三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署
TensorFlow 模型导出
使用 SavedModel 完整导出模型
不仅包含参数的权值,还包含计算的流程(即计算图)
tf.saved_model.save(model, "保存的目标文件夹名称")
将模型导出为 SavedModel
model = tf.saved_model.load("保存的目标文件夹名称")
载入 SavedModel 文件
tf.keras.Model 类建立的 Keras 模型,其需要导出到 SavedModel 格式的方法(比如 call )都需要使用 @tf.function 修饰tf.keras.Model 类建立的 Keras 模型 model ,使用 SavedModel 载入后将无法使用 model() 直接进行推断,而需要使用 model.call()import tensorflow as tf
from zh.model.utils import MNISTLoader num_epochs = 1
batch_size = 50
learning_rate = 0.001 model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(100, activation=tf.nn.relu),
tf.keras.layers.Dense(10),
tf.keras.layers.Softmax()
]) data_loader = MNISTLoader()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
)
model.fit(data_loader.train_data, data_loader.train_label, epochs=num_epochs, batch_size=batch_size)
tf.saved_model.save(model, "saved/1")
MNIST 手写体识别的模型 进行导出
import tensorflow as tf
from zh.model.utils import MNISTLoader batch_size = 50 model = tf.saved_model.load("saved/1")
data_loader = MNISTLoader()
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data // batch_size)
for batch_index in range(num_batches):
start_index, end_index = batch_index * batch_size, (batch_index + 1) * batch_size
y_pred = model(data_loader.test_data[start_index: end_index])
sparse_categorical_accuracy.update_state(y_true=data_loader.test_label[start_index: end_index], y_pred=y_pred)
print("test accuracy: %f" % sparse_categorical_accuracy.result())
MNIST 手写体识别的模型 进行导入并测试
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=100, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10) @tf.function
def call(self, inputs): # [batch_size, 28, 28, 1]
x = self.flatten(inputs) # [batch_size, 784]
x = self.dense1(x) # [batch_size, 100]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output model = MLP()
使用继承 tf.keras.Model 类建立的 Keras 模型同样可以以相同方法导出,唯须注意 call 方法需要以 @tf.function 修饰,以转化为 SavedModel 支持的计算图
y_pred = model.call(data_loader.test_data[start_index: end_index])
模型导入并测试性能的过程也相同,唯须注意模型推断时需要显式调用 call 方法
Keras Sequential save 方法
是基于 keras 的 Sequential 构建了多层的卷积神经网络,并进行训练
curl -LO https://raw.githubusercontent.com/keras-team/keras/master/examples/mnist_cnn.py
使用如下命令拷贝到本地:
model.save('mnist_cnn.h5')
对 keras 训练完毕的模型进行保存
python mnist_cnn.py
在终端中执行 mnist_cnn.py 文件
执行过程会比较久,执行结束后,会在当前目录产生 mnist_cnn.h5 文件(HDF5 格式),就是 keras 训练后的模型,其中已经包含了训练后的模型结构和权重等信息。
在服务器端,可以直接通过 keras.models.load_model("mnist_cnn.h5") 加载,然后进行推理;在移动设备需要将 HDF5 模型文件转换为 TensorFlow Lite 的格式,然后通过相应平台的 Interpreter 加载,然后进行推理。
TensorFlow Serving(服务器端部署模型)
安装
# 添加Google的TensorFlow Serving源
echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list
# 添加gpg key
curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -
设置安装源
sudo apt-get update
sudo apt-get install tensorflow-model-server
使用 apt-get 安装 TensorFlow Serving
curl 设置代理的方式为 -x 选项或设置 http_proxy 环境变量,即 export http_proxy=http://代理服务器IP:端口 或 curl -x http://代理服务器IP:端口 URL
apt-get 设置代理的方式为 -o 选项,即 sudo apt-get -o Acquire::http::proxy="http://代理服务器IP:端口" ...
可能需要设置代理
模型部署
tensorflow_model_server \
--rest_api_port=端口号(如8501) \
--model_name=模型名 \
--model_base_path="SavedModel格式模型的文件夹绝对地址(不含版本号)"
直接读取 SavedModel 格式的模型进行部署
支持热更新模型,其典型的模型文件夹结构如下:
/saved_model_files
/1 # 版本号为1的模型文件
/assets
/variables
saved_model.pb
...
/N # 版本号为N的模型文件
/assets
/variables
saved_model.pb
上面 1~N 的子文件夹代表不同版本号的模型。当指定 --model_base_path 时,只需要指定根目录的 绝对地址 (不是相对地址)即可。例如,如果上述文件夹结构存放在 home/snowkylin 文件夹内,则 --model_base_path 应当设置为 home/snowkylin/saved_model_files (不附带模型版本号)。TensorFlow Serving 会自动选择版本号最大的模型进行载入。
tensorflow_model_server \
--rest_api_port=8501 \
--model_name=MLP \
--model_base_path="/home/.../.../saved" # 文件夹绝对地址根据自身情况填写,无需加入版本号
Keras Sequential 模式模型的部署
MLP 的模型名在 8501 端口进行部署,可以直接使用以上命令class MLP(tf.keras.Model):
... @tf.function(input_signature=[tf.TensorSpec([None, 28, 28, 1], tf.float32)])
def call(self, inputs):
...
