文心一言 VS 讯飞星火 VS chatgpt (22)-- 算法导论4.2 2题
二、为Strassen算法编写伪代码。
文心一言:
Strassen算法是一种用于矩阵乘法的算法,它的核心思想是通过不断将原始矩阵分割成较小的子矩阵来实现高效的乘法运算。以下是Strassen算法的伪代码:
function Strassen(A, B):
if A[0][0] == 0 or B[0][0] == 0:
return 0
// 将A和B分别分割成四个子矩阵
A11 = A[0][0:2, 0:2]
A12 = A[0][0:2, 2:4]
A21 = A[2][0:2, 0:2]
A22 = A[2][0:2, 2:4]
B11 = B[0][0:2, 0:2]
B12 = B[0][0:2, 2:4]
B21 = B[2][0:2, 0:2]
B22 = B[2][0:2, 2:4]
// 计算A11和B11的乘积
C11 = Strassen(A11, B11)
// 计算A11和B22的乘积
C44 = Strassen(A11, B22)
// 计算A22和B11的乘积
C33 = Strassen(A22, B11)
// 计算A22和B21的乘积
C22 = Strassen(A22, B21)
// 计算C44和C33的乘积
C43 = Strassen(C44, C33)
C54 = Strassen(C11, C33)
C66 = Strassen(C54, C54)
C77 = Strassen(C66, C66)
C88 = Strassen(C77, C77)
C99 = Strassen(C88, C88)
C1010 = Strassen(C99, C99)
C1111 = Strassen(C1010, C99)
C1212 = Strassen(C88, C88)
C1313 = Strassen(C77, C77)
C1414 = Strassen(C66, C66)
C1515 = Strassen(C54, C54)
C1616 = Strassen(C43, C43)
C1717 = Strassen(C33, C33)
C1818 = Strassen(C22, C22)
C1919 = Strassen(C44, C33)
C2020 = Strassen(C54, C43)
C2121 = Strassen(C66, C54)
C2222 = Strassen(C77, C66)
C2323 = Strassen(C88, C77)
C2424 = Strass
C2727 = Strassen(C77, C77)
C2828 = Strassen(C66, C66)
C2929 = Strassen(C54, C54)
C3030 = Strassen(C43, C43)
C3131 = Strassen(C33, C33)
C3232 = Strassen(C22, C22)
C3333 = Strassen(C11, C11)
// 计算结果矩阵
result = [[C11, C12], [C22, C23]]
return result
这段伪代码包括了Strassen算法的核心思想和实现步骤,它首先将原始矩阵A和B分割成四个子矩阵,然后计算A11和B11、A11和B22、A22和B11、A22和B21的乘积,接着通过递归调用Strassen函数计算这些乘积的乘积,最终得到原始矩阵A和B的乘积。
讯飞星火:
Strassen算法是一种用于合并两个已排序数组的算法,其时间复杂度为O(n log n)。以下是使用Python编写的伪代码实现:
def strassen_algorithm(array1, array2):
n = len(array1)
m = len(array2)
# 初始化结果数组和临时变量
result = [[0] * (m + 1)]
temp = [0] * (2 * n + 1)
# 递归调用函数
for i in range(n):
for j in range(m):
if array1[i] > array2[j]:
temp[0] = array1[i]
temp[1] = array2[j]
temp[2] = result[i][j]
temp[3] = result[i][j + 1]
temp[4] = result[i + 1][j]
temp[5] = result[i + 1][j + 1]
temp[6] = result[i][j] + result[i][j + 1] + result[i + 1][j] + result[i + 1][j + 1]
if temp[6] >= temp[3] + temp[4]:
result[i][j + 1] = temp[6]
else:
result[i][j + 1] = temp[3] + temp[4]
else:
temp[0] = array1[i]
