[转帖]003、体系结构之TiKV持久化
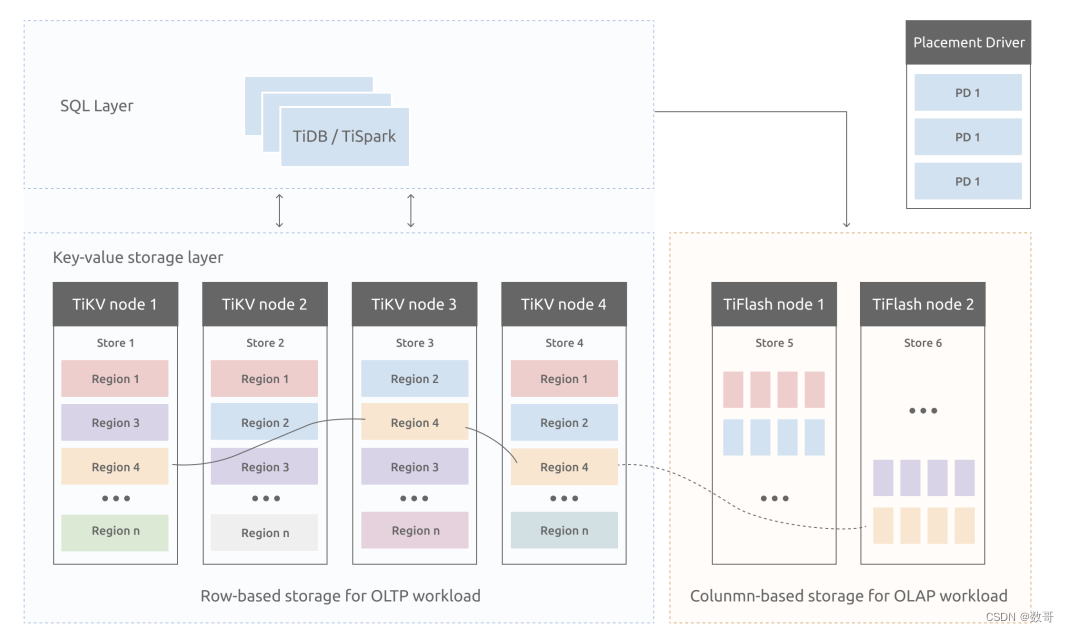
TiKV架构和作用
- 数据持久化
- 分布式一致性
- MVCC
- 分布式事务
- Coprocessor
coprocessor : 协同处理器。 可以将一些SQL计算交给TiKV处理。不需要将TiKV所有数据通过网络发送给TiDB Server
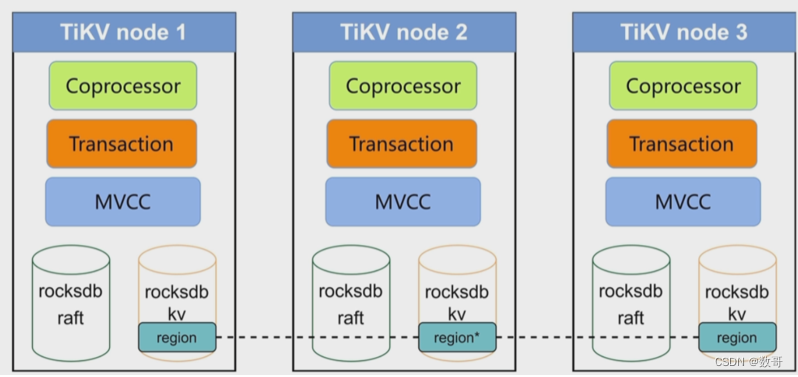
RocksDB
任何持久化的存储引擎,数据终归要保存在磁盘上,TiKV 也不例外。但是 TiKV 没有选择直接向磁盘上写数据,⽽是把数据保存在 RocksDB 中,具体的数据落地由RocksDB 负责。这个选择的原因是开发⼀个单机存储引擎⼯作量很⼤,特别是要做⼀个⾼性能的单机引擎,需要做各种细致的优化,⽽ RocksDB 是由 Facebook 开源的⼀个⾮常优秀的单机 KV 存储引擎,可以满⾜ TiKV 对单机引擎的各种要求。这⾥可以简单的认为 RocksDB 是⼀个单机的持久化 Key-Value Map。
- RocksDB 针对Flash存储进行优化,延迟极小,使用LSM存储引擎
- 高性能的Key-Value数据库
- 完善的持久化机制,同时保证性能和安全性
- 良好的支持范围查询
- 为需要存储TB级别数据到本地FLASH和RAM的应用服务器设计
- 针对存在在高速设置的中小键值进行优化,可以存储在FLASH或者直接存储在内存
- 性能随CPU数量线提升,对多核系统友好
Key-Value Pairs(键值对)
作为保存数据的系统,⾸先要决定的是数据的存储模型,也就是数据以什么样的形式保存下来。TiKV 的选择是 Key-Value 模型,并且提供有序遍历⽅法。
TiKV 数据存储的两个关键点:
- 这是⼀个巨⼤的 Map,也就是存储的是 Key-Value Pairs(键值对)