自定义 Keras 模型的部署-导出到 SavedModel 格式
@tf.function 修饰,还要在修饰时指定 input_signature 参数,以显式说明输入的形状。该参数传入一个由 tf.TensorSpec 组成的列表,指定每个输入张量的形状和类型[None, 28, 28, 1] 的四维张量( None表示第一维即 Batch Size 的大小不固定),此时我们可以将模型的 call 方法做出上面的修饰model = MLP()
...
tf.saved_model.save(model, "saved_with_signature/1", signatures={"call": model.call})
自定义 Keras 模型的部署-使用 tf.saved_model.save 导出
tf.saved_model.save 导出时,需要通过 signature 参数提供待导出的函数的签名(Signature)call 这一签名来调用 model.call方法时,我们可以在导出时传入 signature 参数,以 dict 的键值对形式告知导出的方法对应的签名tensorflow_model_server \
--rest_api_port=8501 \
--model_name=MLP \
--model_base_path="/home/.../.../saved_with_signature" # 修改为自己模型的绝对地址
两步均完成后,即可使用以下命令部署
在客户端调用以 TensorFlow Serving 部署的模型
支持以 gRPC 和 RESTful API 调用以 TensorFlow Serving 部署的模型。这里主要介绍较为通用的 RESTful API 方法。
RESTful API 以标准的 HTTP POST 方法进行交互,请求和回复均为 JSON 对象。为了调用服务器端的模型,我们在客户端向服务器发送以下格式的请求:
服务器 URI: http://服务器地址:端口号/v1/models/模型名:predict
请求内容:
{
"signature_name": "需要调用的函数签名(Sequential模式不需要)",
"instances": 输入数据
}
回复为:
{
"predictions": 返回值
}
import json
import numpy as np
import requests
from zh.model.utils import MNISTLoader data_loader = MNISTLoader()
data = json.dumps({
"instances": data_loader.test_data[0:3].tolist()
})
headers = {"content-type": "application/json"}
json_response = requests.post(
'http://localhost:8501/v1/models/MLP:predict',
data=data, headers=headers)
predictions = np.array(json.loads(json_response.text)['predictions'])
print(np.argmax(predictions, axis=-1))
print(data_loader.test_label[0:10])
Python 客户端示例
import json
import numpy as np
import requests
from zh.model.utils import MNISTLoader data_loader = MNISTLoader() data = json.dumps({
"signature_name": "call",
"instances": data_loader.test_data[0:10].tolist()
}) headers = {"content-type": "application/json"}
json_response = requests.post(
'http://localhost:8501/v1/models/MLP:predict',
data=data, headers=headers)
predictions = np.array(json.loads(json_response.text)['predictions'])
print(np.argmax(predictions, axis=-1))
print(data_loader.test_label[0:10])
对于自定义的 Keras 模型,在发送的数据中加入 signature_name 键值即可
const Jimp = require('jimp')
const superagent = require('superagent')
const url = 'http://localhost:8501/v1/models/MLP:predict'
const getPixelGrey = (pic, x, y) => {
const pointColor = pic.getPixelColor(x, y)
const { r, g, b } = Jimp.intToRGBA(pointColor)
const gray = +(r * 0.299 + g * 0.587 + b * 0.114).toFixed(0)
return [ gray / 255 ]
}
const getPicGreyArray = async (fileName) => {
const pic = await Jimp.read(fileName)
const resizedPic = pic.resize(28, 28)
const greyArray = []
for ( let i = 0; i< 28; i ++ ) {
let line = []
for (let j = 0; j < 28; j ++) {
line.push(getPixelGrey(resizedPic, j, i))
}
console.log(line.map(_ => _ > 0.3 ? ' ' : '').join(' '))
greyArray.push(line)
}
return greyArray
}
const evaluatePic = async (fileName) => {
const arr = await getPicGreyArray(fileName)
const result = await superagent.post(url)
.send({
instances: [arr]
})
result.body.predictions.map(res => {
const sortedRes = res.map((_, i) => [_, i])
.sort((a, b) => b[0] - a[0])
console.log(`我们猜这个数字是${sortedRes[0][1]},概率是${sortedRes[0][0]}`)
})
}
evaluatePic('test_pic_tag_5.png')
Node.js 客户端示例
npm install jimp 和 npm install superagent 安装)TensorFlow Lite(移动端部署模型)
目前 TFLite 只提供了推理功能,在服务器端进行训练后,经过如下简单处理即可部署到边缘设备上。
模型转换
模型转换:由于边缘设备计算等资源有限,使用 TensorFlow 训练好的模型,模型太大、运行效率比较低,不能直接在移动端部署,需要通过相应工具进行转换成适合边缘设备的格式。
转换方式有两种:Float 格式和 Quantized 格式
针对 Float 格式的,先使用命令行工具 tflite_convert,在终端执行如下命令:
tflite_convert -h
usage: tflite_convert [-h] --output_file OUTPUT_FILE
(--saved_model_dir SAVED_MODEL_DIR | --keras_model_file KERAS_MODEL_FILE)
--output_file OUTPUT_FILE
Full filepath of the output file.
--saved_model_dir SAVED_MODEL_DIR
Full path of the directory containing the SavedModel.
--keras_model_file KERAS_MODEL_FILE
Full filepath of HDF5 file containing tf.Keras model.
