C#简化工作之实现网页爬虫获取数据
公众号「DotNet学习交流」,分享学习DotNet的点滴。
1、需求
想要获取网站上所有的气象信息,网站如下所示:
目前总共有67页,随便点开一个如下所示:
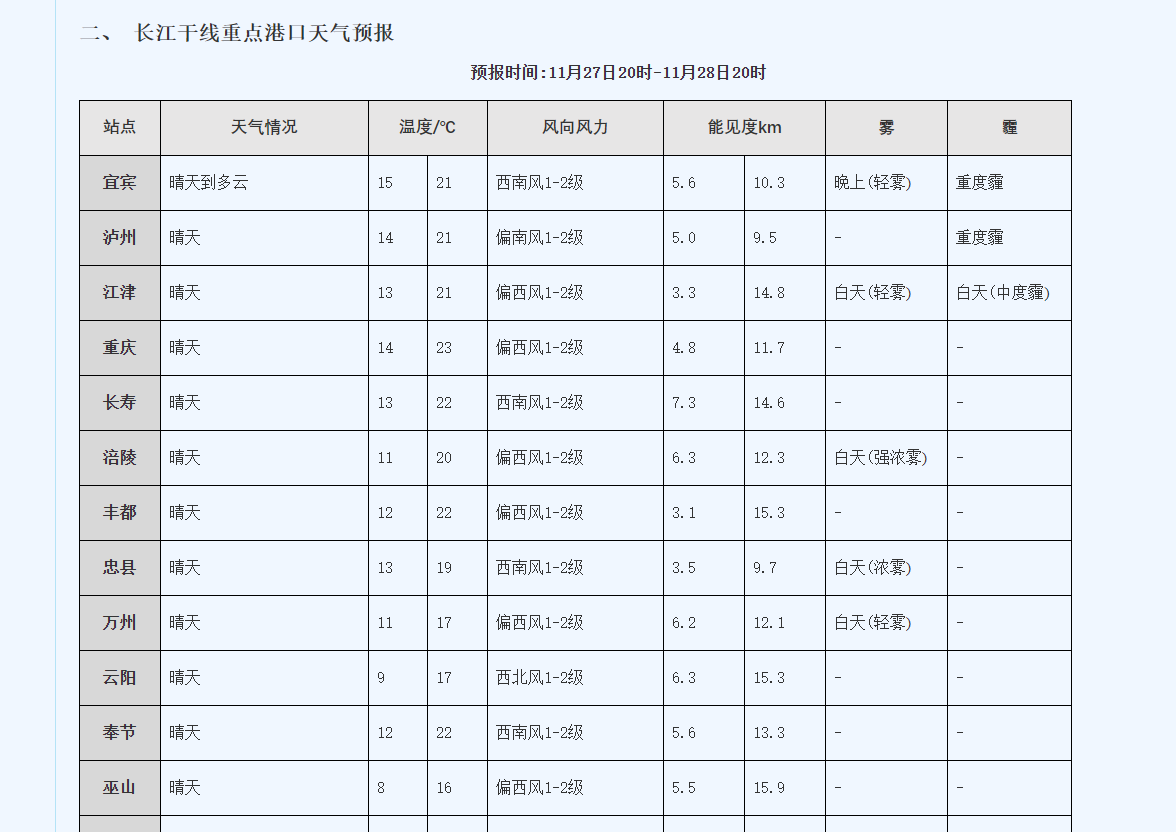
需要获取所有天气数据,如果靠一个个点开再一个个复制粘贴那么也不知道什么时候才能完成,这个时候就可以使用C#来实现网页爬虫获取这些数据。
2、效果
先来看下实现的效果,所有数据都已存入数据库中,如下所示:
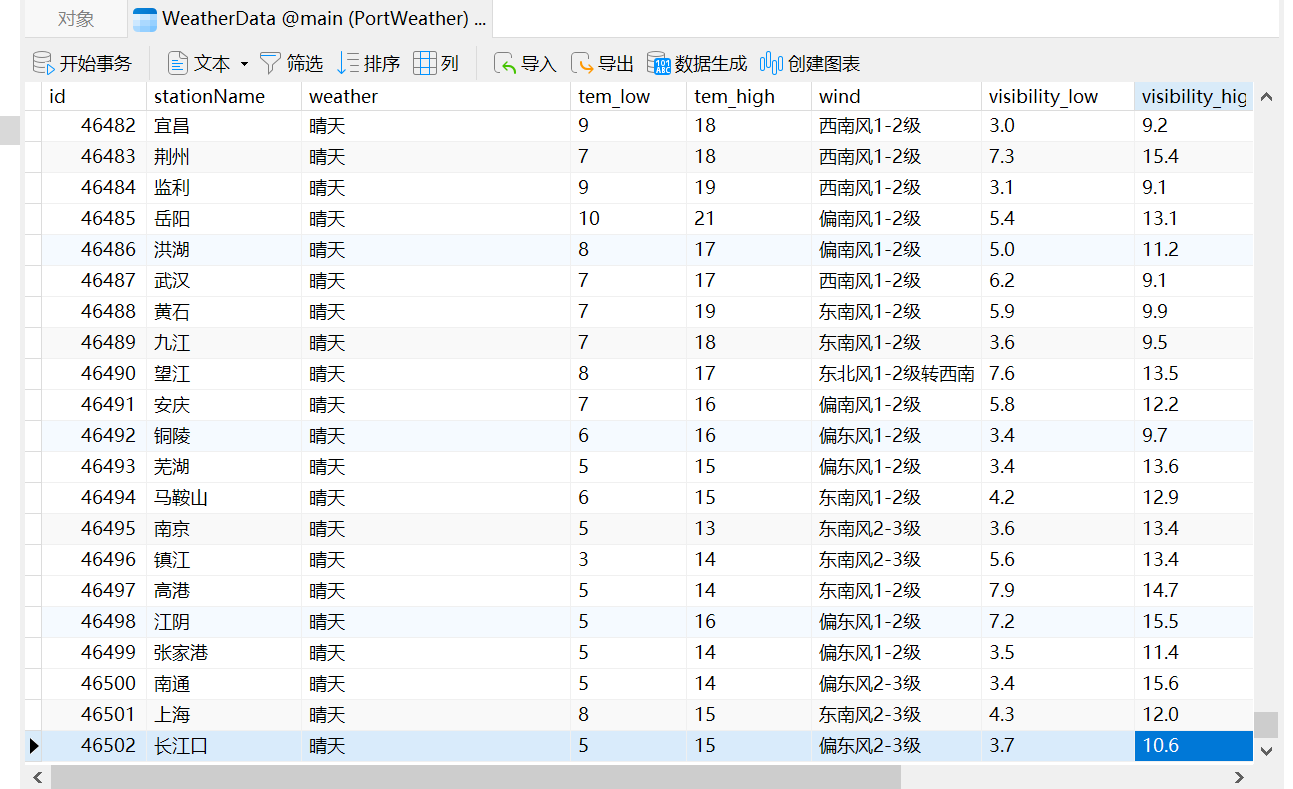
总共有4万多条数据。
3、具体实现
构建每一页的URL
第一页的网址如下所示:

最后一页的网址如下所示:
可以发现是有规律的,那么就可以先尝试构建出每个页面的URL
// 发送 GET 请求
string url = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
HttpResponseMessage response = await httpClient.GetAsync(url);
// 处理响应
if (response.IsSuccessStatusCode)
{
string responseBody = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody);
//获取需要的数据所在的节点
var node = doc.DocumentNode.SelectSingleNode("//div[@class=\"page\"]/script");
string rawText = node.InnerText.Trim();
// 使用正则表达式来匹配页数数据
Regex regex = new Regex(@"\b(\d+)\b");
Match match = regex.Match(rawText);
if (match.Success)
{
string pageNumber = match.Groups[1].Value;
Urls = GetUrls(Convert.ToInt32(pageNumber));
MessageBox.Show($"获取每个页面的URL成功,总页面数为:{Urls.Length}");
}
}
//构造每一页的URL
public string[] GetUrls(int pageNumber)
{
string[] urls = new string[pageNumber];
for (int i = 0; i < urls.Length; i++)
{
if (i == 0)
{
urls[i] = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index.shtml";
}
else
{
urls[i] = $"https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index_{i}.shtml";
}
}
return urls;
}
这里使用了HtmlAgilityPack

HtmlAgilityPack(HAP)是一个用于处理HTML文档的.NET库。它允许你方便地从HTML文档中提取信息,修改HTML结构,并执行其他HTML文档相关的操作。HtmlAgilityPack 提供了一种灵活而强大的方式来解析和处理HTML,使得在.NET应用程序中进行网页数据提取和处理变得更加容易。
// 使用HtmlAgilityPack解析网页内容
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml("需要解析的Html");
//获取需要的数据所在的节点
var node = doc.DocumentNode.SelectSingleNode("XPath");
那么XPath是什么呢?
