[转帖]Percolator - 分布式事务的理解与分析
https://zhuanlan.zhihu.com/p/261115166
Percolator - 分布式事务的理解与分析
概述
一个web页面能不能被Google搜索到,取决于它是否被Google抓取并存入了它的倒排索引。Google管理着万亿级别的倒排索引,并且每天都有着几十亿级别的数据更新。通过MapReduce批处理,可以高效地将整个数据库全量构建成倒排索引。但是对于增量数据来说,全量构建是不经济且不及时的。所以Google研发了Percolator,用于处理这些大规模的增量数据。
为了确保系统故障时的数据一致性,Percolator在BigTable的基础之上,提供了Snapshot Isolation语义的分布式事务能力。本文讨论的重点就在于:Percolator如何基于BigTable的单行事务和一个Timestamp Oracle(全局授时服务器,后称TSO)实现上述的分布式事务。
模型
Percolator实现分布式事务主要基于3个实体:Client、TSO、BigTable。
- Client是事务的发起者和协调者
- TSO为分布式服务器提供一个精确的,严格单调递增的时间戳服务。
- BigTable是Google实现的一个多维持久化Map,格式如下:
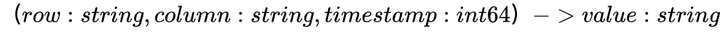
实际上Percolator存储一列数据的时候,会在BigTable中存储多列数据:
- data列: 存储 value
- lock列: 存储用于分布式事务的锁信息
- write列:存储用于分布式事务的提交时间(commit_timestamp)

对于上表来说,它表示的是k1这一行,c1这一列数据的3个版本(timestamp分别为5、6、7)。
因为write列中,最新的数据是data@5,表明最新的一次commit_timestamp为5。所以看timestamp=5时,data列的数据为foobar。并且这一行这一列最新的数据也为:foobar。
在timestamp=7的时候,data列的数据被改为了barbaz,lock列也被标记为锁定,意味着此时有一个事务正在修改数据。一旦这个数据成功提交,在未来个某个timestamp上,会将它的write列写为7,并把7中的lock列清理掉。
可以看出,Percolator使用了lock和write这额外的2列来表达事务的状态。下面会具体说明,如何使用这2列作为元数据来实现分布式事务。
“写”事务
Percolator的分布式写事务是由2阶段提交(后称2PC)实现的。不过它对传统2PC做了一些修改,可见后文的“Percolator特色的2PC”。
一个写事务可以包含多个写操作,事务开启时,Client会从TSO处获取一个timestamp作为事务的开始时间(后称为start_ts)。在提交之前,所有的写操作都只是缓存在内存里。提交时会经过prewrite阶段和commit阶段。
Prewrite阶段
- 随机取一个写操作作为primary,其他的写操作则自动成为secondary。Percolator总是先操作primary,“Percolator特色的2PC”会讨论到为什么总是先操作primary。
- 冲突检测:
- 如果在start_ts之后,发现write列有数据,则说明有其他事务在当前事务开始之后提交了。这相当于2个事务的并发写冲突,所以需要将当前事务abort。
- 如果在任何timestamp上发现lock列有数据,则有可能有其他事务正在修改数据,也将当前事务abort。当然也有可能另一个事务已经因为崩溃而失败了,但lock列还在,对于这一问题后面的故障恢复会讨论到。