命令的使用方法
TF2.0 支持两种模型导出方法和格式 SavedModel 和 Keras Sequential。
tflite_convert --saved_model_dir=saved/1 --output_file=mnist_savedmodel.tflite
SavedModel 导出模型转换
tflite_convert --keras_model_file=mnist_cnn.h5 --output_file=mnist_sequential.tflite
Keras Sequential 导出模型转换
Android 部署
边缘设备部署:本节以 android 为例,简单介绍如何在 android 应用中部署转化后的模型,完成 Mnist 图片的识别。
buildscript {
repositories {
maven { url 'https://maven.aliyun.com/nexus/content/repositories/google' }
maven { url 'https://maven.aliyun.com/nexus/content/repositories/jcenter' }
}
dependencies {
classpath 'com.android.tools.build:gradle:3.5.1'
}
}
allprojects {
repositories {
maven { url 'https://maven.aliyun.com/nexus/content/repositories/google' }
maven { url 'https://maven.aliyun.com/nexus/content/repositories/jcenter' }
}
}
配置 build.gradle
build.gradle 中的 maven 源 google() 和 jcenter() 分别替换为国内镜像android {
aaptOptions {
noCompress "tflite" // 编译apk时,不压缩tflite文件
}
}
dependencies {
implementation 'org.tensorflow:tensorflow-lite:1.14.0'
}
配置 app/build.gradle
app/build.gradle 添加信息其中,
aaptOptions设置 tflite 文件不压缩,确保后面 tflite 文件可以被 Interpreter 正确加载。org.tensorflow:tensorflow-lite的最新版本号可以在这里查询 https://bintray.com/google/tensorflow/tensorflow-lite
设置好后,sync 和 build 整个工程,如果 build 成功说明,配置成功。
添加 tflite 文件到 assets 文件夹
在 app 目录先新建 assets 目录,并将 mnist_savedmodel.tflite 文件保存到 assets 目录。重新编译 apk,检查新编译出来的 apk 的 assets 文件夹是否有 mnist_cnn.tflite 文件。
点击菜单 Build->Build APK (s) 触发 apk 编译,apk 编译成功点击右下角的 EventLog。点击最后一条信息中的 analyze 链接,会触发 apk analyzer 查看新编译出来的 apk,若在 assets 目录下存在 mnist_savedmodel.tflite ,则编译打包成功,如下:
assets
|__mnist_savedmodel.tflite
/** Memory-map the model file in Assets. */
private MappedByteBuffer loadModelFile(Activity activity) throws IOException {
AssetFileDescriptor fileDescriptor = activity.getAssets().openFd(mModelPath);
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
加载模型
mnist_savedmodel.tflite 文件加载到 memory-map 中,作为 Interpreter 实例化的输入mTFLite = new Interpreter(loadModelFile(activity));
实例化 Interpreter,其中 acitivity 是为了从 assets 中获取模型
getAssets() 打开。MappedByteBuffer 直接作为 Interpreter 的输入, mTFLite ( Interpreter )就是转换后模型的运行载体。
//Float模型相关参数
// com/dpthinker/mnistclassifier/model/FloatSavedModelConfig.java
protected void setConfigs() {
setModelName("mnist_savedmodel.tflite"); setNumBytesPerChannel(4); setDimBatchSize(1);
setDimPixelSize(1); setDimImgWeight(28);
setDimImgHeight(28); setImageMean(0);
setImageSTD(255.0f);
} // 初始化
// com/dpthinker/mnistclassifier/classifier/BaseClassifier.java
private void initConfig(BaseModelConfig config) {
this.mModelConfig = config;
this.mNumBytesPerChannel = config.getNumBytesPerChannel();
this.mDimBatchSize = config.getDimBatchSize();
this.mDimPixelSize = config.getDimPixelSize();
this.mDimImgWidth = config.getDimImgWeight();
this.mDimImgHeight = config.getDimImgHeight();
this.mModelPath = config.getModelName();
}
运行输入
使用 MNIST test 测试集中的图片作为输入,mnist 图像大小 28*28,单像素
// 将输入的Bitmap转化为Interpreter可以识别的ByteBuffer
// com/dpthinker/mnistclassifier/classifier/BaseClassifier.java
protected ByteBuffer convertBitmapToByteBuffer(Bitmap bitmap) {
int[] intValues = new int[mDimImgWidth * mDimImgHeight];
scaleBitmap(bitmap).getPixels(intValues,
0, bitmap.getWidth(), 0, 0, bitmap.getWidth(), bitmap.getHeight()); ByteBuffer imgData = ByteBuffer.allocateDirect(
mNumBytesPerChannel * mDimBatchSize * mDimImgWidth * mDimImgHeight * mDimPixelSize);
imgData.order(ByteOrder.nativeOrder());
imgData.rewind(); // Convert the image toFloating point.