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言。它是W3C(World Wide Web Consortium)的标准,通常用于在XML文档中执行查询操作。XPath提供了一种简洁而强大的方式来导航和操作XML文档的内容。
构建每一天的URL
获取到了每一页的URL之后,我们发现在每一页的URL都可以获取关于每一天的URL信息,如下所示:
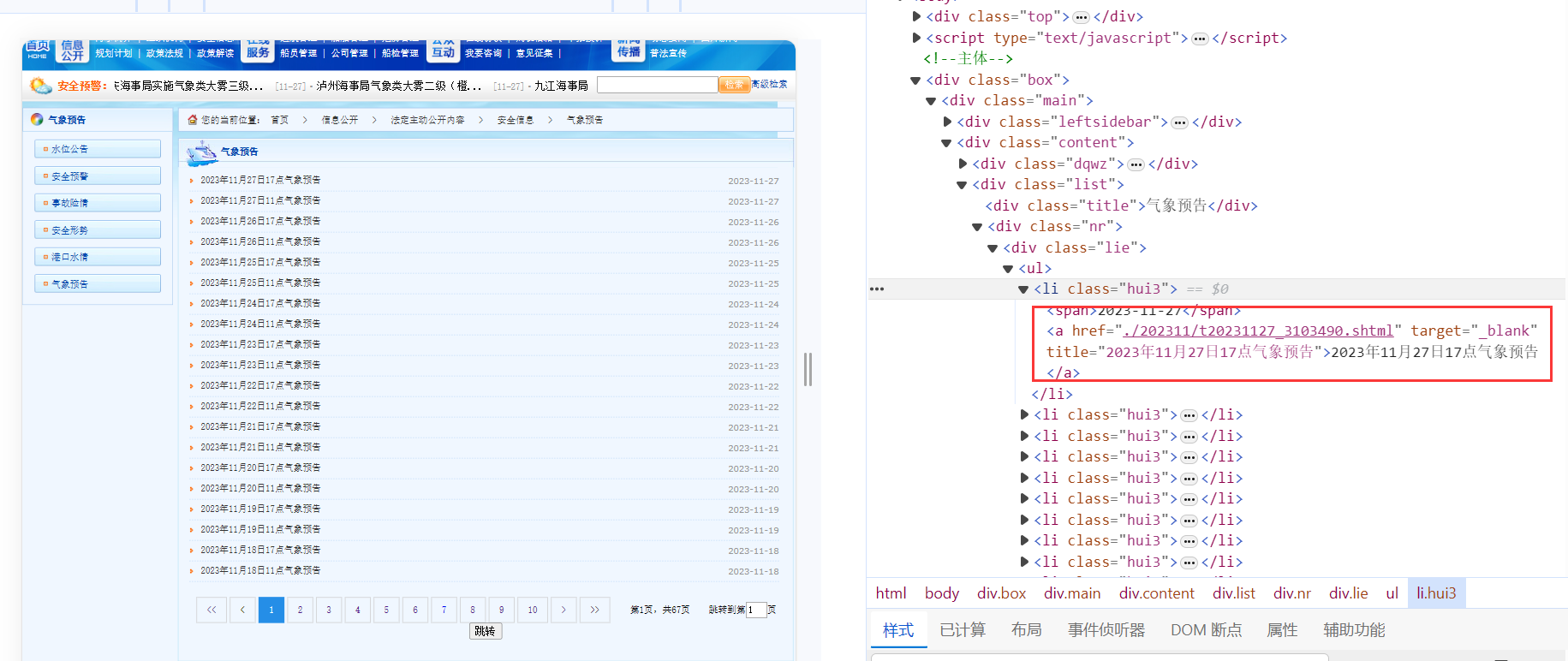
可以进一步构建每一天的URL,同时可以根据a的文本获取时间,当然也可以通过其他方式获取时间,但是这种可以获取到11点或者17点。
代码如下所示:
for (int i = 0; i < Urls.Length; i++)
{
// 发送 GET 请求
string url2 = Urls[i];
HttpResponseMessage response2 = await httpClient.GetAsync(url2);
// 处理响应
if (response2.IsSuccessStatusCode)
{
string responseBody2 = await response2.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("//div[@class=\"lie\"]/ul/li");
for (int j = 0; j < nodes.Count; j++)
{
var name = nodes[j].ChildNodes[3].InnerText;
//只有name符合下面的格式才能成功转换为时间,所以这里需要有一个判断
if (name != "" && name.Contains("气象预告"))
{
var dayUrl = new DayUrl();
//string format;
//DateTime date;
// 定义日期时间格式
string format = "yyyy年M月d日H点气象预告";
// 解析字符串为DateTime
DateTime date = DateTime.ParseExact(name, format, null);
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
dayUrl.Date = date;
dayUrl.Url = realUrl;
dayUrlList.Add(dayUrl);
}
else
{
Debug.WriteLine($"在{name}处,判断不符合要求");
}
}
}
}
// 将数据存入SQLite数据库
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"获取每天的URL成功,共有{dayUrlList.Count}条");
}
在这一步骤需要注意的是XPath的书写,以及每一天URL的构建,以及时间的获取。
XPath的书写:
var nodes = doc.DocumentNode.SelectNodes("//div[@class=\"lie\"]/ul/li");
表示一个类名为"lie"的div下的ul标签下的所有li标签,如下所示:
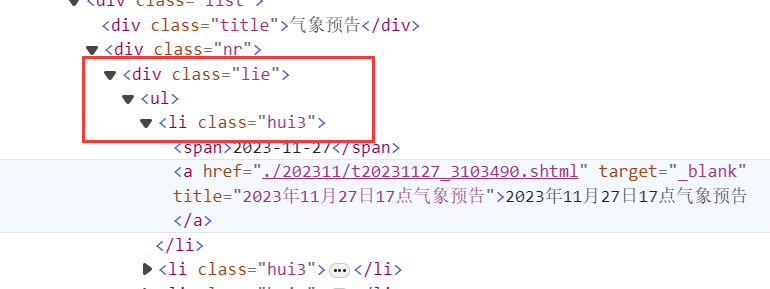
构建每一天的URL:
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
这里获取li标签下的a标签,如下所示:
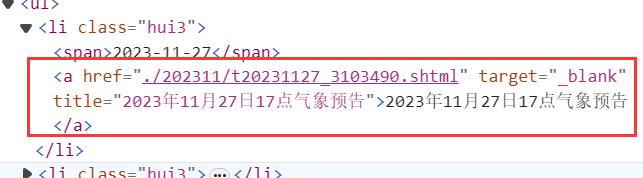
string urlText = a.GetAttributeValue("href", "");
这段代码获取a标签中href属性的值,这里是./202311/t20231127_3103490.shtml。
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = newValue + urlText.Substring(1);
这里是在拼接每一天的URL。
var name = nodes[j].ChildNodes[3].InnerText;
// 定义日期时间格式
string format = "yyyy年M月d日H点气象预告";
// 解析字符串为DateTime
DateTime date = DateTime.ParseExact(name, format, null);
这里是从文本中获取时间,比如文本的值也就是name的值为:“2023年7月15日17点气象预告”,name获得的date就是2023-7-15 17:00。
// 将数据存入SQLite数据库
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"获取每天的URL成功,共有{dayUrlList.Count}条");
这里是将数据存入数据库中,ORM使用的是SQLSugar,类DayUrl如下:
internal class DayUrl
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public DateTime Date { get; set; }
public string Url { get; set; }
}
最后获取每一天URL的效果如下所示:

获取温度数据
需要获取的内容如下:

设计对应的类如下:
internal class WeatherData
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public string? StationName { get; set; }
public string? Weather { get; set; }
public string? Tem_Low { get; set; }
public string? Tem_High { get; set; }
public string? Wind { get; set; }
