基于RNN和CTC的语音识别模型,探索语境偏移解决之道
摘要:在本文介绍的工作中,我们展示了一个基于RNN和CTC的语音识别模型,在这个模型中,基于WFST的解码能够有效地融合词典和语言模型.
本文分享自华为云社区《语境偏移如何解决?专有领域端到端ASR之路(三)》,原文作者:xiaoye0829 。
这篇文章我们介绍一个结合CTC与WFST (weighted finite-state transducers) 的工作:《EESEN: END-TO-END SPEECH RECOGNITION USING DEEP RNN MODELS AND WFST-BASED DECODING》。
在这个工作中,声学模型的建模是利用RNN去预测上下文无关的音素或者字符,然后使用CTC去对齐语音和label。这篇文章与众不同的一个点是基于WFST提出了一种通用的解码方法,可以在CTC解码的时候融入词典和语言模型。在这个方法中,CTC labels、词典、以及语言模型被编码到一个WFST中,然后合成一个综合的搜索图。这种基于WFST的方式可以很方便地处理CTC里的blank标签和进行beam search。
在这篇博文中,我们不再叙述关于RNN和CTC的内容。主要关注如何利用WFST进行解码的模块。一个WFST就是一个有限状态接收器(finite-state acceptor, FSA),每一个转换状态都有一个输入符号,一个输出符号,和一个权重。
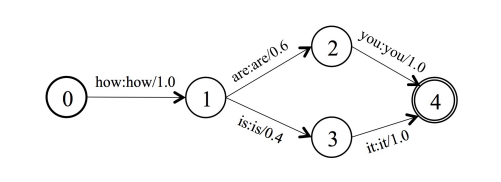
上图是一个语言模型WFST的示意图。弧上的权重是当给定了前面的词语,发射得到下一个词的概率。节点0是开始节点,节点4是结束节点。WFST中的一条路径包含一系列输入符号到输出符号的发射序列。我们的解码方法将CTC labels,词典(lexicons),以及语言模型表示成分别的WFST,然后利用高度优化的FST库,比如OpenFST,我们能有效地将这些WFST融合成一个单独的搜索图。下面我们开始介绍,如何开始构建单个的WFST。
- 1、语法(Grammar). 一个语法WFST编码了语言允许的单词序列。上图是一个精简的语言模型。它有两条序列:“how are you”和“how is it”。WFST的基本符号单位是word,弧上的权重是语言模型的概率。利用这种WFST形式的表示,CTC解码原则上可以利用任何能被转换成WFST的语言模型。按照Kaldi中的表示方式,这个语言模型的WFST被表示为G。
- 2、词典(lexicon). 一个词典WFST编码了从词典单元序列到单词的映射。根据RNN的对应的label的建模单元,这个词典有两种对应的情况。如果label是音素,那么这个词典是与传统的hybrid模型相同的标准词典。如果label是character,那么这个词典简单地包含了每个单词的拼写。这两种情况的区别在于拼写词典能够较为容易地拓展到包含任何OOV(词汇表之外)的单词。相反,拓展音素词典不是那么直观,它依赖于一些grapheme-to-phoneme的方法或者模型,并且容易产生错误。这个词典WFST被表示成L,下图展示了两个词典构建L的例子:

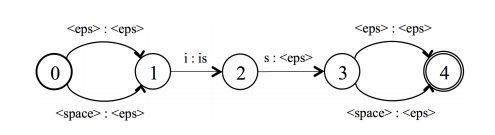
第一个例子展示了音素词典的构建,假如音素词典的条目为“is IH Z”,下面的一个例子展示了拼写词典的构建,“is i s”。对于拼写词典,有另一个复杂的问题需要处理,当以character为CTC的标签时,我们通常在两个word间插入一个额外的空格(space)去建模原始转写之前的单词间隔。在解码的时候,我们允许空格选择性地出现在一个单词的开头和结尾。这种情况能够很轻易地被WFST处理。
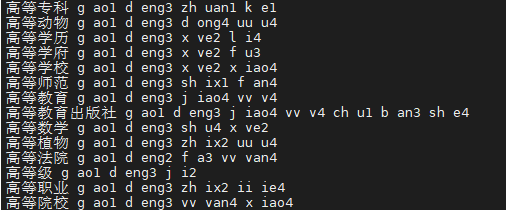
除了英文之外,我们这里也展示一个中文词典的条目。
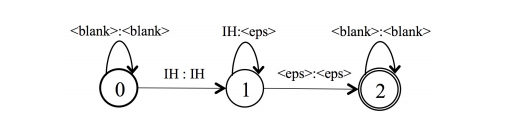
