[转帖]TiDB 查询优化及调优系列(三)慢查询诊断监控及排查
https://zhuanlan.zhihu.com/p/509984029
本章节介绍如何利用 TiDB 提供的系统监控诊断工具,对运行负载中的查询进行排查和诊断。除了 上一章节介绍的通过 EXPLAIN 语句来查看诊断查询计划问题外,本章节主要会介绍通过 TiDB Slow Query 慢查询内存表,以及 TiDB Dashboard 的可视化 Statements 功能来监控和诊断慢查询。
适用于中国出海企业和开发者
Slow Query 慢查询内存表
TiDB 默认会启用慢查询日志,并将执行时间超过规定阈值的 SQL 保存到日志文件。慢查询日志常用于定位慢查询语句,分析和解决 SQL 的性能问题。通过系统表information_schema.slow_query也可以查看当前 TiDB 节点的慢查询日志,其字段与慢查询日志文件内容一致。TiDB 从 4.0 版本开始又新增了系统表 information_schema.cluster_slow_query,可以用于查看全部 TiDB 节点的慢查询。
本节将首先简要介绍慢查询日志的格式和字段含义,然后针对上述两种慢查询系统表给出一些常见的查询示例。
慢查询日志示例及字段说明
下面是一段典型的慢查询日志:
# Time: 2019-08-14T09:26:59.487776265+08:00
# Txn_start_ts: 410450924122144769
# User: root@127.0.0.1
# Conn_ID: 3086
# Query_time: 1.527627037
# Parse_time: 0.000054933
# Compile_time: 0.000129729
# Process_time: 0.07 Wait_time: 0.002 Backoff_time: 0.002 Request_count: 1 Total_keys: 131073 Process_keys: 131072 Prewrite_time: 0.335415029 Commit_time: 0.032175429 Get_commit_ts_time: 0.000177098 Local_latch_wait_time: 0.106869448 Write_keys: 131072 Write_size: 3538944 Prewrite_region: 1
# DB: test
# Is_internal: false
# Digest: 50a2e32d2abbd6c1764b1b7f2058d428ef2712b029282b776beb9506a365c0f1
# Stats: t:414652072816803841
# Num_cop_tasks: 1
# Cop_proc_avg: 0.07 Cop_proc_p90: 0.07 Cop_proc_max: 0.07 Cop_proc_addr: 172.16.5.87:20171
# Cop_wait_avg: 0 Cop_wait_p90: 0 Cop_wait_max: 0 Cop_wait_addr: 172.16.5.87:20171
# Mem_max: 525211
# Succ: true
# Plan_digest: e5f9d9746c756438a13c75ba3eedf601eecf555cdb7ad327d7092bdd041a83e7
# Plan: tidb_decode_plan('ZJAwCTMyXzcJMAkyMAlkYXRhOlRhYmxlU2Nhbl82CjEJMTBfNgkxAR0AdAEY1Dp0LCByYW5nZTpbLWluZiwraW5mXSwga2VlcCBvcmRlcjpmYWxzZSwgc3RhdHM6cHNldWRvCg==')
insert into t select * from t;以下逐一介绍慢查询日志中各个字段的含义。
注意:慢查询日志中所有时间相关字段的单位都是秒。
(1) 慢查询基础信息:
Time:表示日志打印时间。Query_time:表示执行该语句花费的时间。Parse_time:表示该语句在语法解析阶段花费的时间。Compile_time:表示该语句在查询优化阶段花费的时间。Digest:表示该语句的 SQL 指纹。Stats:表示 table 使用的统计信息版本时间戳。如果时间戳显示为pseudo,表示用默认假设的统计信息。Txn_start_ts:表示事务的开始时间戳,也就是事务的唯一 ID,可以用该值在 TiDB 日志中查找事务相关的其他日志。Is_internal:表示是否为 TiDB 内部的 SQL 语句。true表示是 TiDB 系统内部执行的 SQL 语句,false表示是由用户执行的 SQL 语句。Index_ids:表示该语句使用的索引 ID。Succ:表示该语句是否执行成功。Backoff_time:表示遇到需要重试的错误时该语句在重试前等待的时间。常见的需要重试的错误有以下几种:遇到了 lock、Region 分裂、tikv server is busy。Plan_digest:表示 plan 的指纹。Plan:表示该语句的执行计划,运行select tidb_decode_plan('...')可以解析出具体的执行计划。Query:表示该 SQL 语句。慢日志里不会打印字段名 Query,但映射到内存表后对应的字段叫Query。