public string? Visibility_Low { get; set; }
public string? Visibility_High { get; set; }
public string? Fog { get; set; }
public string? Haze { get; set; }
public DateTime Date { get; set; }
}
增加了一个时间,方便以后根据时间获取。
获取温度数据的代码如下:
var list = db.Queryable<DayUrl>().ToList();
for (int i = 0; i < list.Count; i++)
{
HttpResponseMessage response = await httpClient.GetAsync(list[i].Url);
// 处理响应
if (response.IsSuccessStatusCode)
{
string responseBody2 = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("//table");
if (nodes != null)
{
var table = nodes[5];
var trs = table.SelectNodes("tbody/tr");
for (int j = 1; j < trs.Count; j++)
{
var tds = trs[j].SelectNodes("td");
switch (tds.Count)
{
case 8:
var wd8 = new WeatherData();
wd8.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd8.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd8.Tem_Low = tds[2].InnerText.Trim().Replace(" ", "");
wd8.Tem_High = tds[3].InnerText.Trim().Replace(" ", "");
wd8.Wind = tds[4].InnerText.Trim().Replace(" ", "");
wd8.Visibility_Low = tds[5].InnerText.Trim().Replace(" ", "");
wd8.Visibility_High = tds[6].InnerText.Trim().Replace(" ", "");
wd8.Fog = tds[7].InnerText.Trim().Replace(" ", "");
wd8.Date = list[i].Date;
weatherDataList.Add(wd8);
break;
case 9:
var wd9 = new WeatherData();
