基于Fabric的性能测试与调优实践
摘要:本文聚焦Fabric核心业务,构建一个测试模型,对社区原生的Fabric和华为云区块链(基于Fabric)进行实测,识别社区原生Fabric的性能瓶颈,并尝试通过华为区块链提供的动态伸缩、快速PBFT算法进行调优,提升几个关键的评测指标。
1、Fabric 性能测试现状
通俗的来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本。比特币(Bitcoin)、以太坊(Ethereum)、超级账本(Hyperledger)都是典型的区块链系统。其中Hyperledger Fabric是最受欢迎的企业级区块链框架,Fabric采用了松耦合的设计,将共识机制、身份验证等组件模块化,使之在应用过程中可以方便地根据应用场景来选择相应的模块。
Fabric的性能是用户最为关注的问题之一,然而,目前没有一个权威中立的机构,根据公认的规则,对Fabric进行性能测试并给出测试报告,大概有下面几个原因:
(1)Fabric还处在快速发展中,尚未给出详细中立并且公认的测试规则;
(2)Fabric网络结构(网络带宽、磁盘IO、计算资源等),配置参数(如区块大小、背书策略、通道数量、状态数据库等),共识算法(solo,kafka,pbft等)都会影响评测结果,很难构建反映fabric 全貌的测试模型;
(3)Fabric 交易过程复杂,和传统的数据库有很多区别,也不适用于传统的测试方案和工具;
本文聚焦Fabric核心业务,构建一个测试模型,对社区原生的Fabric和华为云区块链(基于Fabric)进行实测,识别社区原生Fabric的性能瓶颈,并尝试通过华为区块链提供的动态伸缩、快速PBFT算法进行调优,提升几个关键的评测指标。
2、Fabric 交易过程分析
在Fabric交易过程中,涉及不同的角色,每个角色承担不同的功能,节点(Peer)可细分为背书节点(Endorser peer)和提交节点(Committer peer),共识由排序(Orderer)角色完成。交易流程如下:
 图1:fabric交易流程简图
图1:fabric交易流程简图
(1):应用程序客户端通过SDK向区块链网络发起一个交易提案(Proposal),交易提案把带有本次交易要调用的合约标识、合约方法和参数信息以及客户端签名等信息发送给背书节点(Endorser)。
(2):背书节点(Endorser)收到交易提案(Proposal)后,验证签名并确定提交者是否有权执行操作,验证通过后执行智能合约,并将结果进行签名后发还给应用程序客户端。
(3):应用程序客户端收到背书节点(Endorser)返回的信息后,判断提案结果是否一致,以及是否参照指定的背书策略执行,如果没有足够的背书,则中止处理;否则,应用程序客户端把数据打包到一起组成一个交易并签名,发送给Orderers。
(4):Orderers对接收到的交易进行共识排序,然后按照区块生成策略,将一批交易打包到一起,生成新的区块,发送给提交节点(Committer);
(5):提交节点(Committer)收到区块后,会对区块中的每笔交易进行校验,检查交易依赖的输入输出是否符合当前区块链的状态,完成后将区块追加到本地的区块链,并修改世界状态。
客户端通过Fabric完成交易,要感知三个步骤(收集背书,提交排序和确认结果),而传统的数据库的读写,只要发起请求,等待确认即可。如果使用经典的测试工具如JMeter,需要将fabric sdk进行包装RESTFul接口,增加了评测的复杂度。幸运的是,2017年5月超级账本社区推出Caliper,允许用户通过一系列预置的用例来测试特定的区块链技术实现。Caliper生成的报告将会包含一系列区块链性能指标,如TPS(平均每秒交易数),时延,系统资源占用等。本文的评测结果均为Caliper工具来测试生成。
3、Fabric 测试模型构建
建立性能测试模型,主要包含两部分工作:一是根据业务特点提取评测指标;二是确立稳定可测的业务模型。
3.1 评测指标
