SQL语句中exists和in的区别
转自https://www.cnblogs.com/liyasong/p/sql_in_exists.html 和 http://blog.csdn.net/lick4050312/article/details/4476333
表展示
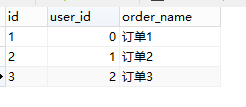
查询中涉及到的两个表,一个user和一个order表,具体表的内容如下:
user表:
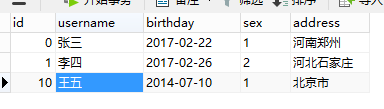
order表:
in
一、确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
具体sql语句如下:

1 SELECT
2 *
3 FROM
4 `user`
5 WHERE
6 `user`.id IN (
7 SELECT
8 `order`.user_id
9 FROM
10 `order`
11 )
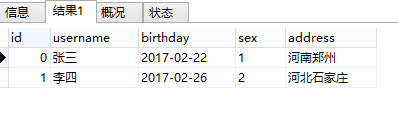
这条语句很简单,通过子查询查到的user_id 的数据,去匹配user表中的id然后得到结果。该语句执行结果如下:

它的执行流程是什么样子的呢?让我们一起来看一下。
首先,在数据库内部,查询子查询,执行如下代码:
SELECT
`order`.user_id
FROM
`order`
执行完毕后,得到结果如下:

此时,将查询到的结果和原有的user表做一个笛卡尔积,结果如下:
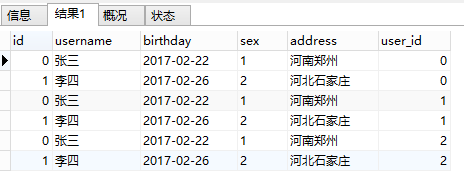
此时,再根据我们的user.id IN order.user_id的条件,将结果进行筛选(既比较id列和user_id 列的值是否相等,将不相等的删除)。最后,得到两条符合条件的数据。
二、select * from A where id in(select id from B)
以上查询使用了in语句,in()只执行一次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录. 它的查询过程类似于以下过程
List resultSet=[]; Array A=(select * from A); Array B=(select id from B);
for(int i=0;i<A.length;i++) { for(int j=0;j<B.length;j++) { if(A[i].id==B[j].id) { resultSet.add(A[i]); break; } } } return resultSet;
可以看出,当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次. 如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差. 再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升.
结论:in()适合B表比A表数据小的情况
exists
一、指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
具体sql语句如下:
1 SELECT
2 `user`.*
3 FROM
4 `user`
5 WHERE
6 EXISTS (
7 SELECT
8 `order`.user_id
9 FROM
10 `order`
11 WHERE
12 `user`.id = `order`.user_id
13 )
这条sql语句的执行结果和上面的in的执行结果是一样的。

但是,不一样的是它们的执行流程完全不一样:
使用exists关键字进行查询的时候,首先,我们先查询的不是子查询的内容,而是查我们的主查询的表,也就是说,我们先执行的sql语句是:
SELECT `user`.* FROM `user`
得到的结果如下:

