elasticsearch初步使用学习
通过使用elasticsearch,我们可以加快搜索时间(直接使用SQL的模糊查询搜索耗时会比较久,而且elasticsearch的响应耗时与数据量关系不大)
es主要用于存储,计算,搜索数据
依次部署elasticsearch,kibana
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
参数说明9200为访问端口,9300为集群端口
- 第一个环境表示es的最大最小内存,不能低于512
- 第二个环境表示当前是单节点模式
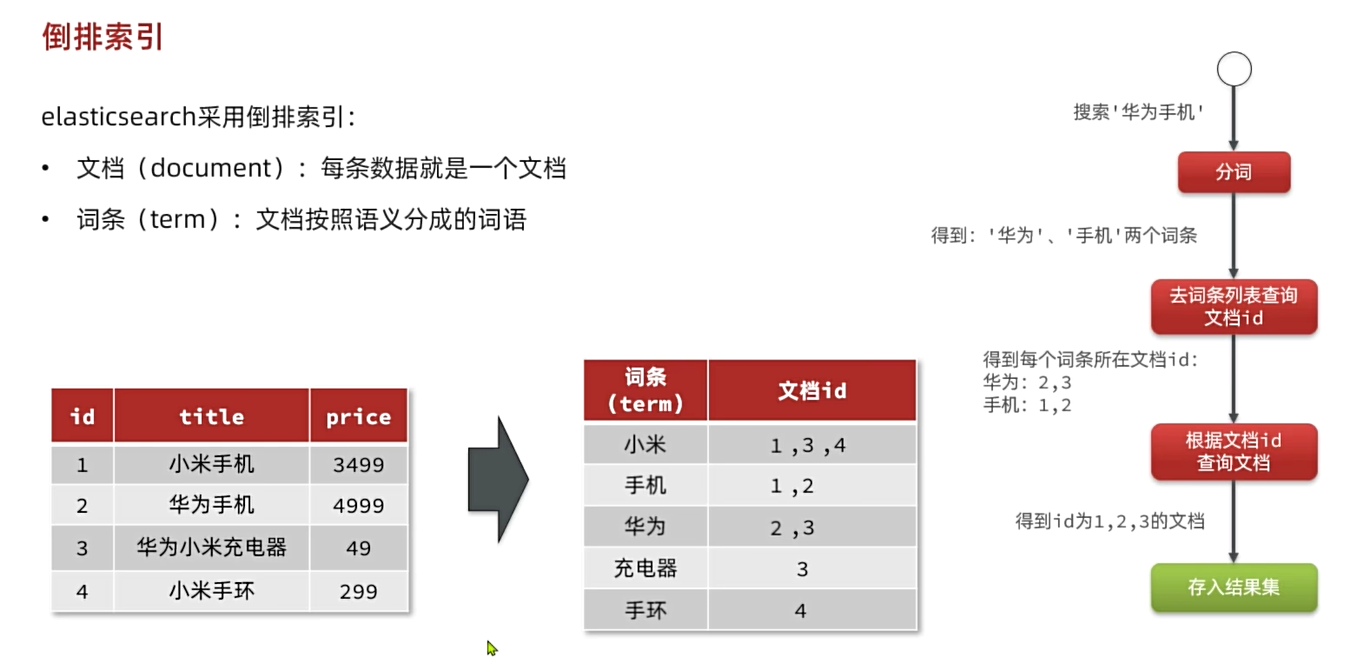
倒排索引:
文档document:每一条数据就是一个文档
词条term:文档按语义分成的词语
索引index:相同类的文档集中在一起
对文档内容分词,对词条建立索引,并记录词条所在文档的id
查询的时候根据词条查询文档id,再根据文档id查询文档
mySQL es
table index
row document
column field
schema mapping mapping是索引中文档的约束
SQL DSL DSL是es提供的json风格请求语句,实现CRUD
IK分词器:
smart智能切分,粗粒度
max_word最细切分,细粒度
POST /_analyze
{
"analyzer": "ik_max_word",// "ik_smart"
"text": "天津市长江大桥"
}
如何拓展IK分词器的词典
修改IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
在config中新建一个ext.dic
市长
江大桥
mapping映射属性:
type:字段数据类型,
常见数据类型:
- 字符串text(这个是可以分词的)keyword(这个是精确值,不可进行分词)
- 数值:long,double,integer,float,byte,short
- 布尔boolean
- 日期date
- 对象object
index:是否创建索引,默认是true
analyzer:使用那种分词器(一般只有text需要指定这个)
properties:(该字段的子字段,一般是给object用的)
索引库操作:对应SQL中的table操作
# 创建索引库样例
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
}
}
}
}
# 查询样例
GET /heima
# 删除样例
DELETE /heima
# 修改样例
PUT /heima/_mapping
{
"properties":{
"age":{
"type": "byte"
}
}
}
文档操作:对应SQL中对column的操作
# 文档操作:新增
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
} # 文档操作:查询
GET /heima/_doc/1 # 文档操作:删除
DELETE /heima/_doc/1 # 文档操作:修改 1.全量修改(先删除旧文档,再新增新文档)
PUT /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "子龙",
"lastName": "赵"
}
} # 文档操作:修改 2.局部修改
POST /heima/_update/1
{
"doc": {
"info": "黑马程序员的Java讲师"
}
}
批处理文档:注意这里不能格式化,必须写在一行上,不然就会报错而且操作失败
# 文档批处理 新增
POST /_bulk
{"index":{"_index":"heima","_id":"3"}}
{"info":"黑马程序员C++讲师","email":"ww@itcast.cn","name":{"firstName":"五","lastName":"王"}}
{"index":{"_index":"heima","_id":"4"}}
{"info":"黑马程序员前端讲师","email":"zhangsan@itcast.cn","name":{"firstName":"三","lastName":"张"}} # 文档批处理 删除
POST /_bulk
{"delete":{"_index":"heima","_id":"3"}}
{"delete":{"_index":"heima","_id":"4"}} # 文档批处理 更新
POST /_bulk
{"update":{"_index":"heima","_id":"3"}}
{"doc":{"info":"黑马程序员C艹讲师"}}
{"update":{"_index":"heima","_id":"4"}}
{"doc":{"info":"黑马程序员非后端讲师"}}
elasticsearch初步使用学习的更多相关文章
- Elasticsearch初步使用(安装、Head配置、分词器配置)
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.ElasticSearch简单说明 a.ElasticSearch是一个基于Lu ...