Fabric是一个典型的分布式系统,Fabric网络中各个Peer独立部署,分别维护自己的账本(支持背书查询),内部通过Gossip通信完成状态的同步。Fabric符合分区容忍性,根据分布式系统的CAP定理,Fabric在保证可用性的前提下,无法确保一致性。Fabric是通过最终一致性(弱一致性的一种)来保证所有的节点最终就世界状态达成一致,这个过程就是Orderer共识和Peer验证确认的过程。因而在我们的测试模型中,主要考察以下指标:
查询吞吐量(Query Throughput):每秒处理的查询请求量
共识吞吐量(Consensus Throughput):每秒处理的共识请求量
一致性吞吐率(Consistency Throughput):每秒完成的同步业务数
平均时延(Avg Latency):完成一次事务的平均耗时
失败率(Fail Rate):出现业务失败(含超时)的比例
3.2 业务模型
在业务场景的选择上,我们尽可能考虑主流场景,摈弃本身就是瓶颈的选项,聚焦区块链的核心业务。
基础设施方面,Orderer和Peer节点我们选择主流的8vCPU16G规格的虚机,Client选择一台32vCPU64G的虚机。整个测试在一个稳定的子网内完成。Orderer节点我们配置4个,满足3f+1容错的最低要求。Peer节点我们配置1,根据需要最多扩容到5个。
配置参数方面,我们使用单通道,单组织背书,状态数据库选择goleveldb。落块策略使用默认策略(2s/4M/500T)。
共识算法方面,可选择solo、pbft、kafka。solo模式为测试模式,无法用于生产环节。Kafka模式一种支持CFT容错的共识算法,性能主要依赖外挂的kafka集群性能。而pbft能够防范拜占庭节点,应用场景更广泛,对性能的要求也更高。因而,本次测试选择pbft作为共识算法。
链代码方面,我们选择社区提供的chaincode_example02示例,业务数据占比很低,同时能够覆盖账本读写的基本用例。
4 、实测与调优
4.1 查询性能与动态伸缩
Fabric 查询性能其实就是就是一次背书请求。Peer端主要包含3个过程。
(1)校验Proposal签名;
(2)检查是否满足Channel ACL;
(3)模拟执行交易并对结果签名;
代码可以参考社区chaincode_example02。
| Test | Name | Succ | Fail | Send Rate |
Avg Latency |
Query Throughput |
| 1 | query | 10000 | 0 | 962.6tps | 0.01s | 962tps |
| 2 | query | 25000 | 0 | 2493.5tps | 0.07s | 2492tps |
| 3 | query | 50000 | 0 | 4992.0tps | 6.68s | 2503tps |
图2:单组织单Peer的查询性能
可以看到,单节点(8vCPU,16G)的读性能在2500tps左右。观察监控指标发现,CPU使用率在70%左右,接近满载,而内存使用率只有25%左右[z(3] 。这个不难理解,背书过程涉及大量的验证、签名工作,这些都是计算密集型操作。根据区块链符合CAP定理的分区容忍性,我们可以水平扩展组织内Peer来提升性能。华为区块链已经提供了这个伸缩特性,我们将peer的个数扩容为5个。
 图3:华为BCS的动态伸缩特性
图3:华为BCS的动态伸缩特性
再次运行测试脚本,结果如下:
| Test | Name | Succ | Fail | Send Rate |
Avg Latency | Query Throughput |
| 1 | query | 10000 | 0 | 971.4tps | 0.01s | 971tps |
| 2 | query | 25000 | 0 | 2495.8tps | 0.01s | 2494tps |
| 3 | query | 50000 | 0 | 4977.1tps | 0.01s | 4974tps |
