Head First Java学习:第十四章-序列化和文件
第十四章 序列化和文件的输入输出
保存对象
1、什么是序列化和反序列化
在编程的世界当中,常常有这样的需求:我们需要将本地已经实例化的某个对象,通过网络传递到其他机器当中,为了满足这种需求,就有了所谓的序列化和反序列化。
序列化就是,把内存中的某个对象压缩成字节流的形式;
反序列化就是,把字节流转换成内存中的对象。
2、把序列化对象写入文件
四部曲:
// 创建出 FileOutputStream
FileOutputStream fs = new FileOutputStream("foo.ser");
// 创建ObjectOutputStream
ObjectOutputStream os = new ObjectOutputStream(fs);
// 写入对象
os.writeObject(myBox);
// 关闭ObjectOutputStream
os.close();
说明:
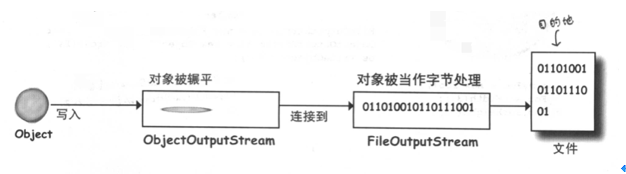
stream 串流,把stream连接起来代表源和目的地的连接,即文件和网络端口的连接。串流 必须要连接到某处才能算是个串流。
串流一般要俩俩连接才能做出有意义的事情,一个表示连接,一个要被调用方法。
按照单一设计原则,每个类做一件事情。
FileOutputStream 把字节写入文件。
ObjectOutputStream 把对象转换成可以写入串流的数据。
调用ObjectOutputStream的writeObject时,对象会被打成stream 送到FileOutputStream,来写入文件。
3、对象被序列化发生了什么?
在堆上的对象,有状态即实例变量的值。这些值让同一类的不同实例有不同意义。
被序列化的对象,保存了实例变量的值因此之后可以在堆上带回一模一样的实例。
实例变量的值和java虚拟机所需要的信息会被保存到文件中,一般是字节码或者xml编码格式文件。
对象的状态时什么,有什么需要保存?
对象的状态 –—— 实例变量的值
- 如果是 primitive 主数据类型,直接保存
- 如果是引用其他对象,那所有对象都被保存。
当对象被序列化,该对象引用的实例变量也会被序列化。且所有被引用的对象也会被序列化。这些操作都是自动进行的。
4、类要被序列化,就要实现 Serializable
objectOutputStream.writeObject(myBox);
myBox必须要实现序列化,否则执行会出问题。
如果序列化的类中,实例变量引用了非序列化的类,执行会报错。
Serializable接口没有任何方法需要实现,唯一目的是申明有实现它的类是可以被序列化的。某个类被序列化,其子类自动可以序列化。
举例:
package chap14;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Box implements Serializable {
private int width;
private int heigh;
public void setWidth(int w){
width = w;
}
public void setHeigh(int h){
heigh = h;
}
public static void main(String[] args) {
Box myBox = new Box();
myBox.setWidth(6);
myBox.setHeigh(7);
try{
// 创建出 FileOutputStream
FileOutputStream fs = new FileOutputStream("foo.ser");
// 创建ObjectOutputStream
ObjectOutputStream os = new ObjectOutputStream(fs);
// 写入对象
os.writeObject(myBox);
// 关闭ObjectOutputStream
os.close();
}catch (Exception ex){
ex.printStackTrace();
}
}
}
5、实例变量不想被序列化,标记为 transient 。
实例变量被标记为 transient ,序列化会跳过;
反序列化会设置为数据类型初始值,如primitive类型是0/0.0/false,引用类型是null。
6、反序列化步骤
举例:
// 1 创建FileInputStream
FileInputStream fileStream = new FileInputStream("foo.ser");
// 2 创建ObjectInputStream
ObjectInputStream os = new ObjectInputStream(fileStream);
// 3 读取对象
Object one = os.readObject();
Object two = os.readObject();
// 4 转换对象类型
GameCharacter elf = (GameCharacter) one;
GameCharacter troll = (GameCharacter) two;