- 这个 Map 中的 Key-Value pair 按照 Key 的⼆进制顺序有序,也就是可以 Seek 到某⼀个 Key 的位置,然后不断地调⽤ Next ⽅法以递增的顺序获取⽐这个 Key ⼤ 的 Key-Value。
RocksDB写⼊
它可做到一个类似顺序写的效果
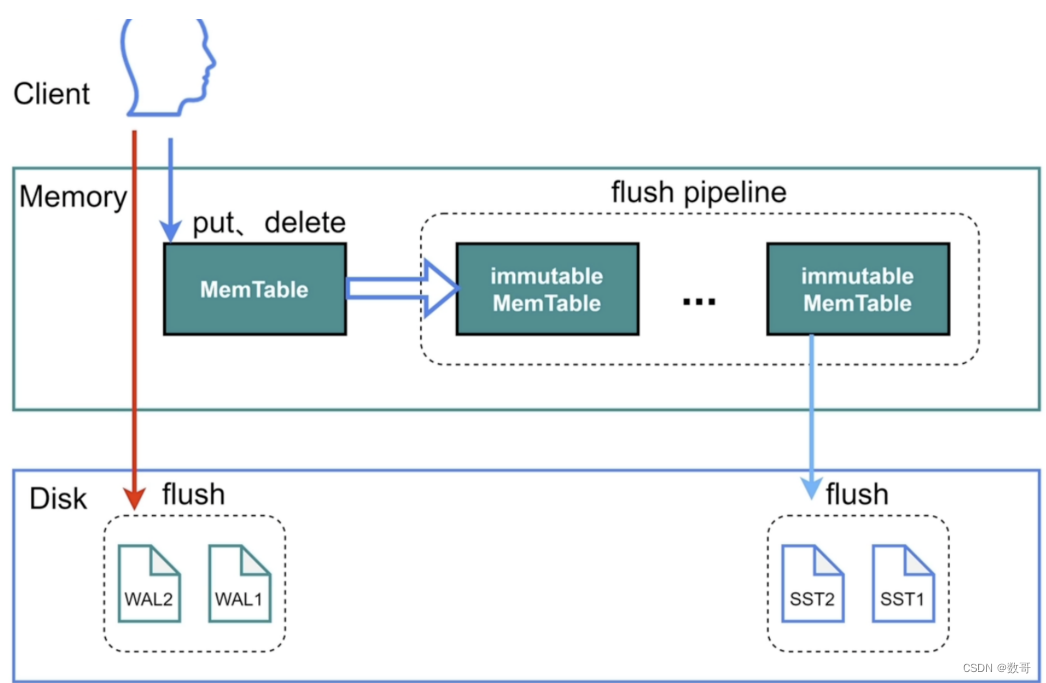
- wal日志是会持久化到disk上的。
- 是数据的put(新增),数据写到memTable(类似sga) ,然后数据转存到到immutable memtable(例如memTable满了),当memtable里的数据追加达到write_buffer_size大小,然后再根据一定机制刷新到磁盘。,就转存到immutable (不能动,不能改的意思)。 然后重新开辟MemTable。. 这样可以避免memTable 同步到磁盘io的瓶颈。 因为它是同步到immutable memTable(内存中)。 当然也有可能 immutable memTable这个因为memTable 太频繁导致限流。
- 读和写,它都是优先从MemTable,因为是最新的。
- immutable 就是同步到文件的区域。 它的作用其实就是 减少 memtable 同步唰到磁盘的io。 减少客户端的阻塞。防止写阻塞。
注意:
immutable一个满了就会往磁盘写。当同步磁盘速度太慢,例如达到5个就会做流控。
如果写入的速度太快(客户端到memtable),而刷盘的速度相对较慢的时候(immutable到磁盘),它会进行限速的动作(write stall),限制写入的速度。
压缩合并

在磁盘当中,会有压缩算法。 数据是有等级之分。
其中level 0 就是immutable复制。 RockDB 对于写的非常友好。
当有4份immutable MemTable 进行入level 0之后.然后将它们压缩之后的数据放到Level 1中。 如果再有4份,继续合并压缩到level 1中。依次类推
然后level 1中的数据超过256M,则这个层级数据压缩合并到level 2中.