wd9.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd9.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd9.Tem_Low = tds[2].InnerText.Trim().Replace(" ", "");
wd9.Tem_High = tds[3].InnerText.Trim().Replace(" ", "");
wd9.Wind = tds[4].InnerText.Trim().Replace(" ", "");
wd9.Visibility_Low = tds[5].InnerText.Trim().Replace(" ", "");
wd9.Visibility_High = tds[6].InnerText.Trim().Replace(" ", "");
wd9.Fog = tds[7].InnerText.Trim().Replace(" ", "");
wd9.Haze = tds[8].InnerText.Trim().Replace(" ", "");
wd9.Date = list[i].Date;
weatherDataList.Add(wd9);
break;
default:
break;
}
}
}
else
{
}
}
// 输出进度提示
Debug.WriteLine($"已处理完成第{i}个URL");
}
// 将数据存入SQLite数据库
db.Insertable(weatherDataList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"获取天气数据成功,共有{weatherDataList.Count}条");
}
这里使用swith case是因为网页的格式并不是一层不变的,有时候少了一列,没有霾的数据。
wd9.StationName = tds[0].InnerText.Trim().Replace(" ", "");
这里对文本进行这样处理是因为原始的数据是“\n内容 \n”,C#中String.Trim()方法会删除字符串前后的空白,string.Replace("a","b")方法会将字符串中的a换成b。
效果如下所示:

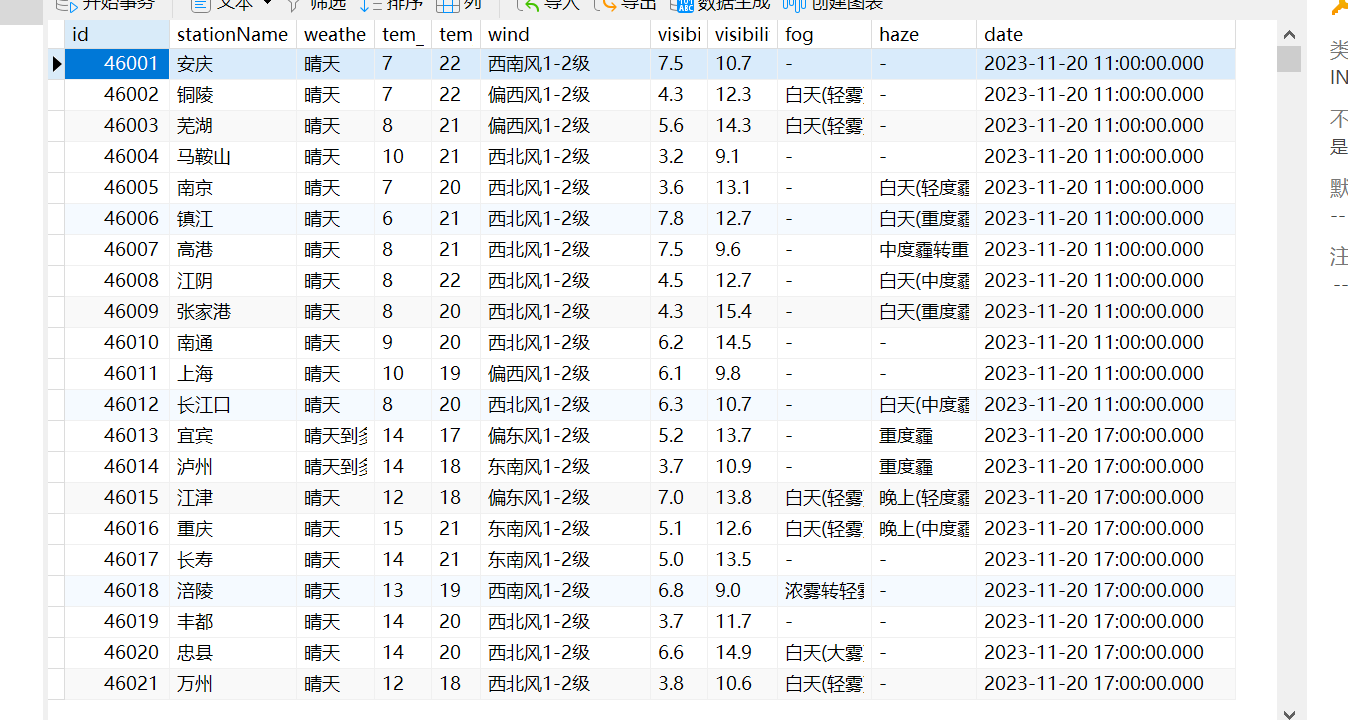
将数据全部都存入数据库中了。
4、最后
通过这个实例说明了其实C#也是可以实现网页爬虫的,对于没有反爬的情况下是完全适用的,再配合linq做数据处理也是可以的。
C#简化工作之实现网页爬虫获取数据的更多相关文章
- 使用Xpath从网页中获取数据
/// <summary> /// 从官方网站中抓取产品信息存放在本地数据库中 /// </summary> /// <returns></returns&g ...
- Python开发实战教程(8)-向网页提交获取数据
来这里找志同道合的小伙伴!↑↑↑ Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知 ...