- 锁定和写入:对于每一行每一列要写入的数据,先将它锁定(通过标记lock列,secondary的lock列会指向primary),然后将数据写入它的data列(timestamp就是start_ts)。此时,因为该数据的write列还没有被写入,所以其他事务看不到这次修改。
对于同一个写操作来说,data、lock、write列的修改由BigTable单行事务保证事务性。
由冲突检测的b可以推测:如果有多个并发的大事务,并且操作的数据有重合,则可能会频繁abort事务,这会是一个问题。在TiDB的改进中会谈到它们怎么解决这一问题。
Commit阶段
- 从TSO处获取一个timestamp作为事务的提交时间(后称为commit_ts)。
- 提交primary, 如果失败,则abort事务:
- 检查primary上的lock是否还存在,如果不存在,则abort。(其他事务有可能会认为当前事务已经失败,从而清理掉当前事务的lock)
- 以commit_ts为timestamp, 写入write列,value为start_ts。清理lock列的数据。注意,此时为Commit Point。“写write列”和“清理lock列”由BigTable的单行事务保证ACID。
- 一旦primary提交成功,则整个事务成功。此时已经可以给客户端返回成功了。secondary的数据可以异步的写入,即便发生了故障,此时也可以通过primary中数据的状态来判断出secondary的结果。具体分析可见故障恢复。
“读”事务
在早期的SQL标准中定义的四个事务隔离级别,只适用于基于锁的事务并发控制。后来有人写了一篇论文 A Critique of ANSI SQL Isolation Levels 来批判 SQL 标准对隔离级别的定义,并在论文里提到了一种新的隔离级别 —— Snapshot Isolation(快照隔离)。在Snapshot Isolation下,不会出现脏读、不可重复度和幻读的问题。并且读操作不会被阻塞,对于读多写少的应用,Snapshot Isolation是非常好的选择。所以,主流数据库都实现了Snapshot Isolation。更多关于Snapshot Isolation的内容和历史,可以查阅《Design Data-Intensive Applications》第7章第2节。
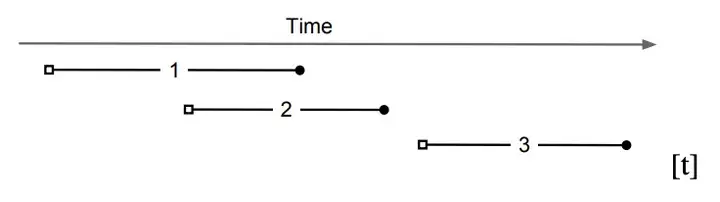
事务隔离级别,实际上规定的就是事务之间的可见行。对于Snapshot Isolation来说:事务只能看到早于它开始时刻之前提交的其他事务。
以下图为例:事务2看不到事务1的修改,因为事务1在事务2开始之后才提交;事务3可以看到事务1和事务2的修改,因为它们在事务3开始之前提交。PS:因为事务1和事务2是并发的,如果它们操作的数据有重合,则至少有一个事务会回滚。
精确地获取事务的start_ts和commit_ts是很重要的。因为它关系着事务之间的可见行,以及决定了多个事务是否并行。Percolator使用Timestamp Oracle模块来提供start_ts和commit_ts。
分布式下snapshot-read存在的问题
尽管我们可以通过TSO获取到精确的start_ts和commit_ts,但还是可能出现一个小问题:事务实际执行的顺序可能和时间戳的顺序不一致!
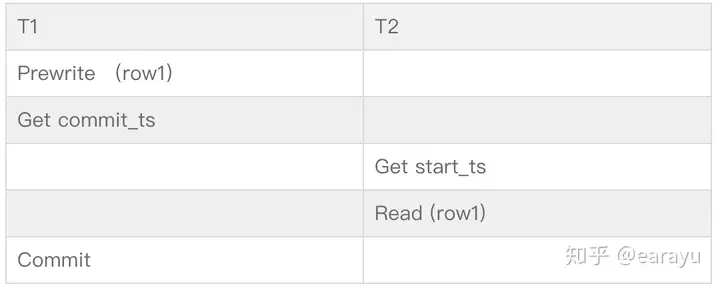