然后,根据表的每一条记录,执行以下语句,依次去判断where后面的条件是否成立:
EXISTS (
SELECT
`order`.user_id
FROM
`order`
WHERE
`user`.id = `order`.user_id
)
如果成立则返回true不成立则返回false。如果返回的是true的话,则该行结果保留,如果返回的是false的话,则删除该行,最后将得到的结果返回。
二、select a.* from A a where exists(select 1 from B b where a.id=b.id)
以上查询使用了exists语句,exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false. 它的查询过程类似于以下过程
List resultSet=[]; Array A=(select * from A)
for(int i=0;i<A.length;i++) { if(exists(A[i].id) { //执行select 1 from B b where b.id=a.id是否有记录返回 resultSet.add(A[i]); } } return resultSet;
当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行. 如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等. 如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果. 再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
结论:exists()适合B表比A表数据大的情况
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.
区别及应用场景
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询,所以我们会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,另外IN时不对NULL进行处理。
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
等价语句
SELECT /*+ PARALLEL*/ 'HL',T1.*,SYSDATE,'2017-05' FROM DC_ALL_HL.V_OFFER_INST_INFO T1
WHERE T1.PROD_INST_ID IN ( SELECT PROD_INST_ID FROM AUDI_SAMPLE_HL); SELECT /*+ PARALLEL(T1,50)*/ 'HL',T1.*,SYSDATE,'2017-05' FROM DC_ALL_HL.V_OFFER_INST_INFO T1
WHERE EXISTS (
SELECT * FROM AUDI_SAMPLE_HL AU where T1.PROD_INST_ID = AU.PROD_INST_ID);
not in 和not exists
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
比如在Northwind数据库中有一个查询为 SELECT c.CustomerId,CompanyName FROM Customers c WHERE EXISTS( SELECT OrderID FROM Orders o WHERE o.CustomerID=c.CustomerID) 这里面的EXISTS是如何运作呢?子查询返回的是OrderId字段,可是外面的查询要找的是CustomerID和CompanyName字段,这两个字段肯定不在OrderID里面啊,这是如何匹配的呢?
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False EXISTS 指定一个子查询,检测 行 的存在。
语法: EXISTS subquery 参数: subquery 是一个受限的 SELECT 语句 (不允许有 COMPUTE 子句和 INTO 关键字)。 结果类型: Boolean 如果子查询包含行,则返回 TRUE ,否则返回 FLASE 。
| 例表A:TableIn | 例表B:TableEx |
 |
 |
(一). 在子查询中使用 NULL 仍然返回结果集 select * from TableIn where exists(select null) 等同于: select * from TableIn
(二). 比较使用 EXISTS 和 IN 的查询。注意两个查询返回相同的结果。 select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME) select * from TableIn where ANAME in(select BNAME from TableEx)

