一文解开主流开源变更数据捕获技术之Flink CDC的入门使用
@
概述
定义
flink-cdc-connectors 官网 https://github.com/ververica/flink-cdc-connectors 源码release最新版本2.4.0
flink-cdc-connectors 文档地址 https://ververica.github.io/flink-cdc-connectors/master/
flink-cdc-connectors 源码地址 https://github.com/ververica/flink-cdc-connectors
CDC Connectors for Apache Flink 是Apache Flink的一组源连接器,使用更改数据捕获(CDC)从不同的数据库摄取更改,其集成了Debezium作为捕获数据变化的引擎,因此它可以充分利用Debezium的能力。
Flink CDC是由Flink社区开发的flink-cdc-connectors 的source组件,基于数据库日志的 Change Data Caputre 技术,实现了从 MySQL、PostgreSQL 等数据库全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。
什么是CDC?
这里也简单说明下,CDC为三个英文Change Data Capture(变更数据捕获)的缩写,核心思想是监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其它服务进行订阅及消费。
CDC的分类
CDC主要分为基于查询的CDC和基于binlog的CDC,两者之间区别主要如下:
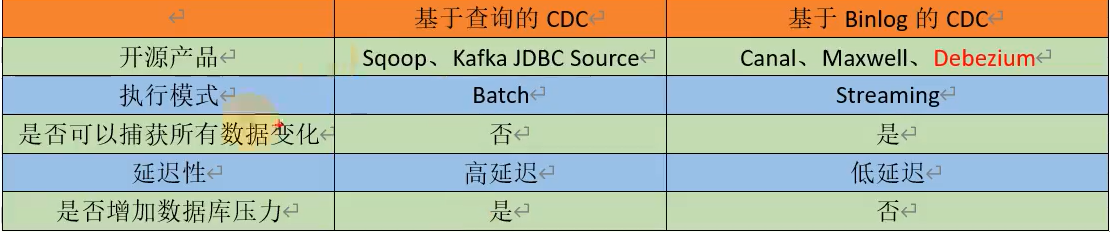
特性
- 支持读取数据库快照,即使发生故障,也只进行一次处理,继续读取事务日志。
- 数据流API的CDC连接器,用户可以在单个作业中消费多个数据库和表上的更改,而无需部署Debezium和Kafka。
- 用于表/SQL API的CDC连接器,用户可以使用SQL DDL创建CDC源来监视单个表上的更改。
应用场景
- 数据分发,将一个数据源分发给多个下游,常用于业务解耦、微服务。
- 数据集成,将分散异构的数据源集成到数据仓库中,消除数据孤岛,便于后续的分析。
- 数据迁移,常用于数据库备份、容灾等。
支持数据源
CDC Connectors for Apache Flink支持从多种数据库到Flink摄取快照数据和实时更改,然后转换和下沉到各种下游系统
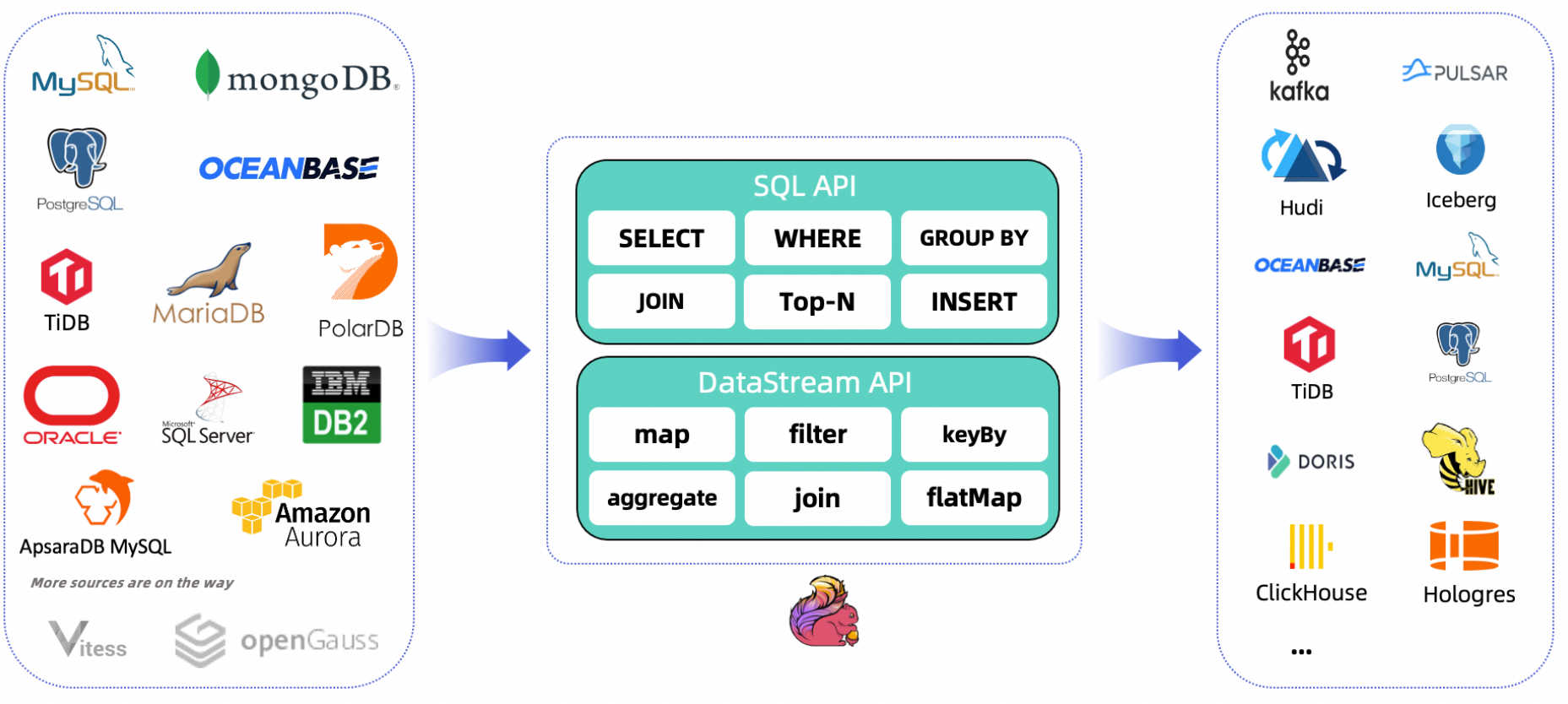
支撑数据源包括如下:
实战
Flink DataStream方式代码示例
这里以MySQL作为数据源为例,通过flink-connector-mysql-cdc实现数据变更获取,先准备MySQL环境,这里复用前面<<实时采集MySQL数据之轻量工具Maxwell实操>>的文章环境,数据库有两个my_maxwell_01,my_maxwell_02,每个数据库都有相同account和product表。pom文件引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itxs.flink</groupId>
<artifactId>flink-cdc-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.17.1</flink.version>
<flink.cdc.version>2.4.0</flink.cdc.version>
<mysql.client.version>8.0.29</mysql.client.version>
<fastjson.version>1.2.83</fastjson.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.client.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink.cdc.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