举个例子:T1的commit_ts < T2的start_ts, T2执行Read的时候,T1还没commit完成。按照标准,T2应该需要可以读取到T1的更改,但实际上因为T1还没有commit。
Percolator的解法是:
- 让“prewrite阶段”先于(happens-before)“获取commit_ts”。所以在commit_ts之后,prewrite的数据必然被锁定了。
- 如果读取时,发现当前数据已被锁定(锁定意味着其他写事务正在执行),则等待并重试。当然也有可能另一个事务已经崩溃了,后面会谈到。
对于上面的例子来说,T2执行到Read时,发现row1被T1锁住了,就会等待直到T1 commit完成。这样T2就能读取到T1 commit的结果了,符合了snapshot-read的标准。
Percolator特色的2PC
不同于传统意义上的2PC,在Percolator中貌似看不到Transactional Coordinator的角色。其实只要是2PC都需要Coordinator,只是Percolator把Coordinator的职责作了更进一步的细分,从而不再需要一个中心化的节点。
在2PC中,最关键的莫过于Commit Point(提交点)。因为在Commit Point之前,事务都不算生效,并且随时可以回滚。而一旦过了Commit Point,事务必须生效,哪怕是发生了网络分区、机器故障,一旦恢复都必须继续下去。
传统的2PC的Commit Point在写本地磁盘的那一刻;Percolator 2PC的Commit Point在完成BigTable事务的那一刻。为什么会有这样的区别?因为传统的Coordinator是可恢复的,参与者可以在Coordinator恢复后去询问事务的结果。而Percolator Client很可能是不可恢复的,并且它的恢复也是没有意义的。
| 传统Coordinator | Percolator Client | |
| 发送Prewrite请求 | 无本质区别 | |
| 判定是否可以Commit | 无本质区别 | |
| 写Commit Log(提交点) | 写本地磁盘 | 写primary的write列 |
| 发送Commit请求 | 发送RPC | 写Secondary的write列 |
| rollback/roll-forward | coordinator发送RPC/participant主动查询 | 懒处理+通过lock和write列状态判断 |
PS:至于上文提到的,Percolator总是先操作primary,最重要的原因在于Percolator把“写primary的write列、清理lock列”作为了commit point。
故障恢复
首先明确一点:一个事务是否执行成功,只取决于Commit Point。一旦一个事务的Commit Point确定,所有写操作都最终必须确定且必须一致地接受。传统2PC从Coordinator处获取全局最终一致性,而Percolator的2PC就只能从data、lock、write这3列的状态来判断全局最终一致性了。如何从这几列数据判断出事务的提交状态,就是问题的关键所在。
事务崩溃的边界如何划分?
判断出事务的提交状态后,接着就是故障恢复。Percolator使用了懒处理的方式。一个事务执行时,会判断先前事务的状态,如果发现先前的事务故障了,则帮助它进行相应的故障恢复。这边是没有办法100%确定某个事务崩溃的,比如事务A因为网络分区而阻塞了,那阻塞多久算事务A失败呢?量变和质变的边界不是100%清晰。或者说,量变到质变的转化不是客观存在的,而是由第三方事务来决定的!Percolator只能猜测(原文suspect)一个事务失败,从而对它进行abort或者rollback/roll-forward。同时Percolator也采用了一个lightweight lock service来使这个猜测过程更迅速。