- 利用Jsoup模拟跳过登录爬虫获取数据
今天在学习爬虫的时候想着学习一下利用jsoup模拟登录.下面分为有验证码和无验证码的情况进行讨论. ---------------------------无验证码的情况---------------- ...
- HttpURLConnection连接网页和获取数据的使用实例
HttpURLConnection是java.net 里面自带的一个类,非常好用.虽然现在很多人用阿帕奇的HttpClient,但HttpURLConnection也是个不错的选择. 其实使用方法非常 ...
- nodeJs爬虫获取数据
var http=require('http'); var cheerio=require('cheerio');//页面获取到的数据模块 var url='http://www.jcpeixun.c ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- JAVA之旅(三十四)——自定义服务端,URLConnection,正则表达式特点,匹配,切割,替换,获取,网页爬虫
JAVA之旅(三十四)--自定义服务端,URLConnection,正则表达式特点,匹配,切割,替换,获取,网页爬虫 我们接着来说网络编程,TCP 一.自定义服务端 我们直接写一个服务端,让本机去连接 ...
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- 网页爬虫的设计与实现(Java版)
网页爬虫的设计与实现(Java版) 最近为了练手而且对网页爬虫也挺感兴趣,决定自己写一个网页爬虫程序. 首先看看爬虫都应该有哪些功能. 内容来自(http://www.ibm.com/deve ...
随机推荐
- appium环境搭建python
python appium环境搭建 appium是什么? 1,appium是开源的移动端自动化测试框架:2,appium可以测试原生的.混合的.以及移动端的web项目:3,appium可以测试io ...
- laravel artisan 常用命令
命令 说明 php artisan key:generate 生成 App Key php artisan make:controller 生成控制器 php artisan make:model 生 ...
- vlan与单臂路由
vlan 1,什么是vlan vlan叫做虚拟局域网 (VLAN, Virtual LAN) 虚拟局域网(VLAN)是一组逻辑上的设备和用户,这些设备和用户并不受物理位置的限制,可以根据功能.部门及应 ...
- UI获取元素的几种方式
通过浏览器驱动获取页面元素的8种方式. 定位方法: 通过webdriver对象的find_element方法 通过 id获取元素 el = driver.find_element(By.ID,'id' ...
- win10安装Redis5、配置自启动教程
前提条件:首先我安装的是压缩包版的Redis5.0.14.1,下载链接为 https://github.com/tporadowski/redis/releases 安装教程 下载软件并解压 进入软件 ...
- Redhat 8.2 系统语言切换(英文转中文)
前提条件 确保已连上网,并且配好 yum 源 若未配好 yum 源 可参考我上一篇文章 部分 Linux 换国内源 操作步骤 安装中文语言包 dnf install glibc-langpack-zh ...
- 【路由器】小米 WR30U 解锁并刷机
本文主要记录个人对小米 WR30U 路由器的解锁和刷机过程,整体步骤与 一般安装流程 类似,但是由于 WR30U 的解锁 ssh 和刷机的过程中有一些细节需要注意,因此记录一下 解锁 ssh 环境准备 ...
- 《Linux基础》07. 软件管理
@ 目录 1:软件管理 1.1:rpm 1.1.1:查询 1.1.2:卸载 1.1.3:安装 1.2:yum 1.3:dpkg 1.4:apt 1.4.1:相关配置 1.4.2:常用指令 1.4.3: ...
- codeforces600E. Lomsat gelral(dsu on tree笔记)
知识前驱:树链剖分 codeforces600E. Lomsat gelral 题意:给出一个树,求出每个节点的子树中出现次数最多的颜色的编号和 分析:递归求解,对于一棵树,求出他的所有子树的颜色编号 ...
- 比 nvm 更好用的 node 版本管理工具
什么是 Volta Volta 是一种管理 JavaScript 命令行工具的便捷方式. volta 的特点: 速度 无缝,每个项目的版本切换 跨平台支持,包括 Windows 和所有 Unix sh ...