(2) 和事务执行相关的字段:
Prewrite_time:表示事务两阶段提交中第一阶段(prewrite阶段)的耗时。Commit_time:表示事务两阶段提交中第二阶段(commit阶段)的耗时。Get_commit_ts_time:表示事务两阶段提交中第二阶段(commit阶段)获取commit时间戳的耗时。Local_latch_wait_time:表示事务两阶段提交中第二阶段(commit阶段)发起前在 TiDB 侧等锁的耗时。Write_keys:表示该事务向 TiKV 的 Write CF 写入 Key 的数量。Write_size:表示事务提交时写 key 和 value 的总大小。Prewrite_region:表示事务两阶段提交中第一阶段(prewrite阶段)涉及的 TiKV Region 数量。每个 Region 会触发一次远程过程调用。
(3) 和内存使用相关的字段:
Memory_max:表示执行期间 TiDB 使用的最大内存空间,单位为byte。
(4) 和用户相关的字段:
User:表示执行语句的用户名。Conn_ID:表示用户的连接 ID,可以用类似con:3的关键字在 TiDB 日志中查找该链接相关的其他日志。DB:表示执行语句时使用的 database。
(5) 和 TiKV Coprocessor Task 相关的字段:
Process_time:该 SQL 在 TiKV 上的处理时间之和。因为数据会并行发到 TiKV 执行,该值可能会超过Query_time。Wait_time:表示该语句在 TiKV 上的等待时间之和。因为 TiKV 的 Coprocessor 线程数是有限的,当所有的 Coprocessor 线程都在工作的时候,请求会排队;若队列中部分请求耗时很长,后面的请求的等待时间会增加。Request_count:表示该语句发送的 Coprocessor 请求的数量。Total_keys:表示 Coprocessor 扫过的 key 的数量。Process_keys:表示 Coprocessor 处理的 key 的数量。相较于total_keys,processed_keys 不包含 MVCC 的旧版本。如果processed_keys和total_keys相差很大,说明旧版本比较多。Cop_proc_avg:cop-task 的平均执行时间。Cop_proc_p90:cop-task 的 P90 分位执行时间。Cop_proc_max:cop-task 的最大执行时间。Cop_proc_addr:执行时间最长的 cop-task 所在地址。Cop_wait_avg:cop-task 的平均等待时间。Cop_wait_p90:cop-task 的 P90 分位等待时间。Cop_wait_max:cop-task 的最大等待时间。Cop_wait_addr:等待时间最长的 cop-task 所在地址。
Slow Query 内存表使用排查
下面通过一些示例展示如何通过 SQL 查看 TiDB 的慢查询。
检索当前节点 Top N 慢查询
以下 SQL 用于检索当前 TiDB 节点的 Top 2 慢查询:
> select query_time, query
from information_schema.slow_query -- 检索当前 TiDB 节点的慢查询
where is_internal = false -- 排除 TiDB 内部的慢查询
order by query_time desc
limit 2;
+--------------+------------------------------------------------------------------+
| query_time | query |
+--------------+------------------------------------------------------------------+
| 12.77583857 | select * from t_slim, t_wide where t_slim.c0=t_wide.c0; |
| 0.734982725 | select t0.c0, t1.c1 from t_slim t0, t_wide t1 where t0.c0=t1.c0; |
+--------------+------------------------------------------------------------------+检索全部节点上指定用户的 Top N 慢查询
以下 SQL 会检索全部 TiDB 节点上指定用户 test的 Top 2 慢查询:
> select query_time, query, user
from information_schema.cluster_slow_query -- 检索全部 TiDB 节点的慢查询
where is_internal = false
and user = "test"
order by query_time desc
limit 2;
+-------------+------------------------------------------------------------------+----------------+