PS:回头可以发现,Percolator 2PC的commit阶段,会先判断primary上的锁是否还在。就是因为任意事务可能会被其他事务认为已经崩溃了,从而被abort。
如何判断事务的最终状态
想象一下事务B正在执行,它要操作的一行数据只有可能是2种状态:有锁和无锁。有锁状态下,一定是有其他事务A并行,事务A可能正在运行,也有可能崩溃了。无锁状态下,可能是无其他事务并行,也有可能是事务崩溃并且锁已经被其他事务清理掉了。
PS:这里的有锁和无锁,全部指代的是primary的lock列是否有数据。如果事务B操作的是secondary,需要根据secondary的lock列寻址到相应的primary的lock列。
如下图:
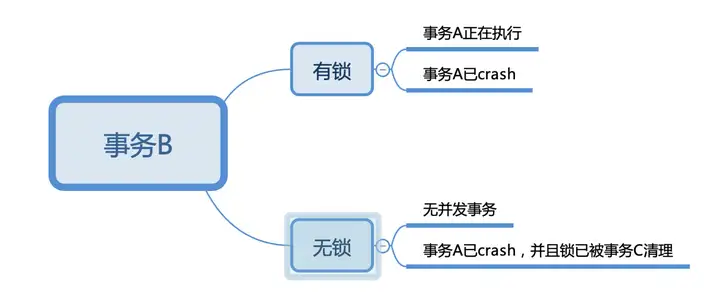
- 事务B发现有锁,且该锁未超时,则认为事务A正在执行。
- 事务B发现有锁,且该锁超时,则认为事务A已crash。此时事务B可以将事务A rollback,并继续自己的事务。如果后续事务A又恢复了,它在提交前一定会检查自己的primary lock是否在存在。所以事务A和B永远只有一个能够提交成功。
- 事务B发现无锁,则可能无并发事务、或者事务A已cresh但已被事务C清理。
TiDB的对“写-写冲突”的改进
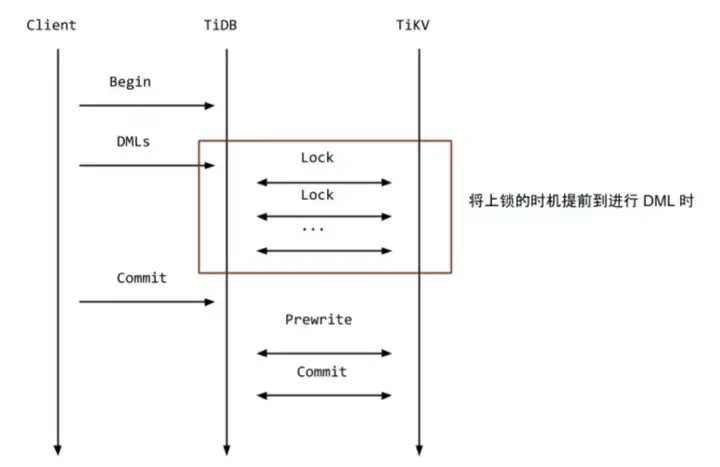
首先TiDB提供了良好的控制台工具,可以查看数据库的事务冲突数量、事务重试数量以及事务延迟。根据告警可以定位到数据,从而找到对应的代码,最终可以尝试通过修改代码解决问题。TiDB在v3.0.8之后也提供了悲观事务模型:会在每个 DML 语句执行的时候,加上悲观锁,用于防止其他事务修改相同 Key,从而保证在最后提交的 prewrite 阶段不会出现写写冲突的情况。
原先Percolator的DML语句只是缓存在内存里,直到Prewrite阶段才会进行冲突检测和加锁:
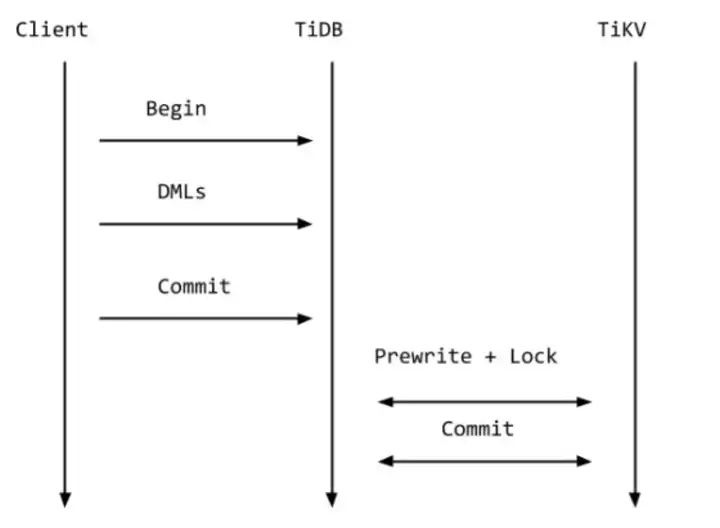
对于乐观锁的实现,TiDB官方描述如下:在悲观事务模型下,DML语句在最开始就必须进行冲突检测和加锁,这里的悲观锁的格式和乐观事务中的锁几乎一致,但是锁的内容是空的,只是一个占位符,待到 Commit 的时候,直接将这些悲观锁改写成标准的 Percolator 模型的锁,后续流程和原来保持一致即可。对于读请求,遇到这类悲观锁的时候,不用像乐观事务那样等待解锁,可以直接返回最新的数据即可(至于为什么,读者可以仔细想想)。
我的想法是:
在乐观模型下,Read看到锁必须等待是因为,Read不能确定是否会有一个commit_ts小于它start_ts的事务,会在它读取之后提交。
但在悲观模型下,Read看到的lock列可能只是一个占位符,也可能是Percolator模型的锁。如果是一个占位符的话,那表示此时该事务的commit_ts必定还没有获取,所以无需等待该事务。如果是Percolator模型的锁的话,则还需要像原本一样处理。
为了避免悲观事务模型引入的死锁,TiDB实现了一个死锁检测机制。事务1对A上了锁后,如果另外一个事务2对A进行等待,那么就会产生一个依赖关系:事务2依赖事务1,如果此时事务1打算去等待B(假设此时事务2已经持有了B的锁),那么死锁检测模块就会发现一个循环依赖,然后中止(或者重试)这个事务就好了,因为这个事务并没有实际的prewrite和commit,所以这个代价是比较小的。