// 5 关闭ObjectInputStream
os.close();
说明:
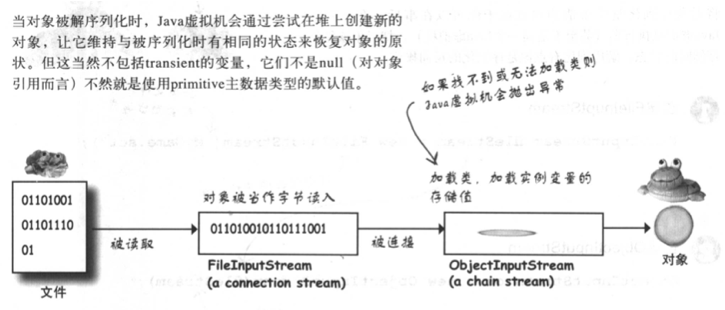
- 对象从stream中读出来
- java虚拟机通过存储的信息判断出对象的class类型
- java虚拟机尝试寻找和加载对象的类,如果虚拟机找不到或无法加载该类,则java虚拟机会抛出异常
- 新的对象会被分配带堆上,但是构造函数不会执行。因为执行构造函数,会把对象的状态抹去又变成全新,而这不是我们想要的结果。我们需要的是对象回到存储时的状态。
- 如果对象在继承树上有个不可序列化的祖先类,则该不可序列化类以及在它之上的类的构造函数(就算是可序列化)都会执行。一旦构造函数连锁启动之后将无法停止。也就是说,从第一个不可序列化的父类开始,全部都会重新初始状态。
- 对象的实例变量会被还原成序列化时点的状态值。transient变量会被赋值null的对象引用,primitive主数据类型的默认为0/0.0/false等值。
7、FileWriter 将字符串写入文本文件
用FileWritrer替代FileOutputStream,但是不会把它连接到 ObjectOutputStream上。
FileWriter b = new FileWriter(“FOO.txt”);
b.write(“hello foo@”);
b.close();
8、io.File class
File 对象代表磁盘上的文件或目录的路径名称,不代表读取或代表文件中的数据
如:/Users/Kathy/Data/GameFile.txt
File对象可以做的事情
- 创建出代表现存盘文件的File对象
举例:
File f = new File(“mycode.txt”);
- 建立新的目录
举例:
File dir = new File(“Chapter7”);
dir.mkdir();
- 列出目录下的内容
举例:
if(dir.isDirectoy){
String[] dirContents = dir.list();
for(int i=0;i<dirContents.length;i++){
sout(dirContents[i])
}
}
- 取得文件或目录的绝对路径
举例:
sout(dir.getAbsolutePath());
- 删除文件或目录(成功会返回true)
Boolean isDeleted = f.delete();
9、缓冲区
缓冲区的好处是同时把多个字符串写入文件,提高效率,节省了磁盘操作的时间。
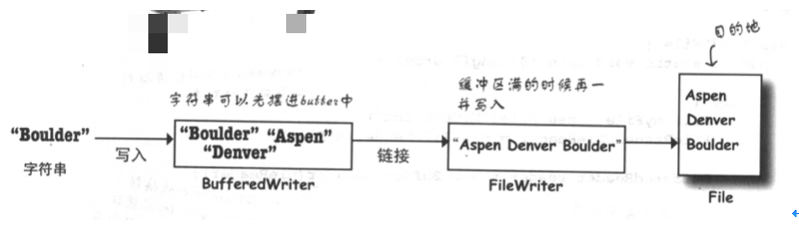
举例:
BufferedWriter writer = new BufferedWriter(new FileWriter(aFile));
强制刷新缓冲区数据:writer.flush()
10、FileReader 读取文本文件
以File对象表示文件,以FileReader来执行实际的读取,并用BufferedReader 来让读取效率更高。
读取以while 循环来逐行进行,一直到readLine()的结果为null 为止。
举例:
package chap14;
import java.io.*;
public class ReadFile {
public static void main(String[] args) {
try{
// File 对象
File myFile = new File("/Users/huqiqi/Desktop/JavaStudy/JavaStudyCode/HeadFirstJavaMaster/src/main/java/chap14/MyText.txt");
// FileReader 是字符的连接到文本文件的串流
FileReader fileReader = new FileReader(myFile);
// 将FileReader 链接到BufferedReader 以获取更高的效率。
// 它只会在缓冲区读空的时候,才会回头区磁盘读取
BufferedReader reader = new BufferedReader(fileReader);
// 承接所读取的结果
String line = null;
// 读一行列一行直到没有东西可读取
while ((line = reader.readLine())!=null){
System.out.println(line);
}
reader.close();
}catch (Exception ex){
ex.printStackTrace();
}
}
}
结果:
hello
this is a file
test FileReader
11、String的split()
举例:
String toTest = "what is blue + yellow?/green?";
String[] result = toTest.split("/");
for(String token:result){
System.out.println(token);
}
结果:
what is blue + yellow?
green?