| Query_time | query | user |
+-------------+------------------------------------------------------------------+----------------+
| 0.676408014 | select t0.c0, t1.c1 from t_slim t0, t_wide t1 where t0.c0=t1.c1; | test |
+-------------+------------------------------------------------------------------+----------------+检索同类慢查询
在得到 Top N 慢查询后,可通过 SQL 指纹继续检索同类慢查询。
-- 先获取 Top N 的慢查询和对应的 SQL 指纹
> select query_time, query, digest
from information_schema.cluster_slow_query
where is_internal = false
order by query_time desc
limit 1;
+-------------+-----------------------------+------------------------------------------------------------------+
| query_time | query | digest |
+-------------+-----------------------------+------------------------------------------------------------------+
| 0.302558006 | select * from t1 where a=1; | 4751cb6008fda383e22dacb601fde85425dc8f8cf669338d55d944bafb46a6fa |
+-------------+-----------------------------+------------------------------------------------------------------+
-- 再根据 SQL 指纹检索同类慢查询
> select query, query_time
from information_schema.cluster_slow_query
where digest = "4751cb6008fda383e22dacb601fde85425dc8f8cf669338d55d944bafb46a6fa";
+-----------------------------+-------------+
| query | query_time |
+-----------------------------+-------------+
| select * from t1 where a=1; | 0.302558006 |
| select * from t1 where a=2; | 0.401313532 |
+-----------------------------+-------------+检索统计信息为 pseudo的慢查询
如果慢查询日志中的统计信息被标记为 pseudo,往往说明 TiDB 表的统计信息更新不及时,需要运行 analyze table手动收集统计信息。以下 SQL 可以找到这一类慢查询:
如果慢查询日志中的统计信息被标记为 pseudo,往往说明 TiDB 表的统计信息更新不及时,需要运行 analyze table 手动收集统计信息。以下 SQL 可以找到这一类慢查询:
> select query, query_time, stats
from information_schema.cluster_slow_query
where is_internal = false
and stats like '%pseudo%';
+-----------------------------+-------------+---------------------------------+
| query | query_time | stats |
+-----------------------------+-------------+---------------------------------+
| select * from t1 where a=1; | 0.302558006 | t1:pseudo |
| select * from t1 where a=2; | 0.401313532 | t1:pseudo |
| select * from t1 where a>2; | 0.602011247 | t1:pseudo |
| select * from t1 where a>3; | 0.50077719 | t1:pseudo |
| select * from t1 join t2; | 0.931260518 | t1:407872303825682445,t2:pseudo |