总结
Percolator基于BigTable单行事务实现的分布式事务,其实是一个乐观事务模型。只有在事务提交时,才会检测写-写冲突。Percolator事务模型的优点在于原理简单方便理解,不再需要一个中心化的单独Coordinator,而是把Coordinator角色的职责进行细分,把能持久化的部分交给BigTable处理,后续也不再依赖Client的恢复。但它的缺点也是显而易见的:Client和BigTable之间的RPC、BigTable和ChunkServer之间的RPC都会比较耗费网络资源。TSO是一个中心化的点。并发事务很多的时候,会占用很多内存。并发大事务可能会频繁冲突,而重试有可能会导致雪崩效应(这时候就用悲观事务模型会更好)。懒处理事务crash导致一个事务的延迟可能会比较高。
不过Percolator论文只是指明了大的方向,很多细节应该也还是存在优化空间的。
彩蛋
在Percolator中,start_ts在事务最开始的时候获取,而Snapshot Isolation隔离级别决定了该事务只能看到commit_ts先于start_ts的事务的修改。
于是对于TiDB来说,下面2个并行的事务,T2能看到的记录只有5行,因为它的start_ts早与T1的commit_ts。
但是对于MySQL来说,它能看到6行。因为它的start_ts开始于第一条SQL语句执行的那一刻。
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
| T1 | T2 |
| Begin | |
| select count(*); -> 5 | Begin |
| insert; | |
| select count(*); MySQL -> 6 TiDB -> 5 |
|
| commit; | |
| commit |
参考资料
Large-scale Incremental Processing Using Distributed Transactions and Notifications
Bigtable: A Distributed Storage System for Structured Data
[转帖]Percolator - 分布式事务的理解与分析的更多相关文章
- 【转帖】分布式事务之解决方案(XA和2PC)
分布式事务之解决方案(XA和2PC) https://zhuanlan.zhihu.com/p/93459200 博彦信息技术有限公司 java工程师 3. 分布式事务解决方案之2PC(两阶段提交 ...
- TX-LCN5.0.2分布式事务框架源码分析-关键线索罗列-txc部分
1.注解TxcTransaction2.在其注解接口附近查找aop配置:TransactionAspect3.runTransaction是在执行事务业务代码时的包装逻辑4.transactionSe ...
- Google关于Spanner的论文中分布式事务的实现
Google关于Spanner的论文中分布式事务的实现 Google在Spanner相关的论文中详细的解释了Percolator分布式事务的实现方式, 而且用简洁的伪代码示例怎么实现分布式事务; Pe ...
- 分布式事务解决方案,中间件 Seata 的设计原理详解
作者:张乘辉 前言 在微服务架构体系下,我们可以按照业务模块分层设计,单独部署,减轻了服务部署压力,也解耦了业务的耦合,避免了应用逐渐变成一个庞然怪物,从而可以轻松扩展,在某些服务出现故障时也不会影响 ...