- 3、令牌(token). 第三个WFST将帧级别的CTC标签序列映射到单个词典单元(音素或者character)上。对一个词典单元,token级的WFST被用来归入所有可能的帧级的标签序列。因此,这个WFST允许空白标签∅的出现,以及任何非空白标签的重复。举例来说,在输入5帧之后,RNN模型可能输出3种标签序列:“AAAAA”,“∅∅AA∅”,“∅AAA∅”。Token wfst将这三个序列映射到一个词典单元:“A”上。下图展示了一个音素“IH”的WFST,这个图中允许空白<blank>标签的出现,以及非空白标签“IH”的重复出现。我们将这个token的WFST表示成T。
- 4、搜索图. 在分别编译完三个WFST后,我们将它们合成一个全面的搜索图。首先合成词典WFST L和语法WFST G,在这个过程中,确定性(determinization)和最小化(minimization)被使用,这两个操作是为了压缩搜索空间和加速解码。这个合成的WFST LG,然后与token的WFST进行合成,最后生成搜索图。总得FST操作的顺序是:S = T о min(det(LоG))。这个搜索图S编码了从一个由语音帧对应的CTC标签序列映射到单词序列的过程。具体来说,就是首先将语言模型中的单词解析成音素,构成LG图。然后RNN输出每帧对应的标签(音素或者blank),根据这个标签序列去LG图中进行搜寻。
当解码混合DNN模型时,我们需要使用先验状态去缩放来自DNN的后验状态,这个先验通常由训练数据中的强制对齐估计得到的。在解码由CTC训练得到的模型时,我们采用一个相似的过程。具体地,我们用最终的RNN模型在整个训练集上运行了一遍,具有最大后验的labels被选出来作为帧级的对齐,然后利用这种对齐,我们去估计标签的先验。然而,这种方法在我们的实验中表现得并不好,部分原因是由于利用CTC训练的模型在softmax层后的输出表现出高度的巅峰分布(即CTC模型倾向于输出单个非空的label,因此整个分布会出现很多尖峰),表现在大部分的帧对应的label为blank标签,而非blank的标签只出现在很狭窄的一个区域内,这使得先验分布的估计会被空白帧的数量主导。作为替代,我们从训练集中的标签序列里去估计更鲁棒的标签先验,即从增强后的标签序列中去计算先验。假设原始的标签为:“IH Z”,那么增强后的标签可能为“∅ IH ∅ Z ∅”等。通过统计在每帧上的标签分布数量,我们可以得到标签的先验信息。
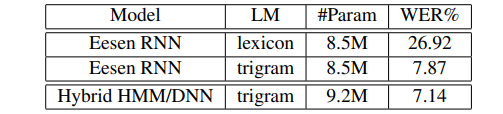
上面介绍了基于WFST的方法,我们接下来来看一下实验部分。在进行后验分布正则之后,这个声学模型的分数需要被缩小,缩放因子在0.5~0.9之间,最佳的缩放值通过实验决定。本文的实验是WSJ上进行的。本文使用的最佳模型是一个基于音素的RNN模型,在eval92测试集上,在使用词典与语言模型时,这个模型达到了7.87%的WER,当只用词典时,WER快速升高到了26.92%。下图展示了本文的Eesen模型与传统hybrid模型的效果对比。从这个表中,我们可以看到Eesen模型比混合的HMM/DNN模型较差一些。但是在更大的数据集上,比如Switchboard,CTC训练的模型能获得比传统模型更好的效果。
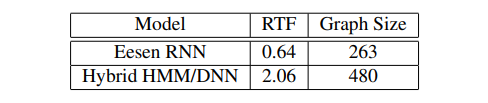
Eesen的一个显著的优势是,相较于混合的HMM/DNN模型,解码速度大大加快了。这种加速来源于状态数量的大幅减少。从下表的解码速度可以看出来,Eesen获取了3.2倍以上的解码速度加速。并且,在Eesen模型中用到的TLG图,也明显小于HMM/DNN中用到的HCLG图,这也节约了用于存储模型的磁盘空间。
总得来说,在本文介绍的工作中,我们展示了一个基于RNN和CTC的语音识别模型,在这个模型中,基于WFST的解码能够有效地融合词典和语言模型.
基于RNN和CTC的语音识别模型,探索语境偏移解决之道的更多相关文章
- 深度学习实战篇-基于RNN的中文分词探索
深度学习实战篇-基于RNN的中文分词探索 近年来,深度学习在人工智能的多个领域取得了显著成绩.微软使用的152层深度神经网络在ImageNet的比赛上斩获多项第一,同时在图像识别中超过了人类的识别水平 ...
- “你什么意思”之基于RNN的语义槽填充(Pytorch实现)
1. 概况 1.1 任务 口语理解(Spoken Language Understanding, SLU)作为语音识别与自然语言处理之间的一个新兴领域,其目的是为了让计算机从用户的讲话中理解他们的意图 ...