| 4 | query | 12000 | 0 | 11898.9tps | 0.06s | 11869tps |
图4:华为BCS单组织5Peer的查询性能
可以看到,在不断服,不牺牲稳定性的前提下,通过将单Peer动态伸为5Peer。性能可以提升4倍多,整体吞吐量超过10000tps,平均延时只有0.06s。
4.2 共识性能与共识算法
共识算法是提升共识性能的关键。社区fabric v1.0.0-alpha2版的提供了PBFT共识是一种实用拜占庭算法。实用拜占庭算法主要改进了拜占庭算法效率不高的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错算法在实际系统应用中变得可行。
我们先用社区的PBFT共识测试下:
| Test | Name | Succ | Fail | Send Rate | Avg Latency |
Consensus Throughput |
Consistency Throughput |
| 1 | invoke | 1000 | 0 | 959.5tps | 5.53s | 574tps | 518tps |
| 2 | invoke | 2000 | 0 | 1996.4tps | 14.84s | 567tps | 520tps |
| 3 | invoke | 5000 | 0 | 4889.8tps | 37.90s | 579tps | 503tps |
图5:社区原生PBFT的共识性能
可以看到,社区原生的PBFT共识,无论是吞吐量,还是平均延时,都比较差。华为PBFT算法具备Early-Stopping性质,即当不存在拜占庭节点时,整个网络将很快达成共识,因而速度应该很快。我们切换为华为快速PBFT共识算法,再实测一下:
| Test | Name | Succ | Fail | Send Rate | Avg Latency |
Consensus Throughput |
Consistency Throughput |
| 1 | invoke | 10000 | 0 | 973.6tps | 1.32s | 970tps | 917tps |
| 2 | invoke | 20000 | 0 | 1976.5tps | 1.24s | 1971tps | 1789tps |
| 3 | invoke | 50000 | 0 | 4995.4tps | 4.21s | 4985tps | 1677tps |
| 4 | invoke | 100000 | 0 | 11133.2tps | 9.91s | 11031tps | 1502tps |
图6:华为BCS 快速PBFT的共识性能
切换到华为PBFT算法后,共识吞吐率可以达到10000tps,一致性吞吐量也接近1800tps。同时,相对社区原生版本,平均时延也大幅缩短。这样的写性能和传统的单节点关系数据库相当,可以满足大部分商用场景。
4.3 关于最终一致性
在共识性能的测试过程中,我们发现当共识吞吐量超过2000时,Peer在同步区块时会出现积压,导致平均时延增大。要详细了解原因,可以通过查阅Fabric的关键源代码 (gossip/state/state.go)来了解Peer落块的过程:
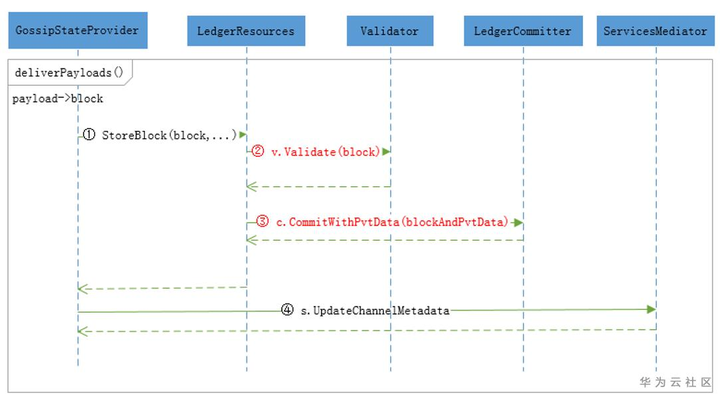 图7:gossip 同步区块流程图
图7:gossip 同步区块流程图
在fabric中,账本数据主要由GossipStateProvider通过Gossip协议来同步,这里只能给出关键的流程。
(1)启动一个协程deliverPayloads从orderer或其它Peer获取 “毛坯块”,调用LegerResources.StoreBlock;
(2) LegerResources调用Validator校验交易是否符合背书策略,检查读集合中版本跟账本是否一致;
(3)LedgerCommittor执行区块中的合法交易,更新账本状态;