int pixel = 0;
for (int i = 0; i < mDimImgWidth; ++i) {
for (int j = 0; j < mDimImgHeight; ++j) {
//final int val = intValues[pixel++];
int val = intValues[pixel++];
mModelConfig.addImgValue(imgData, val); //添加把Pixel数值转化并添加到ByteBuffer
}
}
return imgData;
} // mModelConfig.addImgValue定义
// com/dpthinker/mnistclassifier/model/FloatSavedModelConfig.java
public void addImgValue(ByteBuffer imgData, int val) {
imgData.putFloat(((val & 0xFF) - getImageMean()) / getImageSTD());
}
将 MNIST 图片转化成 ByteBuffer ,并保持到 imgData ( ByteBuffer )中
convertBitmapToByteBuffer 的输出即为模型运行的输入。privateFloat[][] mLabelProbArray = newFloat[1][10];
运行输出
定义一个 1*10 的多维数组,因为我们只有 10 个 label
运行结束后,每个二级元素都是一个 label 的概率。
mTFLite.run(imgData, mLabelProbArray);
运行及结果处理
mLabelProbArray 的内容就是各个 label 识别的概率。对他们进行排序,找出 Top 的 label 并界面呈现给用户.View.OnClickListener() 触发 "image/*" 类型的 Intent.ACTION_GET_CONTENT ,进而获取设备上的图片(只支持 MNIST 标准图片)。然后,通过 RadioButtion 的选择情况,确认加载哪种转换后的模型,并触发真正分类操作。Quantization 模型转换
在 TF1.0 上,可以使用命令行工具转换 Quantized 模型。在笔者尝试的情况看在 TF2.0 上,命令行工具目前只能转换为 Float 模型,Python API 只能转换为 Quantized 模型。
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model('saved/1')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quant_model = converter.convert()
open("mnist_savedmodel_quantized.tflite", "wb").write(tflite_quant_model)
Python API 转换方法
mnist_savedmodel_quantized.tflite在 TF2.0 上,提供了新的一步到位的工具 visualize.py ,直接转换为 html 文件,除了模型结构,还有更清晰的关键信息总结。
visualize.py 目前看应该还是开发阶段,使用前需要先从 github 下载最新的 TensorFlow 和 FlatBuffers 源码,并且两者要在同一目录,因为 visualize.py 源码中是按两者在同一目录写的调用路径。
git clone git@github.com:tensorflow/tensorflow.git
下载 TensorFlow:
git clone git@github.com:google/flatbuffers.git
下载 FlatBuffers:
编译 FlatBuffers:(笔者使用的 Mac,其他平台请大家自行配置,应该不麻烦)
下载 cmake:执行
brew install cmake设置编译环境:在
FlatBuffers的根目录,执行cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release编译:在
FlatBuffers的根目录,执行make
编译完成后,会在跟目录生成 flatc,这个可执行文件是 visualize.py 运行所依赖的。
python visualize.py mnist_savedmodel_quantized.tflite mnist_savedmodel_quantized.html
visualize.py 使用方法
跟 Float 模型对比,Input/Output 格式是一致的,所以可以复用 Float 模型 Android 部署过程中的配置。
// Quantized模型相关参数
// com/dpthinker/mnistclassifier/model/QuantSavedModelConfig.java
public class QuantSavedModelConfig extends BaseModelConfig {
@Override
protected void setConfigs() {
setModelName("mnist_savedmodel_quantized.tflite"); setNumBytesPerChannel(4); setDimBatchSize(1);
setDimPixelSize(1); setDimImgWeight(28);
setDimImgHeight(28); setImageMean(0);
setImageSTD(255.0f);
} @Override
public void addImgValue(ByteBuffer imgData, int val) {
imgData.putFloat(((val & 0xFF) - getImageMean()) / getImageSTD());
}
}
具体配置
https://github.com/snowkylin/tensorflow-handbook/tree/master/source/androidTensorFlow.js
TensorFlow 的 JavaScript 版本,支持 GPU 硬件加速,可以运行在 Node.js 或浏览器环境中。它不但支持完全基于 JavaScript 从头开发、训练和部署模型,也可以用来运行已有的 Python 版 TensorFlow 模型,或者基于现有的模型进行继续训练。
基于 TensorFlow.js 1.0,向大家简单地介绍如何基于 ES6 的 JavaScript 进行 TensorFlow.js 的开发
相关代码,使用说明,和训练好的模型文件及参数,都可以在作者的 GitHub 上找到。地址: https://github.com/huan/tensorflow-handbook-javascript
浏览器中进行机器学习,相对比与服务器端来讲,将拥有以下四大优势:
不需要安装软件或驱动(打开浏览器即可使用);
可以通过浏览器进行更加方便的人机交互;
可以通过手机浏览器,调用手机硬件的各种传感器(如:GPS、电子罗盘、加速度传感器、摄像头等);
用户的数据可以无需上传到服务器,在本地即可完成所需操作。
Move Mirror 地址:https://experiments.withgoogle.com/move-mirror
Move Mirror 所使用的 PoseNet 地址:https://github.com/tensorflow/tfjs-models/tree/master/posenet
环境配置
在浏览器中使用 TensorFlow.js
<html>
<head>
<script src="http://unpkg.com/@tensorflow/tfjs/dist/tf.min.js"></script>
在 HTML 中直接引用 TensorFlow.js 发布的 NPM 包中已经打包安装好的 JavaScript 代码。
在 Node.js 中使用 TensorFlow.js
首先需要按照 NodeJS.org 官网的说明,完成安装最新版本的 Node.js 。然后,完成以下四个步骤即可完成配置:
$ node --verion
v10.5.0 $ npm --version
6.4.1
确认 Node.js 版本(v10 或更新的版本)
$ mkdir tfjs
$ cd tfjs
建立 TensorFlow.js 项目目录
# 初始化项目管理文件 package.json
$ npm init -y # 安装 tfjs 库,纯 JavaScript 版本
$ npm install @tensorflow/tfjs # 安装 tfjs-node 库,C Binding 版本
$ npm install @tensorflow/tfjs-node # 安装 tfjs-node-gpu 库,支持 CUDA GPU 加速
$ npm install @tensorflow/tfjs-node-gpu
安装 TensorFlow.js:
$ node
> require('@tensorflow/tfjs').version
{
'tfjs-core': '1.3.1',
'tfjs-data': '1.3.1',
'tfjs-layers': '1.3.1',
'tfjs-converter': '1.3.1',
tfjs: '1.3.1'
}
>
确认 Node.js 和 TensorFlow.js 工作正常
tfjs-core, tfjs-data, tfjs-layers 和 tfjs-converter 的输出信息,那么就说明环境配置没有问题了。import * as tf from '@tensorflow/tfjs'
