Go_bufio包
bufio 是通过缓冲来提高效率。
io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
简单的说就是,把文件读取进缓冲(内存)之后再读取的时候就可以避免文件系统的io 从而提高速度。同理,在进行写操作时,先把文件写入缓冲(内存),然后由缓冲写入文件系统。看完以上解释有人可能会表示困惑了,直接把 内容->文件 和 内容->缓冲->文件相比, 缓冲区好像没有起到作用嘛。其实缓冲区的设计是为了存储多次的写入,最后一口气把缓冲区内容写入文件。
bufio 封装了io.Reader或io.Writer接口对象,并创建另一个也实现了该接口的对象。
io.Reader或io.Writer 接口实现read() 和 write() 方法,对于实现这个接口的对象都是可以使用这两个方法的。
Reader对象
bufio.Reader 是bufio中对io.Reader 的封装
// Reader implements buffering for an io.Reader object.
type Reader struct {
buf []byte
rd io.Reader // reader provided by the client
r, w int // buf read and write positions
err error
lastByte int // last byte read for UnreadByte; -1 means invalid
lastRuneSize int // size of last rune read for UnreadRune; -1 means invalid
}
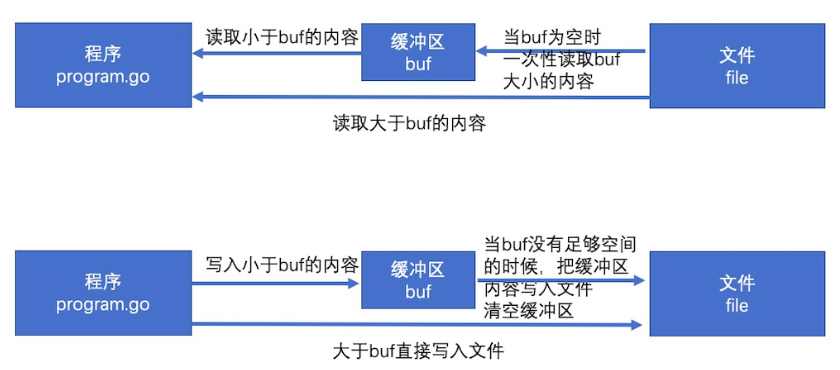
bufio.Read(p []byte) 相当于读取大小len(p)的内容,思路如下:
当缓存区有内容的时,将缓存区内容全部填入p并清空缓存区
当缓存区没有内容的时候且len(p)>len(buf),即要读取的内容比缓存区还要大,直接去文件读取即可
当缓存区没有内容的时候且len(p)<len(buf),即要读取的内容比缓存区小,缓存区从文件读取内容充满缓存区,并将p填满(此时缓存区有剩余内容)
以后再次读取时缓存区有内容,将缓存区内容全部填入p并清空缓存区(此时和情况1一样)
package main import (
"os"
"fmt"
"bufio"
) func main() {
/*
bufio:高效io读写
buffer缓存
io:input/output 将io包下的Reader,Write对象进行包装,带缓存的包装,提高读写的效率 ReadBytes()
ReadString()
ReadLine() */ fileName := "/Users/ruby/Documents/pro/a/english.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Println(err)
return
}
defer file.Close() //创建Reader对象
b1 := bufio.NewReader(file)
//1.Read(),高效读取
p := make([]byte, 1024)
n1, err := b1.Read(p)
fmt.Println(n1)
fmt.Println(string(p[:n1])) //2.ReadLine() 不建议使用,太low了
data, flag, err := b1.ReadLine()
fmt.Println(flag)
fmt.Println(err)
fmt.Println(data)
fmt.Println(string(data)) //3.ReadString()
//读取一行,分隔符就是\n
s1, err := b1.ReadString('\n')
fmt.Println(err)
fmt.Println(s1) s1, err = b1.ReadString('\n')
fmt.Println(err)
fmt.Println(s1) s1, err = b1.ReadString('\n')
fmt.Println(err)
fmt.Println(s1) for {
s1, err := b1.ReadString('\n')
if err == io.EOF {
fmt.Println("读取完毕。。")
break
}
fmt.Println(s1)
} //4.ReadBytes() //读取多个字节
data, err := b1.ReadBytes('\n')
fmt.Println(err)
fmt.Println(string(data)) //Scanner
s2 := ""
fmt.Scanln(&s2) //读取键盘输入
fmt.Println(s2) //中间有空格的话,只能读取空格前面的 b2 := bufio.NewReader(os.Stdin)
s2, _ := b2.ReadString('\n') //读取到换行,中间有空格也没事
fmt.Println(s2) }
Writer对象
bufio.Writer 是bufio中对io.Writer 的封装
// Writer implements buffering for an io.Writer object.
// If an error occurs writing to a Writer, no more data will be
// accepted and all subsequent writes, and Flush, will return the error.
// After all data has been written, the client should call the
// Flush method to guarantee all data has been forwarded to
// the underlying io.Writer.