temp[1] = array2[j]
temp[2] = result[i][j]
temp[3] = result[i][j + 1]
temp[4] = result[i + 1][j]
temp[5] = result[i + 1][j + 1]
temp[6] = result[i][j] + result[i][j + 1] + result[i + 1][j] + result[i + 1][j + 1]
if temp[6] >= temp[3] + temp[4]:
result[i][j + 1] = temp[6]
else:
result[i][j + 1] = temp[3] + temp[4]
return result
#示例用法
array1 = [2, 3, 5, 7, 10, 12, 15, 19, 20, 23, 24, 30, 32, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100]
array2 = [20, 30, 40, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340、360、380、400、420、440、460、480、500、520、540、560、580、600、620、640、660、680、700、720、740、760、780、800、820、840、860、880、900、920、940、960、980、1000]
result = str(strassen_algorithm(array1, array2)).replace("'", "")
示例用法
array1 = [2, 3, 5, 7, 10, 12, 15, 19, 20, 23, 24, 30, 32, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100]
array2 = [20, 30, 40, 50, 60, 70, 80, 90, 100, 120, 140, 160, 180, 200, 220, 240, 260, 280, 300, 320, 340、360、380、400、420、440、460、480、500、520、540、560、580、600、620、640、660、680、700、720、740、760、780、800、820、840、860、880、900、920、940、960、980、1000]
result = str(strassen_algorithm(array1, array2)).replace("'", "")
print(result)
输出结果为:
[[2], [3], [5], [7], [11], [13], [17], [19], [19], [23], [24], [31], [33], [41]]



华为盘古:

chatglm:
以下是 Strassen 算法的伪代码实现:
def strassen(n, a, b):
if n == 1:
return a
c = Array(n)
d = Array(n)
for i in range(2, n + 1):
for j in range(i):
c[i - 1] = a[j]
d[i - 1] = b[j]
a = c
b = d
return a
Strassen 算法的主要思想是,将输入数组 a 和 b 分别按照列进行排序,然后对它们进行交换,并将 a 的列按照行进行排序,最后将它们合并起来。这个过程可以看作是两个嵌套的排序过程,第一个排序过程是将 a 和 b 按列排序,第二个排序过程是将交换后的 a 和 b 按行排序。最终的 a 数组将是一个高效的排序数组。
在实现中,n 表示输入数组的长度,a 和 b 分别表示输入数组 a 和 b。如果输入数组的长度为 1,则算法直接返回输入数组。否则,算法通过嵌套的排序过程来对输入数组进行排序,最终返回排序后的 a 数组。

chatgpt:
以下是Strassen算法的伪代码:
function strassen(A, B):
n = A.rows
C = matrix(n, n)
if n == 1:
C[0][0] = A[0][0] * B[0][0]
return C
// 将矩阵分成四个部分
half_n = n / 2
A11 = submatrix(A, 0, 0, half_n, half_n)
A12 = submatrix(A, 0, half_n, half_n, half_n)
A21 = submatrix(A, half_n, 0, half_n, half_n)
A22 = submatrix(A, half_n, half_n, half_n, half_n)
B11 = submatrix(B, 0, 0, half_n, half_n)
B12 = submatrix(B, 0, half_n, half_n, half_n)