console.log(tf.version.tfjs)
// Output: 1.3.1
在 JavaScript 程序中,通过以下指令,即可引入 TensorFlow.j
import 是 JavaScript ES6 版本新开始拥有的新特性。粗略可以认为等价于 require。比如:import * as tf from '@tensorflow/tfjs' 和 const tf = require('@tensorflow/tfjs') 对上面的示例代码是等价的。在微信小程序中使用 TensorFlow.js
首先要在小程序管理后台的 “设置 - 第三方服务 - 插件管理” 中添加插件。开发者可登录小程序管理后台,通过 appid _wx6afed118d9e81df9_ 查找插件并添加。本插件无需申请,添加后可直接使用。
例子可以看 TFJS Mobilenet: 物体识别小程序
有兴趣的读者可以前往 NEXT 学院,进行后续深度学习。课程地址:https://ke.qq.com/course/428263
模型部署
通过 TensorFlow.js 加载 Python 模型
$ pip install tensorflowjs
安装 tensorflowjs_converter
使用细节,可以通过 --help 参数查看程序帮助:
$ tensorflowjs_converter --help
以 MobilenetV1 为例,看一下如何对模型文件进行转换操作,并将可以被 TensorFlow.js 加载的模型文件,存放到 /mobilenet/tfjs_model 目录下。
tensorflowjs_converter \
--input_format=tf_saved_model \
--output_node_names='MobilenetV1/Predictions/Reshape_1' \
--saved_model_tags=serve \
/mobilenet/saved_model \
/mobilenet/tfjs_model
转换 SavedModel:将 /mobilenet/saved_model 转换到 /mobilenet/tfjs_model
转换完成的模型,保存为了两类文件:
model.json:模型架构
group1-shard*of*:模型参数
举例来说,我们对 MobileNet v2 转换出来的文件,如下:
/mobilenet/tfjs_model/model.json /mobilenet/tfjs_model/group1-shard1of5 … /mobilenet/tfjs_model/group1-shard5of5
$ npm install @tensorflow/tfjs
为了加载转换完成的模型文件,我们需要安装 tfjs-converter 和 @tensorflow/tfjs 模块:
import * as tf from '@tensorflow/tfjs'
const MODEL_URL = '/mobilenet/tfjs_model/model.json'
const model = await tf.loadGraphModel(MODEL_URL)
const cat = document.getElementById('cat')
model.execute(tf.browser.fromPixels(cat))
然后,我们就可以通过 JavaScript 来加载 TensorFlow 模型了
使用 TensorFlow.js 模型库
模型库 GitHub 地址:https://github.com/tensorflow/tfjs-models,其中模型分类包括图像识别、语音识别、人体姿态识别、物体识别、文字分类等。
在程序内使用模型 API 时要提供 modelUrl 的参数,可以指向谷歌中国的镜像服务器。
谷歌云的 base url 是 https://storage.googleapis.com
中国镜像的 base url 是 https://www.gstaticcnapps.cn
模型的 url path 是一致的。以 posenet 模型为例:
谷歌云地址是:https://storage.googleapis.com/tfjs-models/savedmodel/posenet/mobilenet/float/050/model-stride16.json
中国镜像地址是:https://www.gstaticcnapps.cn/tfjs-models/savedmodel/posenet/mobilenet/float/050/model-stride16.json
在浏览器中使用 MobileNet 进行摄像头物体识别
<head>
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<script src="https://unpkg.com/@tensorflow-models/mobilenet"> </script>
</head>
我们建立一个 HTML 文件,在头信息中,通过将 NPM 模块转换为在线可以引用的免费服务 unpkg.com,来加载 @tensorflow/tfjs 和 @tensorflow-models/mobilenet 两个 TFJS 模块
<video width=400 height=300></video>
<p></p>
<img width=400 height=300 />
我们声明三个 HTML 元素:用来显示视频的<video>,用来显示我们截取特定帧的 <img>,和用来显示检测文字结果的 <p>:
const video = document.querySelector('video')
const image = document.querySelector('img')
const status = document.querySelector("p")
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
let model
我们通过 JavaScript ,将对应的 HTML 元素进行初始化:video, image, status 三个变量分别用来对应 <video>, <img>, <p> 三个 HTML 元素,canvas 和 ctx 用来做从摄像头获取视频流数据的中转存储。model 将用来存储我们从网络上加载的 MobileNet:
async function main () {
status.innerText = "Model loading..."
model = await mobilenet.load()
status.innerText = "Model is loaded!"
const stream = await navigator.mediaDevices.getUserMedia({ video: true })
video.srcObject = stream
await video.play()
canvas.width = video.videoWidth
canvas.height = video.videoHeight
refresh()
}
main() 用来初始化整个系统,完成加载 MobileNet 模型,将用户摄像头的数据绑定 <video> 这个 HTML 元素上,最后触发 refresh() 函数,进行定期刷新操作
async function refresh(){
ctx.drawImage(video, 0,0)
image.src = canvas.toDataURL('image/png')
await model.load()
const predictions = await model.classify(image)
const className = predictions[0].className
const percentage = Math.floor(100 * predictions[0].probability)
status.innerHTML = percentage + '%' + ' ' + className
setTimeout(refresh, 100)
}
refresh() 函数,用来从视频中取出当前一帧图像,然后通过 MobileNet 模型进行分类,并将分类结果,显示在网页上。然后,通过 setTimeout,重复执行自己,实现持续对视频图像进行处理的功能
<html> <head>
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<script src="https://unpkg.com/@tensorflow-models/mobilenet"> </script>
</head> <video width=400 height=300></video>
<p></p>
<img width=400 height=300 /> <script>
const video = document.querySelector('video')
const image = document.querySelector('img')
const status = document.querySelector("p") const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d') let model main() async function main () {
status.innerText = "Model loading..."