创建DataStreamDemo.java,
package cn.itxs.cdc;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class DataStreamDemo {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("mysqlserver")
.port(3306)
.databaseList("my_maxwell_01,my_maxwell_02")
.tableList("my_maxwell_01.*,my_maxwell_02.product")
.username("root")
.password("12345678")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将SourceRecord转换为JSON字符串
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 开启checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// 设置平行度为4
.setParallelism(4)
.print().setParallelism(1); // 对sink打印使用并行性1来保持消息顺序
env.execute("Print MySQL Snapshot + Binlog");
}
}
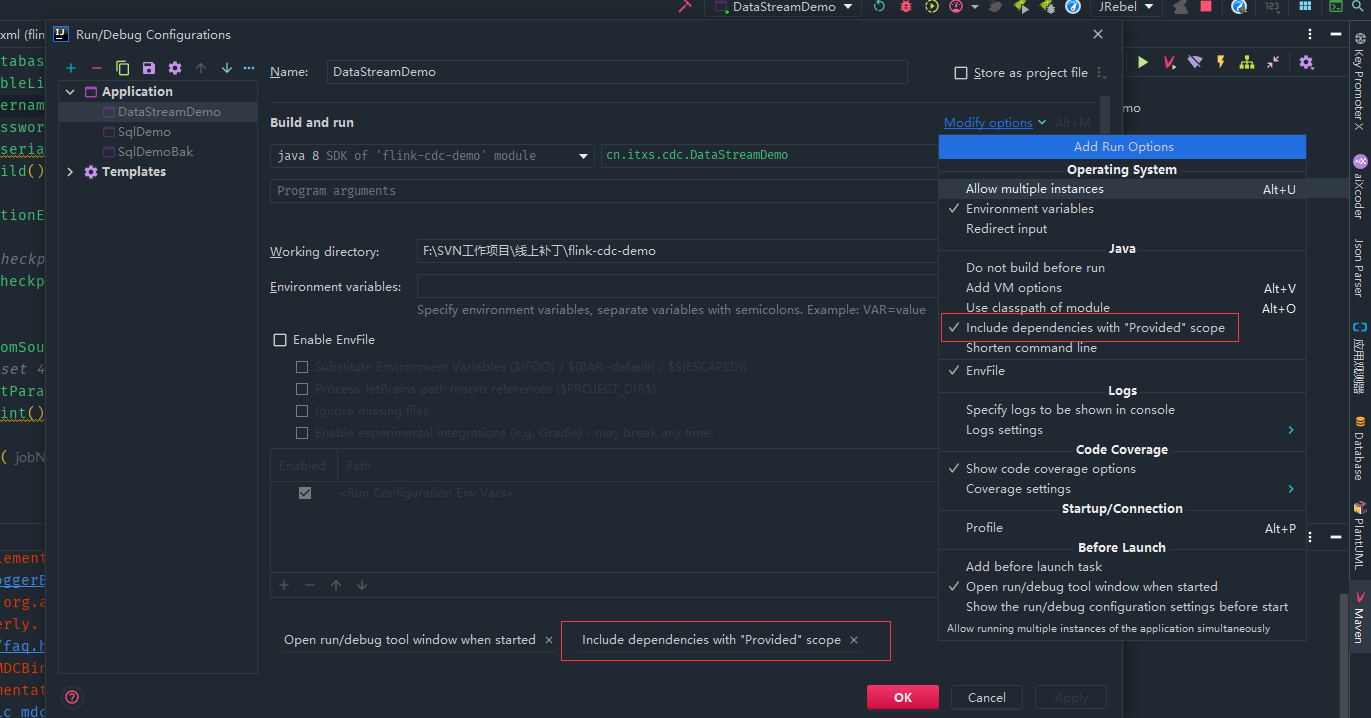
由于上面flink的依赖配置provided,因此在IDEA中启动的话需要勾选下面标红的选项
启动程序,查看日志可以看到从mysql读取目前全量的数据,my_maxwell_02也只读取product表数据

修改两个库的表后可以看到相应修改信息,其中也确认my_maxwell_02的account没有读取变更数据。

{"before":{"id":7,"name":"李丹","age":44},"after":{"id":7,"name":"李丹","age":48},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1687856595000,"snapshot":"false","db":"my_maxwell_01","sequence":null,"table":"account","server_id":1,"gtid":null,"file":"binlog.000025","pos":2798,"row":0,"thread":330184,"query":null},"op":"u","ts_ms":1687856598620,"transaction":null}
{"before":{"id":1,"name":"iphone13","type":1},"after":{"id":1,"name":"iphone14","type":1},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1687856605000,"snapshot":"false","db":"my_maxwell_01","sequence":null,"table":"product","server_id":1,"gtid":null,"file":"binlog.000025","pos":3140,"row":0,"thread":330184,"query":null},"op":"u","ts_ms":1687856608748,"transaction":null}