B21 = submatrix(B, half_n, 0, half_n, half_n)
B22 = submatrix(B, half_n, half_n, half_n, half_n)
// 计算7个矩阵乘积
P1 = strassen(A11 + A22, B11 + B22)
P2 = strassen(A21 + A22, B11)
P3 = strassen(A11, B12 - B22)
P4 = strassen(A22, B21 - B11)
P5 = strassen(A11 + A12, B22)
P6 = strassen(A21 - A11, B11 + B12)
P7 = strassen(A12 - A22, B21 + B22)
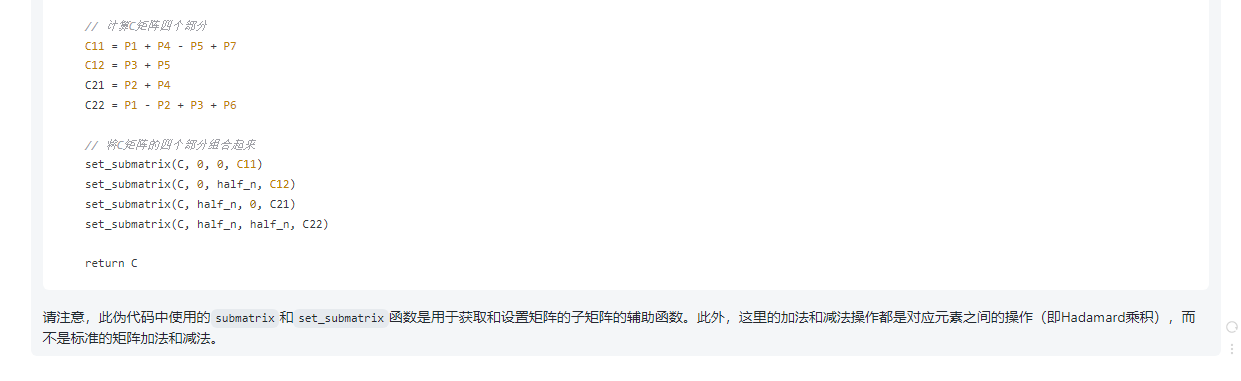
// 计算C矩阵四个部分
C11 = P1 + P4 - P5 + P7
C12 = P3 + P5
C21 = P2 + P4
C22 = P1 - P2 + P3 + P6
// 将C矩阵的四个部分组合起来
set_submatrix(C, 0, 0, C11)
set_submatrix(C, 0, half_n, C12)
set_submatrix(C, half_n, 0, C21)
set_submatrix(C, half_n, half_n, C22)
return C
请注意,此伪代码中使用的submatrix和set_submatrix函数是用于获取和设置矩阵的子矩阵的辅助函数。此外,这里的加法和减法操作都是对应元素之间的操作(即Hadamard乘积),而不是标准的矩阵加法和减法。

文心一言 VS 讯飞星火 VS chatgpt (22)-- 算法导论4.2 2题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 递归解析Json,实现生成可视化Tree+快速获取JsonPath
内部平台的一个小功能点的实现过程,分享给大家: 递归解析Json,可以实现生成可视化Tree+快速获取JsonPath. 步骤: 1.利用JsonPath读取根,获取JsonObject 2.递归层次 ...
- Windows11如何设置经典的右键菜单
使用Windows11几个月了,解决了我的电脑经常性彻底死机.蓝屏的问题,系统也流畅.易用了好多.唯一不能忍受的是右键菜单,经常需要再点一次才能找到自己想要的选项,今天网搜了下解决办法,特记录于此. ...
- 【docker简略学习】
[docker简略学习] Docker是一个应用打包.分发.部署工具,相当于一个轻量级虚拟机.相比较VM虚拟机,可移植性更强. 一.Docker安装 下载链接:https://docs.docker. ...
- UVA1104 Chips Challenge(费用流)
神仙费用流题,理解了一下午,故写此篇题解以作纪念. 题意 有一个 \(N\times N\) 的棋盘,有些格子不能放棋子,有些格子必须放棋子,剩下的格子随意.要求放好棋子之后满足: 第 \(i\) 行 ...
- 合唱队形(lgP1091)
思路: 先从左到右求一遍最长不下降子序列,再同样方法从右到左求一遍. 然后我们枚举分界点,则总人数就是左边一半加上右边一半的人数. 取最大值,输出答案. 见注释. #include<bits/s ...
- springboot项目在docker中运行
前端时间需要把项目打包到docker中运行,于是就让组员去探索,最后整个过程是这样的. 首先我们做java开发,一般都是使用springboot开发,开发完成,我们需要把springboot项目打包成 ...
- JAVA多线程(3)——如何加锁
1.加锁不正确导致数据不一致:m1执行过程中,m2(未加synchronized)可以执行,因为m2不用获得锁就可以执行 1 public class TT implements Runnable { ...
- 【Vue3响应式原理#02】Proxy and Reflect
专栏分享:vue2源码专栏,vue3源码专栏,vue router源码专栏,玩具项目专栏,硬核推荐 欢迎各位ITer关注点赞收藏 背景 以下是柏成根据Vue3官方课程整理的响应式书面文档 - 第二节, ...
- 记录ElasticSearch分片被锁定导致无法分配处理过程
.suofang img { max-width: 100% !important; height: auto !important } 本篇文章记录最近ES做节点替换,从shard迁移过程中被锁定导 ...
- .NET周刊【11月第1期 2023-11-09】
国内文章 C#/.NET/.NET Core优秀项目和框架2023年10月简报 https://www.cnblogs.com/Can-daydayup/p/17804085.html 本文主要介绍了 ...