信息 ...
- C#作业系统中的安全系统
比赛条件 编写多线程代码时,总是存在竞争条件的风险.当一个操作的输出取决于其控制之外的另一个过程的定时时,发生竞争条件. 竞争条件并不总是一个错误,但它是不确定行为的来源.当竞争条件确实导致错误时,可 ...
- MaxCompute Spark开发指南
0. 概述 本文档面向需要使用MaxCompute Spark进行开发的用户使用.本指南主要适用于具备有Spark开发经验的开发人员. MaxCompute Spark是MaxCompute提供的兼容 ...
随机推荐
- JavaScript知识总结 原型篇
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 1. 对原型.原型链的理解 在JavaScript中是使用构造函数来新建一个对象的,每一个构造函数的内部都有一个 prototype 属性 ...
- Tableau 绘制圆环图
一.对应数据如下所示 二.打开tableau连接对应Excel数据源,将记录数字段连续拖动两次到行,显示设置按整个视图显示,标记里面设置按饼图显示 三.设置两个值按度量值平均值显示,并调整第一个图稍微 ...
- ChatGPT 指令大全
1.写报告 报告开头 我现在正在 报告的情境与目的 .我的简报主题是 主题 ,请提供 数字 种开头方式,要简单到 目标族群 能听懂,同时要足够能吸引人,让他们愿意专心听下去. 我现在正在修台大的简报课 ...
- 【OpenCV】OpenCV (C++) 与 OpenCvSharp (C#) 之间数据通信
OpenCV是一个基于Apache2.0许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux.Windows.Android和Mac OS操作系统上. 它轻量级而且高效--由一 ...
- 巧用dblink 实现多进程并行查询
概述 对于分区表的大数据统计分析,由于数据量巨大,往往需要采用并行.但是数据库并行的效率相比分进程分表统计还是有比较大的差距.本文通过巧用dblink,实现分进程分分区统计数据. 例子 kingbas ...
- Jetty的http-forwarded模块
启用http-forwarded模块,执行如下命令: java -jar $JETTY_HOME/start.jar --add-modules=http-forwarded 命令的输出,如下: IN ...
- kube-apiserver限流机制原理
本文分享自华为云社区<kube-apiserver限流机制原理>,作者:可以交个朋友. 背景 apiserver是kubernetes中最重要的组件,一旦遇到恶意刷接口或请求量超过承载范围 ...
- OpenHarmony 3.2 Release新特性解读之驱动HCS
OpenAtom OpenHarmony(以下简称"OpenHarmony")开源社区,在今年4月正式发布了OpenHarmony 3.2 Release版本,标准系统能力进一 ...
- OpenHarmony将携新成果亮相HDC2022
第四届华为开发者大会 2022(Together)将于11月4日-6日在东莞召开,OpenAtom OpenHarmony(以下简称"OpenHarmony")将携新生态成果亮相 ...
- Python 变量:创建、类型、命名规则和作用域详解
变量 变量是用于存储数据值的容器. 创建变量 Python没有用于声明变量的命令. 变量在您第一次为其分配值时被创建. 示例 x = 5 y = "John" print(x) p ...