+-----------------------------+-------------+---------------------------------+查询执行计划发生变化的慢查询
由于统计信息不准,可能导致同类型 SQL 的执行计划发生意料之外的改变。用以下 SQL 可以检索到哪些慢查询具有多种不同的执行计划:
> select count(distinct plan_digest) as count, digest,min(query)
from information_schema.cluster_slow_query
group by digest
having count>1
limit 3\G
***************************[ 1. row ]***************************
count | 2
digest | 17b4518fde82e32021877878bec2bb309619d384fca944106fcaf9c93b536e94
min(query) | SELECT DISTINCT c FROM sbtest25 WHERE id BETWEEN ? AND ? ORDER BY c [arguments: (291638, 291737)];
***************************[ 2. row ]***************************
count | 2
digest | 9337865f3e2ee71c1c2e740e773b6dd85f23ad00f8fa1f11a795e62e15fc9b23
min(query) | SELECT DISTINCT c FROM sbtest22 WHERE id BETWEEN ? AND ? ORDER BY c [arguments: (215420, 215519)];
***************************[ 3. row ]***************************
count | 2
digest | db705c89ca2dfc1d39d10e0f30f285cbbadec7e24da4f15af461b148d8ffb020
min(query) | SELECT DISTINCT c FROM sbtest11 WHERE id BETWEEN ? AND ? ORDER BY c [arguments: (303359, 303458)];
-- 借助 SQL 指纹进一步查询执行计划的详细信息
> select min(plan),plan_digest
from information_schema.cluster_slow_query
where digest='17b4518fde82e32021877878bec2bb309619d384fca944106fcaf9c93b536e94'
group by plan_digest\G
*************************** 1. row ***************************
min(plan): Sort_6 root 100.00131380758702 sbtest.sbtest25.c:asc
└─HashAgg_10 root 100.00131380758702 group by:sbtest.sbtest25.c, funcs:firstrow(sbtest.sbtest25.c)->sbtest.sbtest25.c
└─TableReader_15 root 100.00131380758702 data:TableRangeScan_14
└─TableScan_14 cop 100.00131380758702 table:sbtest25, range:[502791,502890], keep order:false
plan_digest: 6afbbd21f60ca6c6fdf3d3cd94f7c7a49dd93c00fcf8774646da492e50e204ee
*************************** 2. row ***************************
min(plan): Sort_6 root 1 sbtest.sbtest25.c:asc
└─HashAgg_12 root 1 group by:sbtest.sbtest25.c, funcs:firstrow(sbtest.sbtest25.c)->sbtest.sbtest25.c
└─TableReader_13 root 1 data:HashAgg_8
└─HashAgg_8 cop 1 group by:sbtest.sbtest25.c,
└─TableScan_11 cop 1.2440069558121831 table:sbtest25, range:[472745,472844], keep order:false统计各个节点的慢查询数量
以下 SQL 统计指定时段内各个 TiDB 节点上出现过的慢查询数量:
> select instance, count(*)
from information_schema.cluster_slow_query