- 基于深度学习的中文语音识别系统框架(pluse)
目录 声学模型 GRU-CTC DFCNN DFSMN 语言模型 n-gram CBHG 数据集 本文搭建一个完整的中文语音识别系统,包括声学模型和语言模型,能够将输入的音频信号识别为汉字. 声学模型 ...
- 我们基于kaldi开发的嵌入式语音识别系统升级成深度学习啦
先前的文章<三个小白是如何在三个月内搭一个基于kaldi的嵌入式在线语音识别系统的>说我们花了不到三个月的时间搭了一个基于kaldi的嵌入式语音识别系统,不过它是基于传统的GMM-HMM的 ...
- 基于OpenSeq2Seq的NLP与语音识别混合精度训练
基于OpenSeq2Seq的NLP与语音识别混合精度训练 Mixed Precision Training for NLP and Speech Recognition with OpenSeq2Se ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
- 基于RNN的音频降噪算法 (附完整C代码)
前几天无意间看到一个项目rnnoise. 项目地址: https://github.com/xiph/rnnoise 基于RNN的音频降噪算法. 采用的是 GRU/LSTM 模型. 阅读下训练代码,可 ...
- 阿里巴巴语音识别模型 DFSMN 的使用指南
阿里巴巴 2018 年开源的语音识别模型 DFSMN,将全球语音识别准确率纪录提高至 96.04%.DFSMN 模型,是阿里巴巴的高效工业级实现,相对于传统的 LSTM.BLSTM 等声学模型,该模型 ...
- 转:从头开始编写基于隐含马尔可夫模型HMM的中文分词器
http://blog.csdn.net/guixunlong/article/details/8925990 从头开始编写基于隐含马尔可夫模型HMM的中文分词器之一 - 资源篇 首先感谢52nlp的 ...
- TensorFlow练习7: 基于RNN生成古诗词
http://blog.topspeedsnail.com/archives/10542 主题 TensorFlow RNN不像传统的神经网络-它们的输出输出是固定的,而RNN允许我们输入输出向量 ...
随机推荐
- Godot - 通过C#实现类似Unity协程
参考博客Unity 协程原理探究与实现 Godot 3.1.2版本尚不支持C#版本的协程,仿照Unity的形式进行一个协程的尝试 但因为Godot的轮询函数为逐帧的_Process(float del ...
- Atcoder Regular Contest 165
B. Sliding Window Sort 2 被题目名里的滑动窗口误导了,于是卡 B 40min /fn Description 给定长度为 \(n\) 的排列 \(P\) 和一个整数 \(K\) ...
- Linux常用命令(包含学习资源)
目录 (0)学习资源 (一)查看系统信息 (二)文件和目录 (三)文件搜索 (四)挂载一个文件系统 (五)磁盘空间 (六)用户和群组 (七)文件的权限 - 使用 "+" 设置权限, ...
- 2021北京智源大会SNN部分
神经形态视觉计算 当前问题: spikes vs bits (脉冲 vs 位) meurons vs memory (神经元 vs 计算单元)(真空管vacuum tube,晶体管transistor ...
- Java Junit单元测试(入门必看篇)
Hi i,m JinXiang 前言 本篇文章主要介绍单元测试工具Junit使用以及部分理论知识 欢迎点赞 收藏 留言评论 私信必回哟 博主收将持续更新学习记录获,友友们有任何问题可以在评论区留言 ...
- Java多线程消费消息
多线程消费消息 关键词:Java,多线程,消息队列,rocketmq 多线程一个用例之一就是消息的快速消费,比如我们有一个消息队列我们希望以更快的速度消费消息,假如我们用的是rocketmq,我们从中 ...
- C语言输入任意长度数组后,再在该数组中查找特定的值,并且可查找多个相同的值
C语言输入任意长度数组后,再在该数组中查找特定的值,并且可查找多个相同的值 例:在a[20] = { 99,42,57,74,46,85,32,78,40,33,74,88,65,27,38,69,5 ...
- uni-app小程序项目发布流程
uni-app小程序项目发布流程开发工具:HbuilderX编辑器.微信小程序开发工具1.小程序开发工具就可以点击发行版本了 2.登录开发者平台配置域名白名单 在开发者设置里完成服务器域名配置(域名白 ...
- javaweb项目搭建|前端项目【包含增删改查,mysql】二
首先,新建一个javaweb项目[前提已经下载tomcat,mysql,此实验idea版本为2022,其他版本可能位置不一样] File->New->Project 起一个项目名称(随便起 ...
- ABAP 自定义附件
SWO1 关键字 *------------------------------------------------------------* REPORT ZTEST_CSW1. *TABLES ...