- 开发者说 | 分布式事务中间件 Seata 的设计原理
导读 微服务架构体系下,我们可以按照业务模块分层设计,单独部署,减轻了服务部署压力,也解耦了业务的耦合,避免了应用逐渐变成一个庞然怪物,从而可以轻松扩展,在某些服务出现故障时也不会影响其它服务的正常运 ...
- 分布式事务框架-seata初识
一.事务与分布式事务 事务,在数据库中指的是操作数据库的最小单位,往大了看,事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消. 那为什么会有分布式事务呢 ...
- MySQL数据库分布式事务XA优缺点与改进方案
1 MySQL 外部XA分析 1.1 作用分析 MySQL数据库外部XA可以用在分布式数据库代理层,实现对MySQL数据库的分布式事务支持,例如开源的代理工具:ameoba[4],网易的DDB,淘宝的 ...
- DTP模型之一:(XA协议之三)MySQL数据库分布式事务XA优缺点与改进方案
1 MySQL 外部XA分析 1.1 作用分析 MySQL数据库外部XA可以用在分布式数据库代理层,实现对MySQL数据库的分布式事务支持,例如开源的代理工具:ameoba[4],网易的DDB,淘宝的 ...
- 分布式事务之深入理解什么是2PC、3PC及TCC协议?
导读 在上一篇文章<[分布式事务]基于RocketMQ搭建生产级消息集群?>中给大家介绍了基于RocketMQ如何搭建生产级消息集群.因为本系列文章最终的目的是介绍基于RocketMQ的事 ...
- 分布式事务实现-Percolator
Google为了解决网页索引的增量处理,以及维护数据表和索引表的一致性问题,基于BigTable实现了一个支持分布式事务的存储系统.这里重点讨论这个系统的分布式事务实现,不讨论percolator中为 ...
随机推荐
- JPA object references an unsaved transient instance - save the transient instance before flushing
nested exception is org.springframework.dao.InvalidDataAccessApiUsageException: org.hibernate.Transi ...
- NoClassDefFoundError: javax/el/ELManager
Caused by: java.lang.NoClassDefFoundError: javax/el/ELManager at org.hibernate.validator.messageinte ...
- JavaImprove--Lesson01--枚举类,泛型
一.枚举 认识枚举类 枚举是一种特殊的类 枚举的格式: 修饰符 enmu 枚举类名{ 名称1,名称2: 其它成员 } //枚举类 public enum A { //枚举类的第一列必须是罗列枚举 ...
- HDU 3660 树形DP
原题地址 题意 Alice与Bob在一棵树的树根一同出游,两人从Bob开始轮换选择道路一直走到树叶,Alice会尽可能使走过的总长最小,而Bob相反.不过他们都不能让总长落到[l, r]之外 现在给出 ...
- 华为云GaussDB(for openGauss)商用啦!
摘要:截止目前,华为消费者云已在GaussDB(for openGauss)上线了40+业务,包括弹幕&评论.云空间.地理大数据等业务系统,实时为5亿+用户提供高效服务. 生命在于运动,健康打 ...
- vue2升级vue3:class component的遗憾
在vue2,class 写法真的非常爽 import { Component as tsc } from 'vue-tsx-support'; import { Component, Watch } ...
- Nginx在windows下常用命令
cmd 进入Nginx解压目录 执行以下命令 start nginx : 启动nginx服务 nginx -s reload :修改配置后重新加载生效 nginx -s reopen :重新打开日志文 ...
- docker-compose部署SpringCloud
1.安装 docker-compose 将 docker-compose-Linux-x86_64 传到 /usr/local/bin 目录下,并改名为 docker-compose 2.设置权限 ...
- Pycharts在测试工作中的应用
Pycharts在测试工作中的应用 pycharts是一个基于Python的数据可视化库,支持多种折线图.柱状图.饼图等.Pycharts底层依赖于Echarts pip install pyecha ...
- 记录一次Java内存泄露分析过程
版权说明: 本文章版权归本人及博客园共同所有,转载请在文章前标明原文出处( https://www.cnblogs.com/mikevictor07/p/13032635.html ),以下内容为个人 ...