where time >= "2020-03-06 00:00:00"
and time < now()
group by instance;
+---------------+----------+
| instance | count(*) |
+---------------+----------+
| 0.0.0.0:10081 | 124 |
| 0.0.0.0:10080 | 119771 |
+---------------+----------+检索异常时段的慢查询
假定 2020-03-10 13:24:00至 2020-03-10 13:27:00期间发现 QPS 降低和查询响应时间升高等问题,可以用以下 SQL 过滤出仅仅出现在异常时段的慢查询:
> select * from
(select /*+ AGG_TO_COP(), HASH_AGG() */ count(*),
min(time),
sum(query_time) AS sum_query_time,
sum(Process_time) AS sum_process_time,
sum(Wait_time) AS sum_wait_time,
sum(Commit_time),
sum(Request_count),
sum(process_keys),
sum(Write_keys),
max(Cop_proc_max),
min(query),min(prev_stmt),
digest
from information_schema.cluster_slow_query
where time >= '2020-03-10 13:24:00'
and time < '2020-03-10 13:27:00'
adn Is_internal = false
group by digest) AS t1
where t1.digest not in
(select /*+ AGG_TO_COP(), HASH_AGG() */ digest
from information_schema.cluster_slow_query
where time >= '2020-03-10 13:20:00' -- 排除正常时段 `2020-03-10 13:20:00` ~ `2020-03-10 13:23:00` 期间的慢查询
and time < '2020-03-10 13:23:00'
group by digest)
order by t1.sum_query_time desc
limit 10\G
***************************[ 1. row ]***************************
count(*) | 200
min(time) | 2020-03-10 13:24:27.216186
sum_query_time | 50.114126194
sum_process_time | 268.351
sum_wait_time | 8.476
sum(Commit_time) | 1.044304306
sum(Request_count) | 6077
sum(process_keys) | 202871950
sum(Write_keys) | 319500
max(Cop_proc_max) | 0.263
min(query) | delete from test.tcs2 limit 5000;
min(prev_stmt) |
digest | 24bd6d8a9b238086c9b8c3d240ad4ef32f79ce94cf5a468c0b8fe1eb5f8d03dfTiDB Dashboard 可视化 Statements
上一节介绍了利用 Slow Query 内存表来排查慢查询,但 Slow Query 只会记录超过慢日志阈值的 SQL 而缺少对全部运行负载的诊断排查。本节会介绍通过使用 TiDB Dashboard 来排查定位问题查询。TiDB Dashboard 提供了 Statements 用来监控和统计 SQL,例如页面上提供了丰富的列表信息,包括延迟、执行次数、扫描行数、全表扫描次数等,用来分析哪些类别的 SQL 语句耗时过长、消耗内存过多等情况,帮助用户定位性能问题。
TiDB 已支持多种性能排查工具。但在多种应用场景需求下,仍有不足,例如:
1.Grafana 不能排查单条 SQL 的性能问题
2.Slow log 只记录超过慢日志阀值的 SQL
3.General log 本身对性能有一定影响
4.Explain analyze 只能查看可以复现的问题
5.Profile 只能查看整个实例的瓶颈
因此推出可视化 Statements,可以直接在页面观察 SQL 执行情况,不需要查询系统表,便于用户定位性能问题。
使用 TiDB Dashboard
从4.0版本开始,TiDB 提供了一个新的 Dashboard 运维管理工具,集成在 PD 组件上,默认地址为 http://pd-url:pd_port/dashboard。 不同于 Grafana 监控是从数据库的监控视角出发,TiDB Dashboard 从 DBA 管理员角度出发,最大限度的简化管理员对 TiDB 数据库的运维,可在一个界面查看到整个分布式数据库集群的运行状况,包括数据热点、SQL 运行情况、集群信息、日志搜索、实时性能分析等。