依次类推,下面的等级
RocksDB查询
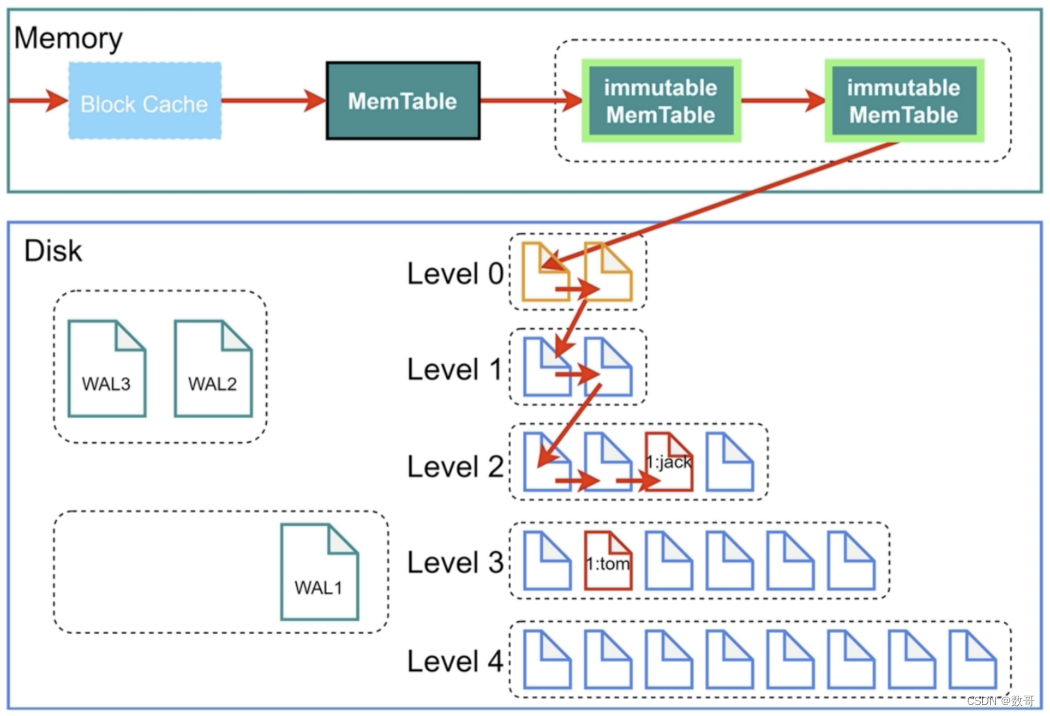
查找顺序就是:
- 先从block cache找,没有就从memtable ->immutable memTable -> level 0 -> level 1…
为了提升查询性能,在每个level 设置了key的范围 。如果不在范围,就找更高级别。这个插叙操作,相较于B+树就会慢一点。
最新的数据 根据箭头来。 读到了最新数据,就没必要读之前的数据了。
key 按照最小值和最大值进行排序的集合。
为了加速还有个布隆过滤器,为每个文件都安装了这个,它的作用就是判断这个集合当中的元素,如果布隆过滤器说这个元素在这个集合当中,有可能不在,有误判的概率,但如果说这个元素不在这个集合当中,则百分百一定不会在。
列簇Column Families
不同的列簇可以用来存储不同的数据,在数据的存储、管理、读写上都可以将数据进行分开。
列簇可以方便对数据进行分片,存储数据时指定列簇,数据可以在内存、磁盘中分开存放。默认列簇是default。

cf1 : (cf1,id,name,age)
cf2 : (cf1,id,addr,tel)
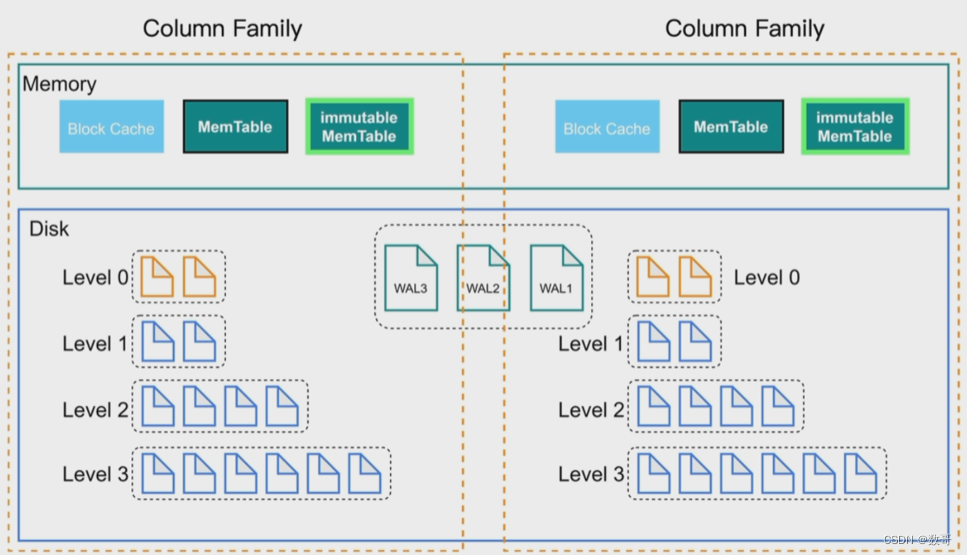
RockDB还有个作用,数据分片。 列簇(CF) : 作用是数据分片的作用。
- 写的时候,可以指定列簇来进行写入。
- rocksDB,有个默认的列簇,default。当不指定的时候,都写入到这。
- 列簇可以指定一张表或多张表的键值对,它们有自己对应的memory 区域,但它们共用相同的wal文件。
TiDB 在 TiKV 提供的分布式存储能⼒基础上,构建了兼具优异的交易处理能⼒与良好的数据分析能⼒的计算引擎。
对于计算层依赖的存储⽅案,这⾥只介绍基于 TiKV 的⾏存储结构。针对分析型业务的特点,TiDB 推出了作为 TiKV 扩展的列存储⽅案TiFlash。
表数据与 Key-Value 的映射关系
这⾥的数据主要包括以下两个⽅⾯:
- 表中每⼀⾏的数据,以下简称表数据
- 表中所有索引的数据,以下简称索引数据
表数据与 Key-Value 的映射关系
在关系型数据库中,⼀个表可能有很多列。要将⼀⾏中各列数据映射成⼀个 (Key,Value) 键值对,需要考虑如何构造 Key。⾸先,OLTP 场景下有⼤量针对单⾏或者多⾏的增、删、改、查等操作,要求数据库具备快速读取⼀⾏数据的能⼒。因此,对应的 Key 最好有⼀个唯⼀ ID(显示或隐式的 ID),以⽅便快速定位。其次,很多OLAP 型查询需要进⾏全表扫描。如果能够将⼀个表中所有⾏的 Key 编码到⼀个区间内,就可以通过范围查询⾼效完成全表扫描的任务。