(三). 比较使用 EXISTS 和 = ANY 的查询。注意两个查询返回相同的结果。 select * from TableIn where exists(select BID from TableEx where BNAME=TableIn.ANAME) select * from TableIn where ANAME=ANY(select BNAME from TableEx)
NOT EXISTS 的作用与 EXISTS 正好相反。如果子查询没有返回行,则满足了 NOT EXISTS 中的 WHERE 子句。
结论: EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。 EXISTS内部有一个子查询语句(SELECT ... FROM...), 我将其称为EXIST的内查询语句。其内查询语句返回一个结果集。 EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
分析器会先看语句的第一个词,当它发现第一个词是SELECT关键字的时候,它会跳到FROM关键字,然后通过FROM关键字找到表名并把表装入内存。接着是找WHERE关键字,如果找不到则返回到SELECT找字段解析,如果找到WHERE,则分析其中的条件,完成后再回到SELECT分析字段。最后形成一张我们要的虚表。 WHERE关键字后面的是条件表达式。条件表达式计算完成后,会有一个返回值,即非0或0,非0即为真(true),0即为假(false)。同理WHERE后面的条件也有一个返回值,真或假,来确定接下来执不执行SELECT。 分析器先找到关键字SELECT,然后跳到FROM关键字将STUDENT表导入内存,并通过指针找到第一条记录,接着找到WHERE关键字计算它的条件表达式,如果为真那么把这条记录装到一个虚表当中,指针再指向下一条记录。如果为假那么指针直接指向下一条记录,而不进行其它操作。一直检索完整个表,并把检索出来的虚拟表返回给用户。EXISTS是条件表达式的一部分,它也有一个返回值(true或false)。
在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,可以通过使用 EXISTS 条件句防止插入重复记录。 INSERT INTO TableIn (ANAME,ASEX) SELECT top 1 '张三', '男' FROM TableIn WHERE not exists (select * from TableIn where TableIn.AID = 7)
EXISTS与IN的使用效率的问题,通常情况下采用exists要比in效率高,因为IN不走索引,但要看实际情况具体使用: IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
SQL语句中exists和in的区别的更多相关文章
- 数据库sql语句的exists和in的区别
性能变化的关键: #1 执行的先后顺序 谁是驱动表,谁先执行查询,谁后执行查询 #2 执行过程 exists的优点是:只要存在就返回了,这样的话很有可能不需要扫描整个表. in需要扫描完整个表,并 ...
- SQL 语句中 exists和not exists的用法
exists (sql 返回结果集,为真) not exists (sql 不返回结果集,为真) 如下: 表A ID NAME ...
- SQL语句中exists/not exists的用法分析
作者:Dsw 比如在Northwind数据库中有一个查询为 SELECT c.CustomerId,CompanyName FROM Customers c WHERE EXISTS( SELECT ...
- sql语句中where和having的区别
WHERE语句在GROUPBY语句之前:SQL会在分组之前计算WHERE语句. HAVING语句在GROUPBY语句之后:SQL会在分组之后计算HAVING语句.
- SQL语句中SUM与COUNT的区别
SUM是对符合条件的记录的数值列求和 COUNT 是对查询中符合条件的结果(或记录)的个数 例如: 表fruit id name price 1 apple 3.00 2 ...
- SQL语句中in 与 exists的区别
SQL语句中in 与 exists的区别 SQL中EXISTS检查是否有结果,判断是否有记录,返回的是一个布尔型(true/false); IN是对结果值进行比较,判断一个字段是否存在于几个值的范围中 ...
- 解析sql语句中left_join、inner_join中的on与where的区别
以下是对在sql语句中left_join.inner_join中的on与where的区别进行了详细的分析介绍,需要的朋友可以参考下 table a(id, type):id type ---- ...
- SQL语句中count(1)count(*)count(字段)用法的区别
SQL语句中count(1)count(*)count(字段)用法的区别 在SQL语句中count函数是最常用的函数之一,count函数是用来统计表中记录数的一个函数, 一. count(1)和cou ...
- SQL点滴35—SQL语句中的exists
原文:SQL点滴35-SQL语句中的exists 比如在Northwind数据库中有一个查询为 SELECT c.CustomerId,CompanyName FROM Customers c WHE ...
随机推荐
- Ruby 数据类型
Ruby 数据类型 本章节我们将为大家介绍 Ruby 的基本数据类型. Ruby支持的数据类型包括基本的Number.String.Ranges.Symbols,以及true.false和nil这几个 ...
- R语言 变量
R语言变量 变量为我们提供了我们的程序可以操作的命名存储. R语言中的变量可以存储原子向量,原子向量组或许多Robject的组合. 有效的变量名称由字母,数字和点或下划线字符组成. 变量名以字母或不以 ...
- 2019.7.3模拟 光影交错(穷举+概率dp)
题目大意: 每一轮有pl的概率得到正面的牌,pd的概率得到负面的牌,1-pl-pd的概率得到无属性牌. 每一轮过后,都有p的概率结束游戏,1-p的概率开始下一轮. 问期望有多少轮后正面的牌数严格大于负 ...
- bzoj 1010,1011
上次应某位同学的要求先把代码给贴上了,今天还是细细讲讲比较好 bzoj 1010: dp+斜率优化 首先dp的思路并不是太难想出来,直接给方程:f[i] = min{f[j-1] + (sum[i]- ...
- 自定义alert 确定、取消功能
以删除为例,首先新建html <table border="1" cellpadding="0" cellspacing="0" id ...
- splay 模板 洛谷3369
题目描述 您需要写一种数据结构(可参考题目标题),来维护一些数,其中需要提供以下操作: 插入 xx 数 删除 xx 数(若有多个相同的数,因只删除一个) 查询 xx 数的排名(排名定义为比当前数小的数 ...
- NX二次开发-UFUN相加布尔操作,可保留或删除目标体,工具体UF_MODL_unite_bodies_with_retained_options
NX11+VS2013 #include <uf.h> #include <uf_modl.h> UF_initialize(); //创建块 UF_FEATURE_SIGN ...
- maven+scala+idea 环境构建
组建信息 组件 版本 下载地址 maven 3.6.1 https://maven.apache.org/ jdk jdk1.8.0 https://www.oracle.com/technetwor ...
- JQuery validate验证规则
//定义中文消息 var cnmsg = { required: “必选字段”, remote: “请修正该字段”, email: “请输入正确格式的电子邮件”, url: “请输入合法的网址”, d ...
- iOS进阶二-KVC
概述 KVC的全程是Key-Value Coding, 俗称"键值编码",可以通过一个key来访问属性 常见的AP有 - (void)setValue:(nullable id)v ...