查看 Statements 整体情况
登录后,在左侧点击「SQL 语句分析」即可进入此功能页面。
在时间区间选项框中选择要分析的时间段,即可得到该时段所有数据库的 SQL 语句执行统计情况。
如果只关心某些数据库,则可以在第二个选项框中选择相应的数据库对结果进行过滤,支持多选。
结果以表格的形式展示,并支持按不同的列对结果进行排序,如下图所示。
1.选择需要分析的时间段
2.支持按数据库过滤
3.支持按不同的指标排序
注意:这里所指的 SQL 语句实际指的是某一类 SQL 语句。语法一致的 SQL 语句会规一化为一类相同的 SQL 语句。
例如:
SELECT * FROM employee WHERE id IN (1, 2, 3);
select * from EMPLOYEE where ID in (4, 5);规一化为
select * from employee where id in (...);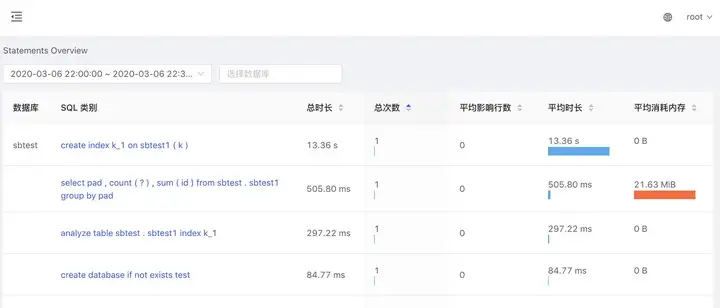
在 SQL 类别列,点击某类 SQL 语句,可以进入该 SQL 语句的详情页查看更详细的信息,以及该 SQL 语句在不同节点上执行的统计情况。
单个 Statements 详情页关键信息如下图所示。
1.SQL 执行总时长
2.平均影响行数(一般是写入)
3.平均扫描行数(一般是读)
4.各个节点执行指标(可以快速定位出某个节点性能瓶颈)
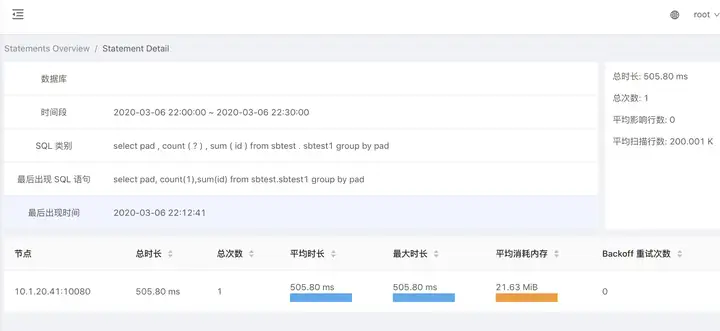
Statements 参数配置
tidb_enable_stmt_summaryStatements 功能默认开启,也可以通过设置系统变量打开,例如:
set global tidb_enable_stmt_summary = true;tidb_stmt_summary_refresh_interval
设置 performance_schema.events_statements_summary_by_digest表的的清空周期,单位是秒 (s),默认值是 1800,例如:
set global tidb_stmt_summary_refresh_interval = 1800;tidb_stmt_summary_history_size设置performance_schema.events_statements_summary_by_digest_history表保存每种 SQL 的历史的数量,默认值是 24,例如:
set global tidb_stmt_summary_history_size = 24;由于 Statements 信息是存储在内存表中,为了防止内存溢出等问题,需要限制保存的 SQL 条数和 SQL 的最大显示长度。这两个参数需要在 config.toml 的 [stmt-summary]类别下配置:
- 通过
max-stmt-count更改保存的 SQL 种类数量,默认 200 条。当 SQL 种类超过max-stmt-count时,会移除最近没有使用的 SQL - 通过
max-sql-length更改DIGEST_TEXT和QUERY_SAMPLE_TEXT的最大显示长度,默认是 4096
注意:tidb_stmt_summary_history_size、max-stmt-count、max-sql-length几项配置影响内存占用,建议根据实际情况调整,不宜设置得过大。
综上所述,可视化 Statements 可以快速定位某个 SQL 性能问题。
本文为「TiDB 查询优化及调优」系列文章的第三篇,前文我们分别介绍了 优化器的基本概念和 TiDB 的查询计划,后续将继续对 TiDB 调整及优化查询执行计划、其他优化器开发或规划中的诊断调优功能等进行介绍。 如果您对 TiDB 的产品有任何建议,欢迎来到

与我们交流。
[转帖]TiDB 查询优化及调优系列(三)慢查询诊断监控及排查的更多相关文章
- SQL Server调优系列进阶篇 - 查询语句运行几个指标值监测
前言 上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤.筛选条件分析.索引项优化等信息. 本篇我们分析在我们运行的过程中几个关键指标值的检测. 通过这些指标值来分析语句的运行问 ...
- SQL Server 调优系列进阶篇 - 查询语句运行几个指标值监测
前言 上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤.筛选条件分析.索引项优化等信息. 本篇我们分析在我们运行的过程中几个关键指标值的检测. 通过这些指标值来分析语句的运行问 ...
- mysql监控、性能调优及三范式理解
原文:mysql监控.性能调优及三范式理解 1监控 工具:sp on mysql sp系列可监控各种数据库 2调优 2.1 DB层操作与调优 2.1.1.开启慢查询 在My.cnf文件中添加如 ...
- SQL Server调优系列进阶篇(查询优化器的运行方式)
前言 前面我们的几篇文章介绍了一系列关于运算符的基础介绍,以及各个运算符的优化方式和技巧.其中涵盖:查看执行计划的方式.几种数据集常用的连接方式.联合运算符方式.并行运算符等一系列的我们常见的运算符. ...