基于上述考虑,TiDB 中的表数据与 Key-Value 的映射关系作了如下设计:
- 为了保证同⼀个表的数据放在⼀起,⽅便查找,TiDB 会为每个表分配⼀个表ID,⽤ TableID 表示。表 ID 是⼀个整数,在整个集群内唯⼀。
- TiDB 会为表中每⾏数据分配⼀个⾏ ID,⽤ RowID 表示。⾏ ID 也是⼀个整数,在表内唯⼀。对于⾏ ID,TiDB 做了⼀个⼩优化,如果某个表有整数型的主键,TiDB 会使⽤主键的值当做这⼀⾏数据的⾏ ID。
每⾏数据按照如下规则编码成 (Key, Value) 键值对:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
- 1
- 2
其中 tablePrefix 和 recordPrefixSep 都是特定的字符串常量,⽤于在 Key空间内区分其他数据。其具体值在后⾯的⼩结中给出。
索引数据和 Key-Value 的映射关系
TiDB 同时⽀持主键和⼆级索引(包括唯⼀索引和⾮唯⼀索引)。与表数据映射⽅案
类似,TiDB 为表中每个索引分配了⼀个索引 ID,⽤ IndexID 表示。
对于主键和唯⼀索引,需要根据键值快速定位到对应的 RowID,因此,按照如下规
则编码成 (Key, Value) 键值对:
Key:
tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
- 1
- 2
- 3
对于不需要满⾜唯⼀性约束的普通⼆级索引,⼀个键值可能对应多⾏,需要根据键
值范围查询对应的 RowID。因此,按照如下规则编码成 (Key, Value) 键值对:
Key:
tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null
# 对于二级索引,不能通过KV的形式找到某一行
- 1
- 2
- 3
- 4
元信息管理
TiDB 中每个 Database 和 Table 都有元信息,也就是其定义以及各项属性。这些信息也需要持久化,TiDB 将这些信息也存储在了 TiKV 中。