(4)ServiceMediator更新通道元数据;
笔者修改了一下源代码,增加了4个步骤的耗时统计,结果显示40000交易生成200块的情况下,步骤2(校验)耗时17s,和步骤3(写块,更新索引)耗时40s。二者占用deliverPayloads 80%的耗时,猜测是一致性吞吐率的瓶颈。开启Profile模式后,监控堆栈调用情况,也进一步验证了这个猜想。[z4]
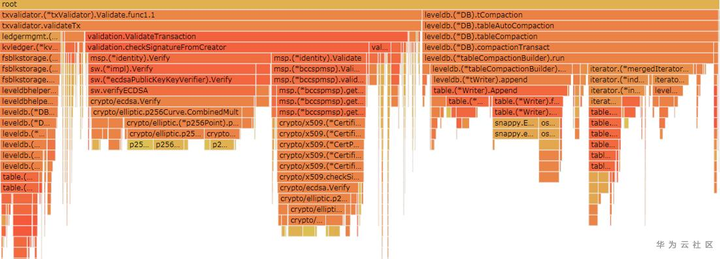 图8:gossip 同步区块Profile火焰图
图8:gossip 同步区块Profile火焰图
笔者能想到的优化方案:
(1)使用高速读写盘(SSD),提高区块文件的读写效率;
(2)Validator校验环节是计算密集型,是否可以借助软硬件结合的方法,大幅提升校验效能;
(3)目前Gossip拿到Payload数据后,只能串行逐一处理。是否可以根据区块的读写集进行分区,交给不同的线程处理,最后再归并落盘,来提升性能(参考多通道性能是单通道的倍级);
笔者通过媒体了解到,华为区块链等产品团队,已经在这方面投人力进行预研,期待可商用的产品早日发布,回报社区。
5、总结
Fabric作为最受欢迎的企业级区块链解决方案,已经在很多领域得到成功应用。在本次测试调优中,发现社区原生Fabric有很多局限,如不易扩展,性能较差,不建议直接用于生产环境。
华为区块链的伸缩特性和快速PBFT算法,能够快速提升Fabric交易性能。其中伸缩特性,可以在不断服的情况下,将查询性能提升到10000tps以上(单peer的4倍多)。而快速PBFT算法,可以将共识吞吐率可提高到10000tps以上(社区原生的20倍),能够满足大部分商用场景。
同时发现,在高并发的情况下,最终一致性的平均时延会出现增长,主要原因为当前区块校验和落盘为顺序串行执行,无法充分利用多核资源。如果社区后继版本或商业公司,能通过软硬件结合,分区归并的思路,提升一致性吞吐率,降低时延,Fabric将会在商用领域获得更大的成功。
6、参考资料
https://hyperledger-fabric.readthedocs.io
https://github.com/hyperledger/caliper
https://github.com/hyperledger/fabric
https://github.com/yeasy/hyperledger_code_fabric
Performance Benchmarking and Optimizing Hyperledger Fabric.pdf
基于Fabric的性能测试与调优实践的更多相关文章
- 软件性能测试分析与调优实践之路-JMeter对RPC服务的性能压测分析与调优-手稿节选
一.JMeter 如何通过自定义Sample来压测RPC服务 RPC(Remote Procedure Call)俗称远程过程调用,是常用的一种高效的服务调用方式,也是性能压测时经常遇到的一种服务调用 ...
- MySQL数据库的性能分析 ---图书《软件性能测试分析与调优实践之路》-手稿节选
1 .MySQL数据库的性能监控 1.1.如何查看MySQL数据库的连接数 连接数是指用户已经创建多少个连接,也就是MySQL中通过执行 SHOW PROCESSLIST命令输出结果中运行着的线程 ...
- 软件性能测试分析与调优实践之路-Web中间件的性能分析与调优总结
本文主要阐述软件性能测试中的一些调优思想和技术,节选自作者新书<软件性能测试分析与调优实践之路>部分章节归纳. 在国内互联网公司中,Web中间件用的最多的就是Apache和Nginx这两款 ...
- 软件性能测试分析与调优实践之路-Java应用程序的性能分析与调优-手稿节选
Java编程语言自从诞生起,就成为了一门非常流行的编程语言,覆盖了互联网.安卓应用.后端应用.大数据等很多技术领域,因此Java应用程序的性能分析和调优也是一门非常重要的课题.Java应用程序的性能直 ...