- SQL Server性能调优系列
这是关于SQL Server调优系列文章,以下内容基本涵盖我们日常中所写的查询运算的分解以及调优内容项,皆为原创........ 第一个基础模块注重基础内容的掌握,共分7篇文章完成,内容涵盖一系列基础 ...
- SQL Server调优系列基础篇
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
- SQL Server调优系列基础篇(索引运算总结)
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server调优系列进阶篇(查询语句运行几个指标值监测)
前言 上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤.筛选条件分析.索引项优化等信息. 本篇我们分析在我们运行的过程中几个关键指标值的检测. 通过这些指标值来分析语句的运行问 ...
- SQL Server调优系列进阶篇(深入剖析统计信息)
前言 经过前几篇的分析,其实大体已经初窥到SQL Server统计信息的重要性了,所以本篇就要祭出这个神器了. 该篇内容会很长,坐好板凳,瓜子零食之类... 不废话,进正题 技术准备 数据库版本为SQ ...
- SQL Server调优系列进阶篇(如何索引调优)
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
随机推荐
- 关于 x^n + 1 形式因式分解的讨论
昨晚一个同学问我立方和分解,突发奇想想到了这个问题.看到网上关于这个问题的许多解答都不是很准确.在此修正一下. 引理一:立方和公式 对于形如 \(a^3 + b^3\) 的式子,有因式分解: \(a^ ...
- 斯坦福 UE4 C++ ActionRoguelike游戏实例教程 05.认识GameMode&自动生成AI角色
斯坦福课程 UE4 C++ ActionRoguelike游戏实例教程 0.绪论 概述 本篇文章将会讲述UE中Gamemode的基本概念,并在C++中开发GameMode,为游戏设置一个简单的玩法:使 ...
- Spring事务状态处理
Spring事务提交后执行:深入理解和实践 在Java开发中,Spring框架的事务管理是一个核心概念,尤其是在企业级应用中.理解和正确使用Spring事务对于保证应用的数据一致性和稳定性至关重要.本 ...
- 28、Flutter Key详解
在Flutter中,Key是不能重复使用的,所以Key一般用来做唯一标识.组件在更新的时候,其状态的保 存主要是通过判断组件的类型或者key值是否一致.因此,当各组件的类型不同的时候,类型已经足够 用 ...
- js文字转语音播放SpeechSynthesisUtterance
文字转语音 SpeechSynthesisUtterance是HTML5中新增的API,用于将指定文字合成为对应的语音 function sayTTS(content) { const synth = ...
- 【玩转鲲鹏DevKit系列】如何快速迁移软件包?
本文分享自华为云社区<[玩转鲲鹏DevKit系列]如何快速迁移软件包?>,作者: 华为云社区精选 . 软件包含各种不同格式的文件,如RPM包通常包含二进制文件.SO 库文件.JAR包.配置 ...
- 加快脑动脉瘤检测,AI来了
摘要:华为云EI创新孵化Lab联合华中科技大学电信学院.华中科技大学同济医学院附属协和医院放射科在放射学领域的国际顶级期刊Radiology(<放射学>)上共同发表了最新研究成果. 日前, ...
- 华为云GaussDB数据库荣获国际CC EAL4+级别认证
摘要:近日,华为云GaussDB企业级分布式数据库内核正式通过了全球知名独立认证机构欧洲SGS Brightsight实验室的安全评估,获得全球权威信息技术安全性评估标准CC EAL4+级别认证. 本 ...
- IOS证书制作教程
转载:IOS证书制作教程 点击苹果证书 按钮 编辑 点击新增 编辑 输入证书密码,名称 这个密码不是账号密码,而是一个保护证书的密码,是p12文件的密码,此密码设置后没有其他地方可以找到, ...
- 火山引擎 DataTester 应用故事:一个 A/B 测试,将产品 DAU 提升了数十万
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 疫情让线下的需求大量转移到线上,催生出了远程办公.网络授课.线上健身等新的生态现象.如何更好地为用户服务,提升 ...