每个 Database / Table 都被分配了⼀个唯⼀的 ID,这个 ID 作为唯⼀标识,并且在编码为 Key-Value 时,这个 ID 都会编码到 Key 中,再加上 m_ 前缀。这样可以构造出⼀个 Key,Value 中存储的是序列化后的元信息。
除此之外,TiDB 还⽤⼀个专⻔的 (Key, Value) 键值对存储当前所有表结构信息的最新版本号。这个键值对是全局的,每次 DDL 操作的状态改变时其版本号都会加 1。⽬前,TiDB 把这个键值对持久化存储在 PD Server 中,其 Key 是"/tidb/ddl/global_schema_version",Value 是类型为 int64 的版本号值。TiDB 采⽤Online Schema 变更算法,有⼀个后台线程在不断地检查 PD Server 中存储的表结构信息的版本号是否发⽣变化,并且保证在⼀定时间内⼀定能够获取版本的变化。
[转帖]003、体系结构之TiKV持久化的更多相关文章
- [转帖]14-使用glusterfs做持久化存储
14-使用glusterfs做持久化存储 https://www.cnblogs.com/guigujun/p/8366558.html 使用glusterfs做持久化存储 我们复用kubernete ...
- [转帖]Java虚拟机(JVM)体系结构概述及各种性能参数优化总结
Java虚拟机(JVM)体系结构概述及各种性能参数优化总结 2014年09月11日 23:05:27 zhongwen7710 阅读数 1437 标签: JVM调优jvm 更多 个人分类: Java知 ...
- [转帖]Redis持久化--Redis宕机或者出现意外删库导致数据丢失--解决方案
Redis持久化--Redis宕机或者出现意外删库导致数据丢失--解决方案 https://www.cnblogs.com/xlecho/p/11834011.html echo编辑整理,欢迎转载,转 ...
- [转帖]超详细的PostgreSQL体系结构总结,值得收藏
超详细的PostgreSQL体系结构总结,值得收藏 https://www.toutiao.com/i6715390855772897800/ 原创 波波说运维 2019-07-26 00:03:00 ...
- 【转帖】史上最全PostgreSQL体系结构
史上最全PostgreSQL体系结构 2019年07月16日 18:00:00 Enmotech 阅读数 35 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出 ...