- Java GC 专家系列3:GC调优实践
本篇是”GC专家系列“的第三篇.在第一篇理解Java垃圾回收中我们学习了几种不同的GC算法的处理过程,GC的工作方式,新生代与老年代的区别.所以,你应该已经了解了JDK 7中的5种GC类型,以及每种G ...
- JVM性能调优实践——JVM篇
前言 在遇到实际性能问题时,除了关注系统性能指标.还要结合应用程序的系统的日志.堆栈信息.GClog.threaddump等数据进行问题分析和定位.关于性能指标分析可以参考前一篇JVM性能调优实践-- ...
- [转载]Java 应用性能调优实践
Java 应用性能调优实践 Java 应用性能优化是一个老生常谈的话题,笔者根据个人经验,将 Java 性能优化分为 4 个层级:应用层.数据库层.框架层.JVM 层.通过介绍 Java 性能诊断工具 ...
- elasticsearch5.3.0 bulk index 性能调优实践
elasticsearch5.3.0 bulk index 性能调优实践 通俗易懂
- PB 级大规模 Elasticsearch 集群运维与调优实践
PB 级大规模 Elasticsearch 集群运维与调优实践 https://mp.weixin.qq.com/s/PDyHT9IuRij20JBgbPTjFA | 导语 腾讯云 Elasticse ...
- MindSpore模型精度调优实践
MindSpore模型精度调优实践 引论:在模型的开发过程中,精度达不到预期常常让人头疼.为了帮助用户解决模型调试调优的问题,为MindSpore量身定做了可视化调试调优组件:MindInsight. ...
随机推荐
- Amazon MSK 可靠性最佳实践
1. Amazon MSK介绍 Kafka作为老牌的开源分布式事件流平台,已经广泛用于如数据集成,流处理,数据管道等各种应用中. 亚马逊云科技也于2019年2月推出了Apache Kafka的云托管版 ...
- 记一次有趣的 buffer overflow detected 问题分析
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 环境说明 无 前言 在我开发的一个实验和学习库中,在很久 ...
- P4221 [WC2018]州区划分 题解
题目链接 题目描述 给出 \(n\) 个城市,\(m\) 条边,一个划分合法当且仅当所有划分中的点集和集合中点之间存在的边集所构成的图不构成欧拉回路且联通. 定义一个点集的值为 划分的总值为其中所有点 ...
- kubernetes驱逐机制总结
概述 k8s的驱逐机制是指在某些场景下,如node节点notReady.node节点压力较大等,将pod从某个node节点驱逐掉,让pod的上层控制器重新创建出新的pod来重新调度到其他node节点. ...
- JUC并发编程学习(十一)四大函数式接口(必备)
四大函数式接口(必备) 程序员:泛型.反射.注解.枚举 新时代程序员:lambda表达式.链式编程.函数式接口.Stream流式计算 函数式接口:只有一个方法的接口 @FunctionalInterf ...
- Kubernetes:kube-apiserver 之准入
kubernetes:kube-apiserver 系列文章: Kubernetes:kube-apiserver 之 scheme(一) Kubernetes:kube-apiserver 之 sc ...
- 论文精读:用于少样本目标检测的元调整损失函数和数据增强(Meta-tuning Loss Functions and Data Augmentation for Few-shot Object Detection)
论文链接:Meta-Tuning Loss Functions and Data Augmentation for Few-Shot Object Detection Abstract 现阶段的少样本 ...
- 总结---Django部分
Django是走大而全的方向,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构.以及全功能的管理后台. Django内置的ORM跟框架内的其他模块耦合程 ...
- OpenTiny Vue 3.12.0 发布:文档大优化!增加水印和二维码两个新组件🎈
你好,我是 Kagol. 非常高兴跟大家宣布,2023年11月30日,OpenTiny Vue 发布了 v3.12.0 . OpenTiny 每次大版本发布,都会给大家带来一些实用的新特性,10.24 ...
- 项目实战接口开发SpringBoot
目录 一.springboot官方demo开发 二.使用SpringBoot开发get方法接口 三.一个要求携带cookie信息访问的get接口开发 四.需要携带参数的get请求两种开发方式 4.1 ...