model = await mobilenet.load()
status.innerText = "Model is loaded!" const stream = await navigator.mediaDevices.getUserMedia({ video: true })
video.srcObject = stream
await video.play() canvas.width = video.videoWidth
canvas.height = video.videoHeight refresh()
} async function refresh(){
ctx.drawImage(video, 0,0)
image.src = canvas.toDataURL('image/png') await model.load()
const predictions = await model.classify(image) const className = predictions[0].className
const percentage = Math.floor(100 * predictions[0].probability) status.innerHTML = percentage + '%' + ' ' + className setTimeout(refresh, 100)
} </script> </html>
完整的 HTML 代码
TensorFlow.js 模型训练 *
与 TensorFlow Serving 和 TensorFlow Lite 不同,TensorFlow.js 不仅支持模型的部署和推断,还支持直接在 TensorFlow.js 中进行模型训练、
基础章节中,我们已经用 Python 实现过,针对某城市在 2013-2017 年的房价的任务,通过对该数据进行线性回归,即使用线性模型 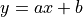 来拟合上述数据,此处
来拟合上述数据,此处  和
和 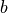 是待求的参数。
是待求的参数。
下面我们改用 TensorFlow.js 来实现一个 JavaScript 版本。
const xsRaw = tf.tensor([2013, 2014, 2015, 2016, 2017])
const ysRaw = tf.tensor([12000, 14000, 15000, 16500, 17500]) // 归一化
const xs = xsRaw.sub(xsRaw.min())
.div(xsRaw.max().sub(xsRaw.min()))
const ys = ysRaw.sub(ysRaw.min())
.div(ysRaw.max().sub(ysRaw.min()))
首先,我们定义数据,进行基本的归一化操作。
const a = tf.scalar(Math.random()).variable()
const b = tf.scalar(Math.random()).variable() // y = a * x + b.
const f = (x) => a.mul(x).add(b)
const loss = (pred, label) => pred.sub(label).square().mean() const learningRate = 1e-3
const optimizer = tf.train.sgd(learningRate) // 训练模型
for (let i = 0; i < 10000; i++) {
optimizer.minimize(() => loss(f(xs), ys))
} // 预测
console.log(`a: ${a.dataSync()}, b: ${b.dataSync()}`)
const preds = f(xs).dataSync()
const trues = ys.arraySync()
preds.forEach((pred, i) => {
console.log(`x: ${i}, pred: ${pred.toFixed(2)}, true: ${trues[i].toFixed(2)}`)
})
接下来,我们来求线性模型中两个参数 a 和 b 的值。
loss() 计算损失; 使用 optimizer.minimize() 自动更新模型参数。=>)来简化函数的声明和书写dataSync()同步函数
<html>
<head>
<script src="http://unpkg.com/@tensorflow/tfjs/dist/tf.min.js"></script>
<script>
const xsRaw = tf.tensor([2013, 2014, 2015, 2016, 2017])
const ysRaw = tf.tensor([12000, 14000, 15000, 16500, 17500]) // 归一化
const xs = xsRaw.sub(xsRaw.min())
.div(xsRaw.max().sub(xsRaw.min()))
const ys = ysRaw.sub(ysRaw.min())
.div(ysRaw.max().sub(ysRaw.min())) const a = tf.scalar(Math.random()).variable()
const b = tf.scalar(Math.random()).variable() // y = a * x + b.
const f = (x) => a.mul(x).add(b)
const loss = (pred, label) => pred.sub(label).square().mean() const learningRate = 1e-3
const optimizer = tf.train.sgd(learningRate) // 训练模型
for (let i = 0; i < 10000; i++) {
optimizer.minimize(() => loss(f(xs), ys))
} // 预测
console.log(`a: ${a.dataSync()}, b: ${b.dataSync()}`)
const preds = f(xs).dataSync()
const trues = ys.arraySync()
preds.forEach((pred, i) => {
console.log(`x: ${i}, pred: ${pred.toFixed(2)}, true: ${trues[i].toFixed(2)}`)
})
</script>
</head>
</html>
可以直接在浏览器中运行,完整的 HTML 代码
TensorFlow.js 性能对比
基于 MobileNet 的评测
与 TensorFlow Lite 代码基准相比,手机浏览器中的 TensorFlow.js 在 IPhoneX 上的运行时间为基准的 1.2 倍,在 Pixel3 上运行的时间为基准的 1.8 倍。
与 Python 代码基准相比,浏览器中的 TensorFlow.js 在 CPU 上的运行时间为基准的 1.7 倍,在 GPU (WebGL) 上运行的时间为基准的 3.8 倍。
与 Python 代码基准相比,Node.js 的 TensorFlow.js 在 CPU 上的运行时间与基准相同,在 GPU(CUDA) 上运行的时间是基准的 1.6 倍。
TensorFlow 分布式训练
TensorFlow 在 tf.distribute.Strategy 中为我们提供了若干种分布式策略,使得我们能够更高效地训练模型。
单机多卡训练: MirroredStrategy
strategy = tf.distribute.MirroredStrategy()
实例化一个 MirroredStrategy 策略:
可以在参数中指定设备,如:
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
即指定只使用第 0、1 号 GPU 参与分布式策略。
with strategy.scope():
# 模型构建代码
将模型构建的代码放入 strategy.scope() 的上下文环境中
import tensorflow as tf
import tensorflow_datasets as tfds num_epochs = 5
batch_size_per_replica = 64
learning_rate = 0.001 strategy = tf.distribute.MirroredStrategy()
print('Number of devices: %d' % strategy.num_replicas_in_sync) # 输出设备数量
batch_size = batch_size_per_replica * strategy.num_replicas_in_sync # 载入数据集并预处理
def resize(image, label):
image = tf.image.resize(image, [224, 224]) / 255.0
return image, label # 使用 TensorFlow Datasets 载入猫狗分类数据集,详见“TensorFlow Datasets数据集载入”一章
dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(resize).shuffle(1024).batch(batch_size) with strategy.scope():
model = tf.keras.applications.MobileNetV2()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
) model.fit(dataset, epochs=num_epochs)
在 TensorFlow Datasets 中的部分图像数据集上使用 Keras 训练 MobileNetV2 的过程
多机训练: MultiWorkerMirroredStrategy