{"before":{"id":1,"name":"iphone13","type":1},"after":{"id":1,"name":"iphone14","type":1},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1687856628000,"snapshot":"false","db":"my_maxwell_02","sequence":null,"table":"product","server_id":1,"gtid":null,"file":"binlog.000025","pos":3486,"row":0,"thread":330184,"query":null},"op":"u","ts_ms":1687856631643,"transaction":null}
打包后放到集群上,执行
bin/flink run -m hadoop1:8081 -c cn.itxs.cdc.DataStreamDemo ./lib/flink-cdc-demo-1.0-SNAPSHOT.jar

可以看到的日志也成功输出表的全量的日志和刚才修改增量数据

如果需要断点续传可以使用状态后端存储来实现
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointStorage("hdfs://hadoop111:9000/checkpoints/flink/cdc");
checkpointConfig.setMinPauseBetweenCheckpoints(TimeUnit.SECONDS.toMillis(2));
checkpointConfig.setTolerableCheckpointFailureNumber(5);
checkpointConfig.setCheckpointTimeout(TimeUnit.MINUTES.toMillis(1));
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
FlinkSQL方式代码示例
创建SqlDemo.java文件
package cn.itxs.cdc;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class SqlDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
tableEnv.executeSql("CREATE TABLE account (\n" +
" id INT NOT NULL,\n" +
" name STRING,\n" +
" age INT,\n" +
" PRIMARY KEY(id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = 'mysqlserver',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = '12345678',\n" +
" 'database-name' = 'my_maxwell_01',\n" +
" 'table-name' = 'account'\n" +
");");
Table table = tableEnv.sqlQuery("select * from account");
DataStream<Row> rowDataStream = tableEnv.toChangelogStream(table);
rowDataStream.print("account_binlog====");
env.execute();
}
}
启动程序,查看日志可以看到从mysql读取my_maxwell_01库account表的全量的数据,修改表数据也确认读取变更数据。

- 本人博客网站IT小神 www.itxiaoshen.com
一文解开主流开源变更数据捕获技术之Flink CDC的入门使用的更多相关文章
- SQL Server 变更数据捕获(CDC)监控表数据
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 实现过程(Realization) 补充说明(Addon) 参考文献(References) ...