- SimMechanics/Second Generation倒立摆模型建立及初步仿真学习
笔者最近捣鼓Simulink,发现MATLAB的仿真模块真的十分强大,以前只是在命令窗口敲点代码,直到不小心敲入simulink,就一发不可收拾.话说simulink的模块化建模确实方便,只要拖拽框框 ...
- ElasticSearch权威指南学习(索引管理)
创建索引 当我们需要确保索引被创建在适当数量的分片上,在索引数据之前设置好分析器和类型映射. 手动创建索引,在请求中加入所有设置和类型映射,如下所示: PUT /my_index { "se ...
- 搜索引擎Elasticsearch REST API学习
Elasticsearch为开发者提供了一套基于Http协议的Restful接口,只需要构造rest请求并解析请求返回的json即可实现访问Elasticsearch服务器.Elasticsearch ...
- ElasticSearch基础入门学习笔记
前言 本笔记的内容主要是在从0开始学习ElasticSearch中,按照官方文档以及自己的一些测试的过程. 安装 由于是初学者,按照官方文档安装即可.前面ELK入门使用主要就是讲述了安装过程,这里不再 ...
- Python 0(安装及初步使用+学习资源推荐)
不足之处,还请见谅,请指出不足.本人发布过的文章,会不断更改,力求减少错误信息. Python安装请借鉴网址https://www.runoob.com/python/python-install.h ...
- Elasticsearch的配置学习笔记
文/朱季谦 Elasticsearch是一个基于Lucene的搜索服务器.它提供一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java语言开发的. ...
- Elasticsearch基础知识学习
概要 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java开发的,并作为Ap ...
- 初步了解学习flask轻量级框架,
关于flask我有话说 flask作为一个轻量级框架,它里面有好多扩展包需要下载,比较麻烦,而且有的时候flask需要在虚拟环境下运行,但是他的优点还是有滴 ,只要是用过Django的人,都会觉得fl ...
- ElasticSearch权威指南学习(分布式搜索)
查询阶段 在初始化查询阶段(query phase),查询被向索引中的每个分片副本(原本或副本)广播. 每个分片在本地执行搜索并且建立了匹配document的优先队列(priority queue). ...
随机推荐
- 机器学习策略篇:详解超过人的表现(Surpassing human- level performance)
超过人的表现 讨论过机器学习进展,会在接近或者超越人类水平的时候变得越来越慢.举例谈谈为什么会这样. 假设有一个问题,一组人类专家充分讨论辩论之后,达到0.5%的错误率,单个人类专家错误率是1%,然后 ...
- 《剑指offer3- 从末尾到头打印链表》
题目描述 输入一个链表,按链表值从尾到头的顺序返回一个ArrayList. 本质上是逆转链表 /** * struct ListNode { * int val; * struct ListN ...
- itest(爱测试) 开源接口测试,敏捷测试管理平台10.0.1
一:itest work 简介 itest work 开源敏捷测试管理,包含极简的任务管理,测试管理,缺陷管理,测试环境管理,接口测试,接口Mock,还有压测 ,又有丰富的统计分析,8合1工作站.可按 ...
- kubernetes(k8s)
应用程序部署的演变过程 在部署应用程序的方式上,主要经历了三个时代 传统部署 互联网早期,会直接将应用程序部署在物理机上 优点: 简单,不需要其他技术的参与 缺点: 不能为应用程序定义资源使用边界,很 ...
- 《Qt学习系列笔记》--章节索引
Qt下载.安装及环境搭建:https://www.cnblogs.com/mrlayfolk/p/13111349.html Qt初始化代码基本说明:https://www.cnblogs.com/m ...
- 微信小程序-手持弹幕_文字内容横屏滚动_小程序弹幕源码
哈喽,大家好,我是SCLQ. 最近在抖音刷到手持弹幕的视频,觉得是一个非常有趣应用,在手持弹幕小程序这个软件当中,你可以设置很长一段话,很适合追星.挑战一下自己,做一个小程序的手持弹幕应用. 微信小程 ...
- SonarQube代码质量扫描工具
1.什么是SonarQube 既然是学习devops 运维流水线构建 开发 ↓ 测试 ↓ 运维 华为devops软件开发流水线文档 https://support.huaweicloud.com/re ...
- SD-WAN中二层组网与三层组网的区别
前言 随着企业网络需求的不断增长和变化,SD-WAN作为一种现代网络技术,为企业提供了更灵活.高效的网络解决方案.在SD-WAN中,二层组网和三层组网是两种常见的部署模型,它们有着各自的特点和适用场景 ...
- Caffe样例中mnist的文件之间逻辑分析
约定一下,Caffe运行样例时在终端中使用的所有命令,同时终端中的目录已经cd到Caffe之中(别告诉我一个Github项目你还没有make all就直接拿过来用了) sudo sh data/mni ...
- Freertos学习:在Posix环境仿真FreeRTOS
--- title: rtos-freertos-在Posix环境仿真FreeRTOS date: 2020-06-11 16:22:34 categories: tags: - freertos - ...