将 MirroredStrategy 更换为适合多机训练的 MultiWorkerMirroredStrategy 即可。不过,由于涉及到多台计算机之间的通讯,还需要进行一些额外的设置。具体而言,需要设置环境变量 TF_CONFIG
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["localhost:20000", "localhost:20001"]
},
'task': {'type': 'worker', 'index': 0}
})
示例
TF_CONFIG 由 cluster 和 task 两部分组成:
cluster说明了整个多机集群的结构和每台机器的网络地址(IP + 端口号)。对于每一台机器,cluster的值都是相同的;task说明了当前机器的角色。例如,{'type': 'worker', 'index': 0}说明当前机器是cluster中的第 0 个 worker(即localhost:20000)。每一台机器的task值都需要针对当前主机进行分别的设置。
请在各台机器上均注意防火墙的设置,尤其是需要开放与其他主机通信的端口。如上例的 0 号 worker 需要开放 20000 端口,1 号 worker 需要开放 20001 端口。
import tensorflow as tf
import tensorflow_datasets as tfds
import os
import json num_epochs = 5
batch_size_per_replica = 64
learning_rate = 0.001 num_workers = 2
os.environ['TF_CONFIG'] = json.dumps({
'cluster': {
'worker': ["localhost:20000", "localhost:20001"]
},
'task': {'type': 'worker', 'index': 0}
})
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
batch_size = batch_size_per_replica * num_workers def resize(image, label):
image = tf.image.resize(image, [224, 224]) / 255.0
return image, label dataset = tfds.load("cats_vs_dogs", split=tfds.Split.TRAIN, as_supervised=True)
dataset = dataset.map(resize).shuffle(1024).batch(batch_size) with strategy.scope():
model = tf.keras.applications.MobileNetV2()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]
) model.fit(dataset, epochs=num_epochs)
假设我们有两台机器,即首先在两台机器上均部署下面的程序,唯一的区别是 task 部分,第一台机器设置为 {'type': 'worker', 'index': 0} ,第二台机器设置为 {'type': 'worker', 'index': 1} 。接下来,在两台机器上依次运行程序,待通讯成功后,即会自动开始训练流程。
在所有机器性能接近的情况下,训练时长与机器的数目接近于反比关系。
使用TPU训练TensorFlow模型
TPU 代表 Tensor Processing Unit (张量处理单元)
免费 TPU:Google Colab
最方便使用 TPU 的方法,就是使用 Google 的 Colab ,不但通过浏览器访问直接可以用,而且还免费。
在 Google Colab 的 Notebook 界面中,打开界面中,打开主菜单 Runtime ,然后选择 Change runtime type,会弹出 Notebook settings 的窗口。选择里面的 Hardware accelerator为 TPU 就可以了。
import os
import pprint
import tensorflow as tf if 'COLAB_TPU_ADDR' not in os.environ:
print('ERROR: Not connected to a TPU runtime')
else:
tpu_address = 'grpc://' + os.environ['COLAB_TPU_ADDR']
print ('TPU address is', tpu_address) with tf.Session(tpu_address) as session:
devices = session.list_devices() print('TPU devices:')
pprint.pprint(devices)
确认 Colab Notebook 中的确分配了 TPU 资源,我们可以运行以下测试代码
Cloud TPU
在 Google Cloud 上,我们可以购买所需的 TPU 资源,用来按需进行机器学习训练。为了使用 Cloud TPU ,需要在 Google Cloud Engine 中启动 VM 并为 VM 请求 Cloud TPU 资源。请求完成后,VM 就可以直接访问分配给它专属的 Cloud TPU了。
Source: TPUs for Developers
在使用 Cloud TPU 时,为了免除繁琐的驱动安装,我们可以通过直接使用 Google Cloud 提供的 VM 操作系统镜像。
TPU 基础使用
在 TPU 上进行 TensorFlow 分布式训练的核心API是 tf.distribute.TPUStrategy ,可以简单几行代码就实现在 TPU 上的分布式训练,同时也可以很容易的迁移到 GPU单机多卡、多机多卡的环境。
resolver = tf.distribute.resolver.TPUClusterResolver(
tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_host(resolver.master())
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver)
实例化 TPUStrategy
以下使用 Fashion MNIST 分类任务展示 TPU 的使用方式。本小节的源代码可以在 https://github.com/huan/tensorflow-handbook-tpu 找到。
更方便的是在 Google Colab 上直接打开本例子的 Jupyter 直接运行,地址:https://colab.research.google.com/github/huan/tensorflow-handbook-tpu/blob/master/tensorflow-handbook-tpu-example.ipynb (推荐)
import tensorflow as tf
import numpy as np
import os (x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() # add empty color dimension
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1) def create_model():
model = tf.keras.models.Sequential() model.add(tf.keras.layers.Conv2D(64, (3, 3), input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2,2)))
model.add(tf.keras.layers.Activation('relu')) model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax')) return model resolver = tf.distribute.resolver.TPUClusterResolver(
tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
tf.config.experimental_connect_to_host(resolver.master())
tf.tpu.experimental.initialize_tpu_system(resolver)
strategy = tf.distribute.experimental.TPUStrategy(resolver) with strategy.scope():
model = create_model()
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-3),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=[tf.keras.metrics.sparse_categorical_accuracy]) model.fit(
x_train.astype(np.float32), y_train.astype(np.float32),
epochs=5,
steps_per_epoch=60,
validation_data=(x_test.astype(np.float32), y_test.astype(np.float32)),
validation_freq=5
)
三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速的更多相关文章
- 三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 前文:三分钟快速上手TensorFlow 2.0 (上)——前置基础.模型建立与可视化 tf.train. ...