说明:String的split() 可以把字符串按照指定参数拆成两部分。
12、VersionID:序列化的识别
目的:做版本控制。
13、使用serialVersionUID
序列化是将对象的状态信息转换成可存储或传输的形式的过程。Java的对象保存在JVM的堆内存中,如果JVM堆不存在了,那么对象也就跟着消失了。
序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。把Java对象序列化成可存储或传输的形式(如二进制流),比如保存到文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化对象。
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点就是 两个类的序列化ID是否一致,这个所谓的序列化ID,就是代码中定义的serialVersionUID。
Head First Java学习:第十四章-序列化和文件的更多相关文章
- “全栈2019”Java多线程第二十四章:等待唤醒机制详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- “全栈2019”Java多线程第十四章:线程与堆栈详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- “全栈2019”Java异常第十四章:将异常输出到文本文件中
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java异 ...
- “全栈2019”Java第八十四章:接口中嵌套接口详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第七十四章:内部类与静态内部类相互嵌套
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第六十四章:接口与静态方法详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第五十四章:多态详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第三十四章:可变参数列表
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- Java 学习笔记 ------第四章 认识对象
本章学习目标: 区分基本类型与类类型 了解对象与参考的关系 从打包器认识对象 以对象观点看待数组 认识字符串的特性 一."=" 和 "==" 当=用于基本类型时 ...
- JAVA学习第十四课(接口:implements及其基本应用)
接口: 我们知道抽象类中能够定义抽象方法,也能够定义非抽象方法.当一个抽象类中的方法都是抽象方法的时候,我们就能够定义还有一种表现方式:接口(interface),所以接口是一种特殊的抽象类 接口的出 ...
随机推荐
- 2023-08-24:请用go语言编写。给定一个长度为n的数组arr, 现在你有一次机会, 将其中连续的K个数全修改成任意一个值, 请你计算如何修改可以使修改后的数 列的最长不下降子序列最长。 请输出
2023-08-24:请用go语言编写.给定一个长度为n的数组arr, 现在你有一次机会, 将其中连续的K个数全修改成任意一个值, 请你计算如何修改可以使修改后的数 列的最长不下降子序列最长. 请输出 ...
- 如何使用io_uring构建快速响应的I/O密集型应用?
本文分享自华为云社区<如何使用io_uring构建快速响应的I/O密集型应用>,作者: Lion Long . 当涉及构建快速响应的I/O密集型应用时,io_uring技术展现出了其卓越的 ...
- 细数2019-2023年CWE TOP 25 数据,看软件缺陷的防护
本文分享自华为云社区<从过去5年CWE TOP 25的数据看软件缺陷的防护>,作者:Uncle_Tom. "以史为鉴,可以知兴替".CWE 已经连续5年发布了 CWE ...
- 运行解压版tomcat中的startup.bat一闪而退的解决办法
Tomcat的startup.bat,它调用了catalina.bat,而catalina.bat则调用了setclasspath.bat,只要在setclasspath.bat的开头声明环境变量(红 ...
- Windows安装JDK 8/11/17教程
JDK,全称Java Development Kit,即Java开发工具包,它是整个Java开发的核心,包含了Java运行环境(JVM+Java系统类库)和Java工具.目前JDK 8.11.17是长 ...
- nvm、node、vue安装、vue项目创建打包
nvm.node.vue安装.创建vue项目 nvm作用:可以管理多个版本的node,切换node版本,下载node. 前情提要 参 考:https://zhuanlan.zhihu.com/p/51 ...
- App性能指标(安装、冷启动、卸载、平均内存/cpu/fps/net)测试记录
[需求背景] 需要针对产品以及竞品做出横向对比,输出对应的比对测试报告,供产研进行产品性能优化依据 [测试方案] 对于主流的厂商和系统版本进行多维度的横向对比 厂商:华为系.小米系.蓝绿系.三星系.苹 ...
- Python面试题——网络与并发编程
1.python的底层网络交互模块有哪些? socket, urllib,urllib3 , requests, grab, pycurl 2.简述OSI七层协议. OSI七层协议是一个用于计算机或通 ...
- CSS 多行文本超链接下划线动效
先看效果 乍一看,是不是感觉很简单,仔细一瞅发现事情好像没有那么简单. 如果十分钟还没想出怎么实现,那就把简历上的"精通css"改成"了解css"-- 大部分人 ...
- 13. 从零开始编写一个类nginx工具, HTTP中的压缩gzip,deflate,brotli算法
wmproxy wmproxy将用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,后续将实现websocket代理, 内外网穿透等, 会将实现过程分享出来, 感 ...