- SQL Server 变更数据捕获(CDC)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/字段/对象更改 概述 变更数据捕获用于捕获应用到 SQL Server 表中的插入.更新和删除活动,并以易于使用的关系格式提供这些 ...
- SQL Server 2008中新增的 1.变更数据捕获(CDC) 和 2.更改跟踪
概述 1.变更数据捕获(CDC) 每一次的数据操作都会记录下来 2.更改跟踪 只会记录最新一条记录 以上两种的区别: http://blog.csdn.n ...
- SQL Server 2008中新增的变更数据捕获(CDC)和更改跟踪
来源:http://www.cnblogs.com/downmoon/archive/2012/04/10/2439462.html 本文主要介绍SQL Server中记录数据变更的四个方法:触发器 ...
- CDC变更数据捕获
CDC变更数据捕获 (2013-03-20 15:25:52) 分类: SQL SQL Server中记录数据变更的四个方法:触发器.Output子句.变更数据捕获(Change Data Cap ...
- SqlServer 2014该日志未截断,因为其开始处的记录是挂起的复制操作或变更数据捕获
环境:AlwaysOn集群 操作系统:Windows Server 2008 R2 数据库: SQL Server 2014 错误提示:“该日志未截断,因为其开始处的记录是挂起的复制操作或变更数据捕获 ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- CDC-更改数据捕获存储过程 (Transact-SQL)-学习
背景: 在SQLServer2008之前,对数据变更的捕获通常使用触发器.时间戳等低效高成本的功能来实现,所以很多系统都没有做数据变更或者仅仅对核心表做监控. 适用环境: 仅在SQLServer200 ...
- 开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop.Spark.Hbase.Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索. 开源大数据技术专场下午场在 ...
- ATC:一个能将主流开源框架模型转换为昇腾模型的神奇工具
摘要:本文介绍了昇腾CANN提供的模型转换工具ATC,介绍了其功能.架构,并以具体样例介绍了该工具的基本使用方法以及常用设置. 本文分享自华为云社区<使用ATC工具将主流开源框架模型转换为昇腾模 ...
随机推荐
- [Git/SVN] Gitee使用教程
1 Gitee Gitee 提供免费的 Git 仓库,还集成了代码质量检测.项目演示等功能. 对于团队协作开发,Gitee 还提供了项目管理.代码托管.文档管理的服务,5 人以下小团队免费. CASE ...
- [操作系统]记一次未尽的三星 Galaxy A6s(SM-G6200)刷机过程
给女王大人刷机,第一次刷机,很遗憾,遇到了三星的"锁三键"问题,没有搞成.记录一下这个过程所涉猎的一些刷机基本知识,不妨当作一次学习过程. 1 刷机过程 Step1 查看手机基本信 ...
- 四月七号java基础学习
1.数据类型分为基本数据类型以及引用数据类型 基本数据类型有整型.浮点型.字符型.布尔型 引用数据类型有类.数组以及接口 2.常量的声明需要用关键字final来标识 3.JAVA语言的变量名称由数字, ...
- LeeCode 91双周赛复盘
T1: 不同的平均值数目 思路:排序 + 双指针 + 哈希存储 public int distinctAverages(int[] nums) { Arrays.sort(nums); Set< ...
- xtrabackup: error: xb_load_tablespaces() failed with error code 57
问题描述:在数据库上运行xtrabackup备份脚本出现的一些报错 DB_version:mysql8.0.26 Xtrabackup:percona-xtrabackup-8.0.27-19-Lin ...
- laravel实现大数据csv导出
首先说明几点: excel格式的文件最大支持100万的数据,所以不考虑使用excel格式 laravel的toArray()方法有内存泄露,所以大量数据导出不能使用. 当然要使用chunk方法查询数据 ...
- 【Git GitHub Idea集成】
1 Git介绍 分布式版本控制工具 VS 集中式版本控制工具 git是一个免费开源的分布式版本控制系统,可以快速高效地处理从小型到中型的各种项目. 1.1 Git进行版本控制 集中式版本控制工具:如C ...
- 手动编写Swagger文档与部署指南
Swagger介绍 在Web开发中,后端开发者在完成接口开发后,需要给前端相应的接口使用说明,所以一般会写一份API文档.一般来说,有两种方式提供API接口文档,一种是利用插件在代码中自动生成,另一种 ...
- 23.04.06_blog能被搜索到
博客优化内容 对于刚建立的博客来说,谷歌往往不能或者不会收录你的博客,为了使自己的博客可以被谷歌所检索到.我们需要主动向谷歌提供网址信息. 提交到百度搜索 访问百度搜索资源平台官网,注册或者登陆百度账 ...
- Java并发(三)----创建线程的三种方式及查看进程线程
一.直接使用 Thread // 创建线程对象 Thread t = new Thread() { public void run() { // 要执行的任务 } }; // ...