- 三分钟快速上手TensorFlow 2.0 (上)——前置基础、模型建立与可视化
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 学习笔记类似提纲,具体细节参照上文链接 一些前置的基础 随机数 tf.random uniform(sha ...
- 三分钟快速上手TensorFlow 2.0 (后续)——扩展和附录
TensorFlow Hub 模型复用 TF Hub 网站 打开主页 https://tfhub.dev/ ,在左侧有 Text.Image.Video 和 Publishers 等选项,可以选取关注 ...
- 【Microsoft Azure 的1024种玩法】一.一分钟快速上手搭建宝塔管理面板
简介 宝塔Linux面板是提升运维效率的服务器管理软件,其支持一键LAMP/LNMP/集群/监控/网站/FTP/数据库/JAVA等100多项服务器管理功能.今天带大家一起学习的内容为一分钟快速上手搭建 ...
- 三分钟掌控Actor模型和CSP模型
回顾一下前文<三分钟掌握共享内存模型和 Actor模型> Actor vs CSP模型 传统多线程的的共享内存(ShareMemory)模型使用lock,condition等同步原语来强行 ...
- 【PyTorch v1.1.0文档研习】60分钟快速上手
阅读文档:使用 PyTorch 进行深度学习:60分钟快速入门. 本教程的目标是: 总体上理解 PyTorch 的张量库和神经网络 训练一个小的神经网络来进行图像分类 PyTorch 是个啥? 这是基 ...
- 十分钟快速上手NutUI
本文将会从 NutUI 初学者的使用入手,对 NutUI 做了一个快速的概述,希望能帮助新人在项目中快速上手. 文章包括以下主要内容 安装引入 NutUI NutUI 组件的使用 NutUI 主题和样 ...
- 三分钟快速搭建分布式高可用的Redis集群
这里的Redis集群指的是Redis Cluster,它是Redis在3.0版本正式推出的专用集群方案,有效地解决了Redis分布式方面的需求.当单机内存.并发.流量等遇到瓶颈的时候,可以采用这种Re ...
- 推荐一款全能测试开发神器:Mockoon!1分钟快速上手!
1. 说一下背景 在日常开发或者测试工作中,经常会因为下游服务不可用或者不稳定时,通过工具或者技术手段去模拟一个HTTP Server,或者模拟所需要的接口数据. 这个时候,很多人脑海里,都会想到可以 ...
随机推荐
- 深入浅出Mybatis系列十-SQL执行流程分析(源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前 ...
- 《趣谈 Linux 操作系统》学习笔记(二):对 Linux 操作系统的理解
首先,我们知道操作系统是管理和控制计算机硬件与软件资源的计算机程序.这里把操作系统想象为一个软件外包公司,其内核就相当于这家外包公司的老板,那么我们可以把自己的角色切换成这家外包公司的老板,设身处地的 ...
- 咸鱼的ACM之路:动态规划(DP)学习记录
按挑战程序设计竞赛介绍的顺序记录一遍学习DP的过程. 1. 01背包问题 问题如下: 有N个物品,每个物品(N[i])都有一定的体积(W[i]),和一定的价值(V[i]) 现在给定一个背包,背包的容量 ...
- 知乎-如何rebuttal
作者:魏秀参链接:https://zhuanlan.zhihu.com/p/104298923来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 学术论文是发布自己或团队最 ...
- 用cookie存值
////用Request获取到客户端Cookie 判断是否为空 //if (Request.Cookies["CheckTime"] == null) //{ // //创建Coo ...
- 三分钟学会.NET Core Jwt 策略授权认证
一.前言 大家好我又回来了,前几天讲过一个关于Jwt的身份验证最简单的案例,但是功能还是不够强大,不适用于真正的项目,是的,在真正面对复杂而又苛刻的客户中,我们会不知所措,就现在需要将认证授权这一块也 ...
- yii2 钩子函数
插入时间 public function beforeSave($insert) { $this->created_at=time(); return parent::beforeSave($i ...
- Git操作时遇到的一些问题和相应的处理方式
Q1:如何解决冲突/避免冲突 A1:执行git fetch之后,本地可能会存在冲突. 如果希望合并本地修改内容,需要执行git merge.不过当有修改内容未提交时,不能merge,要么把修改内容提交 ...
- 插入jupyter notebook代码
<iframe src="https://nbviewer.jupyter.org/gist/gaowenxin95/53408e0f1ce268430efaad2cb1f0ca4f& ...
- 微信小程序判断input是否为空
微信小程序中用到input值时候,判断其内容是否为空,可以用if-else判断内容的length,也可以给input加点击事件,判断其内容:以下是我解决问题的过程wxml代码 <view cla ...