- [转帖]持久化journalctl日志清空命令查看配置参数详解
持久化journalctl日志清空命令查看配置参数详解 最近 linux上面部署服务 习惯使用systemd 进行处理 这样最大的好处能够 使用journalctl 进行查看日志信息. 今天清理了下 ...
- [转帖]JVM总结--JVM体系结构
JVM总结--JVM体系结构 https://blog.csdn.net/samjustin1/article/details/52215274 需要不断的学习才可以. 2016年08月15日 22: ...
- 003 爬虫持久化的三个不同数据库的python代码
MongoDB import pymongo # 1.连接MongoDB服务 mongo_py = pymongo.MongoClient() print(mongo_py) # 2.库和表的名字:有 ...
- 003 PCI Express体系结构(三)
一.PCI总线的存储器读写总线事务 总线的基本任务是实现数据传送,将一组数据从一个设备传送到另一个设备,当然总线也可以将一个设备的数据广播到多个设备.在处理器系统中,这些数据传送都要依赖一定的规则,P ...
- Redis两种持久化方式(RDB&AOF)
爬虫和转载请注明原文地址;博客园蜗牛:http://www.cnblogs.com/tdws/p/5754706.html Redis所需内存 超过可用内存怎么办 Redis修改数据多线程并发—Red ...
随机推荐
- 容器处于`Pending`状态Warning FailedScheduling <unknown> default-scheduler 0/10 nodes are available
Warning FailedScheduling default-scheduler 0/10 nodes are available: 1 node(s) had taint {agreeml: a ...
- 【K8S系列】如何高效查看 k8s日志
序言 你只管努力,其他交给时间,时间会证明一切. 文章标记颜色说明: 黄色:重要标题 红色:用来标记结论 绿色:用来标记一级论点 蓝色:用来标记二级论点 Kubernetes (k8s) 是一个容器编 ...
- 谈谈muduo库的销毁连接对象——C++程序内存管理和线程安全的极致体现
前言 网络编程的连接断开一向比连接建立复杂的多,这一点在陈硕写的muduo库中体现的淋漓尽致,同时也充分体现了C++程序在对象生命周期管理上的复杂性,稍有不慎,满盘皆输. 为了纪念自己啃下muduo库 ...
- React jsx 语法解析 & 转换原理
jsx介绍 jsx是一种JavaScript的语法扩展(eXtension),也在很多地方称之为JavaScript XML,因为看起就是一段XML语法,用于描述UI界面,并且可以和JavaScrip ...
- 拥抱Serverless释放生产力,探索华为云Serverless车联网最佳实践
华为云Serverless车联网场景解决方案,以FunctionGraph为核心的Serverless化组合方案,使用FunctionGraph.OBS.DIS等技术,可以实现架构的灵活扩展,在出行高 ...
- 测试攻城狮必备技能点!一文带你解读DevOps下的测试技术
[摘要]本文将从DevOps模式下对测试人员的活动的变化,以及常用的测试技术层面进行解读. 项目的软件开发模式主要经历瀑布模型.敏捷开发和DevOps这几个阶段,其中DevOps主要解决开发和运维.运 ...
- AppCube视角浅析: 艾瑞咨询《2022年中国低代码行业研究报告》
摘要:近日,艾瑞咨询发布了<2022年中国低代码行业研究报告>,报告从企业数字化发展背景.低代码的发展路径.应用渗透.市场规模等方面进行深入研究分析,并洞察了发展趋势. 本文分享自华为云社 ...
- appuploader使用教程
appuploader使用教程 转载:appuploader使用教程 目录 问题解决秘籍 登录失败 don't have access,提示没权限或同意协议 上传后在app管理中心找不到版本提交 ...
- 渗透测试 vs 漏洞扫描:差异与不同
渗透测试和漏洞扫描常常被混淆,这两者都通过探索系统来寻找 IT 基础架构中的弱点及易受攻击的地方.阅读本文,带你了解两者之间的差异与不同. 手动 vs 自动 渗透测试是一种手动安全评估方式,网络安全人 ...
- VMware NAT 模式 虚拟机网络电缆被拔出,连不上网
检查服务 VMnetDHCP,VMware NAT Service 服务是否已启动,启动后可以正常使用网络