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}
bufio.Write(p []byte) 的思路如下
判断buf中可用容量是否可以放下 p
如果能放下,直接把p拼接到buf后面,即把内容放到缓冲区
如果缓冲区的可用容量不足以放下,且此时缓冲区是空的,直接把p写入文件即可
如果缓冲区的可用容量不足以放下,且此时缓冲区有内容,则用p把缓冲区填满,把缓冲区所有内容写入文件,并清空缓冲区
判断p的剩余内容大小能否放到缓冲区,如果能放下(此时和步骤1情况一样)则把内容放到缓冲区
如果p的剩余内容依旧大于缓冲区,(注意此时缓冲区是空的,情况和步骤3一样)则把p的剩余内容直接写入文件
package main import (
"os"
"fmt"
"bufio"
) func main() {
/*
bufio:高效io读写
buffer缓存
io:input/output 将io包下的Reader,Write对象进行包装,带缓存的包装,提高读写的效率 func (b *Writer) Write(p []byte) (nn int, err error)
func (b *Writer) WriteByte(c byte) error
func (b *Writer) WriteRune(r rune) (size int, err error)
func (b *Writer) WriteString(s string) (int, error) */ fileName := "/Users/ruby/Documents/pro/a/cc.txt"
file,err := os.OpenFile(fileName,os.O_CREATE|os.O_WRONLY,os.ModePerm)
if err != nil{
fmt.Println(err)
return
}
defer file.Close() w1 := bufio.NewWriter(file)
//n,err := w1.WriteString("helloworld")
//fmt.Println(err)
//fmt.Println(n)
//w1.Flush() //刷新缓冲区 for i:=1;i<=1000;i++{
w1.WriteString(fmt.Sprintf("%d:hello",i))
}
w1.Flush()
}
Go_bufio包的更多相关文章
- Npm包的开发
个人开发包的目录结构 ├── coverage //istanbul测试覆盖率生成的文件 ├── index.js //入口文件 ├── introduce.md //说明文件 ├── lib │ ...
- Windows server 2012 添加中文语言包(英文转为中文)(离线)
Windows server 2012 添加中文语言包(英文转为中文)(离线) 相关资料: 公司环境:亚马孙aws虚拟机 英文版Windows2012 中文SQL Server2012安装包,需要安装 ...
- 如何在nuget上传自己的包+搭建自己公司的NuGet服务器(新方法)
运维相关:http://www.cnblogs.com/dunitian/p/4822808.html#iis 先注册一个nuget账号https://www.nuget.org/ 下载并安装一下Nu ...
- android http 抓包
有时候想开发的时候想看APP发出的http请求和响应是什么,这就需要抓包了,这可以得到一些不为人知的api,比如还可以干些“坏事”... 需要工具: Fiddler2 抓包(点击下载) Android ...
- 带你实现开发者头条APP(四)---首页优化(加入design包)
title: 带你实现开发者头条APP(四)---首页优化(加入design包) tags: design,Toolbar,TabLayout,RecyclerView grammar_cjkRuby ...
- git克隆项目到本地&&全局安装依赖项目&&安装依赖包&&启动服务
一.安装本地开发环境 1.安装本项目 在需要保存到本地的项目的文件夹,进入到文件夹里点击右键,bash here,出现下图: 2.安装依赖项目 3.安装依赖包(进入到命令行) # 安装依赖包 $ ...
- 关于Visual Studio 未能加载各种Package包的解决方案
问题: 打开Visual Studio 的时候,总提示未能加载相应的Package包,有时候还无法打开项目,各种提示 解决方案: 进入用户目录 C:\Users\用户名\AppData\Local\M ...
- VS项目中使用Nuget还原包后编译生产还一直报错?
Nuget官网下载Nuget项目包的命令地址:https://www.nuget.org/packages 今天就遇到一个比较奇葩的问题,折腾了很久终于搞定了: 问题是这样的:我的解决方案原本是好好的 ...
- 用Java代码实现拦截区域网数据包
起因: 吃饭的时间在想如果区域网内都是通过路由器上网,那如何实现拦截整个区域网的数据包,从而实现某种窥探欲. 思路: 正常是通过电脑网卡预先设置或分配的IP+网关对路由器进行通讯,比如访问百 ...
随机推荐
- 记录 Docker 的学习过程 (单机编排)
容器的编排 什么是容器的编排?就是让容器有序的启动并在启动的过程加以控制 docker-compose -f bainpaiwenjian.yul up 如果编排文件为默认名称docker-compo ...
- Initialization of bean failed; nested exception is java.lang.NoClassDefFoundError: org/objectweb/asm/Type
问题描述 将项目挂载到 Myeclipse 的 tomcat 上,启动 tomcat ,报错“Initialization of bean failed; nested exception is ja ...
- Python 序列化与反序列化
序列化是为了将内存中的字典.列表.集合以及各种对象,保存到一个文件中(字节流).而反序列化是将字节流转化回原始的对象的一个过程. json库 序列化:json.dumps() 反序列化:json.lo ...
- Docker最全教程——从理论到实战(十四)
本篇教程主要讲解基于容器服务搭建TeamCity服务,并且完成内部项目的CI流程配置.教程中也分享了一个简单的CI.CD流程,仅作探讨.不过由于篇幅有限,完整的DevOps,我们后续独立探讨. 为了降 ...
- int*v=newint[src.cols*4]
在学习:使用OpenCV2.x计算图像的水平和垂直积分投影中,有下图一种代码: 对比上面两个代码对于同一张图片求得的结果会发现不同: 为什么会出现这个原因呢?不知道为啥这样初始化? 首先查看一下图片深 ...
- shell脚本编程学习笔记(一)
一.脚本格式 vim shell.sh #!/bin/bash //声明脚本解释器,这个‘#’号不是注释,其余是注释 #Program: //程序内容说明 #History: //时间和作者 二.sh ...
- 洛谷P1051 谁拿了最多奖学金
https://www.luogu.org/problem/P1051 #include<bits/stdc++.h> using namespace std; struct node { ...
- 错误:pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', ...
- java简单学生成绩管理系统
题目要求: 一. 数据结构要求:(5 分) 1.定义 ScoreInformation 类,其中包括七个私有变量(stunumber, name, mathematicsscore, englishi ...
- SSH后台分页
初学SSH,开始用的Struts2+Hibernate3+Spring3,Hibernate中用的HibernateTemplate进行数据库的操作.之后在进行前台页面显示的时候,要用到分页,查了一下 ...