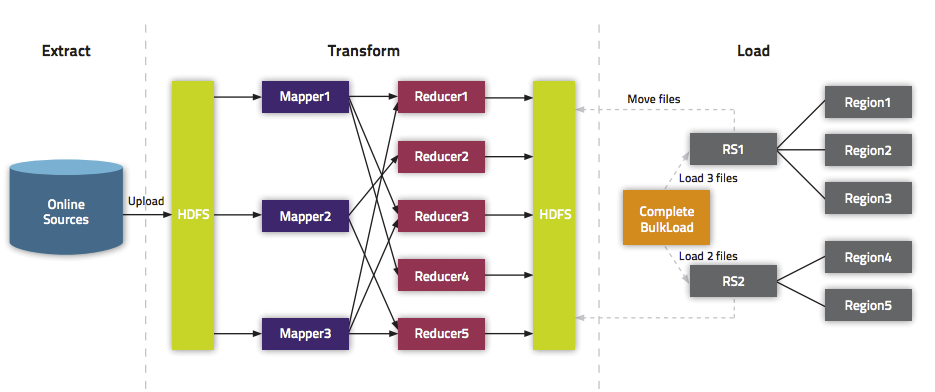
通过BlukLoad的方式快速导入海量数据
http://www.cnblogs.com/MOBIN/p/5559575.html
摘要


|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public class GenerateHFile extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put>{ protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] items = line.split("\t"); String ROWKEY = items[1] + items[2] + items[3]; ImmutableBytesWritable rowkey = new ImmutableBytesWritable(ROWKEY.getBytes()); Put put = new Put(ROWKEY.getBytes()); //ROWKEY put.addColumn("INFO".getBytes(), "URL".getBytes(), items[0].getBytes()); put.addColumn("INFO".getBytes(), "SP".getBytes(), items[1].getBytes()); //出发点 put.addColumn("INFO".getBytes(), "EP".getBytes(), items[2].getBytes()); //目的地 put.addColumn("INFO".getBytes(), "ST".getBytes(), items[3].getBytes()); //出发时间 put.addColumn("INFO".getBytes(), "PRICE".getBytes(), Bytes.toBytes(Integer.valueOf(items[4]))); //价格 put.addColumn("INFO".getBytes(), "TRAFFIC".getBytes(), items[5].getBytes());//交通方式 put.addColumn("INFO".getBytes(), "HOTEL".getBytes(), items[6].getBytes()); //酒店 context.write(rowkey, put); }} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public class GenerateHFileMain { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { final String INPUT_PATH= "hdfs://master:9000/INFO/Input"; final String OUTPUT_PATH= "hdfs://master:9000/HFILE/Output"; Configuration conf = HBaseConfiguration.create(); HTable table = new HTable(conf,"TRAVEL"); Job job=Job.getInstance(conf); job.getConfiguration().set("mapred.jar", "/home/hadoop/TravelProject/out/artifacts/Travel/Travel.jar"); //预先将程序打包再将jar分发到集群上 job.setJarByClass(GenerateHFileMain.class); job.setMapperClass(GenerateHFile.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); job.setOutputFormatClass(HFileOutputFormat2.class); HFileOutputFormat2.configureIncrementalLoad(job,table,table.getRegionLocator()); FileInputFormat.addInputPath(job,new Path(INPUT_PATH)); FileOutputFormat.setOutputPath(job,new Path(OUTPUT_PATH)); System.exit(job.waitForCompletion(true)?0:1); }} |
|
1
2
3
4
5
6
7
8
|
public class LoadIncrementalHFileToHBase { public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(configuration); LoadIncrementalHFiles loder = new LoadIncrementalHFiles(configuration); loder.doBulkLoad(new Path("hdfs://master:9000/HFILE/OutPut"),new HTable(conf,"TRAVEL")); }} |
通过BlukLoad的方式快速导入海量数据的更多相关文章
- 通过BulkLoad的方式快速导入海量数据
摘要 加载数据到HBase的方式有多种,通过HBase API导入或命令行导入或使用第三方(如sqoop)来导入或使用MR来批量导入(耗费磁盘I/O,容易在导入的过程使节点宕机),但是这些方式不是慢就 ...
- 通过BulkLoad快速将海量数据导入到Hbase
在第一次建立Hbase表的时候,我们可能需要往里面一次性导入大量的初始化数据.我们很自然地想到将数据一条条插入到Hbase中,或者通过MR方式等. 但是这些方式不是慢就是在导入的过程的占用Region ...
- 在Spark上通过BulkLoad快速将海量数据导入到Hbase
我们在<通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]>文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入 ...
- mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式)
mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式) 首先将要导入的数据文件top5000W.txt放入到数据库数据目录/var/local/mysql/data/${d ...
- MySQL 快速导入大量数据 资料收集
一.LOAD DATA INFILE http://dev.mysql.com/doc/refman/5.5/en/load-data.html 二. 当数据量较大时,如上百万甚至上千万记录时,向My ...
- 在Ubuntu上使用离线方式快速安装K8S v1.11.1
在Ubuntu上使用离线方式快速安装K8S v1.11.1 0.安装包文件下载 https://pan.baidu.com/s/1nmC94Uh-lIl0slLFeA1-qw v1.11.1 文件大小 ...
- 8、组件注册-@Import-给容器中快速导入一个组件
8.组件注册-@Import-给容器中快速导入一个组件 8.1 给容器中注册组建的方式 包扫描+组建标注注解(@Controller.@Service.@Repository.@Component)[ ...
- Mysql百万数据量级数据快速导入Redis
前言 随着系统的运行,数据量变得越来越大,单纯的将数据存储在mysql中,已然不能满足查询要求了,此时我们引入Redis作为查询的缓存层,将业务中的热数据保存到Redis,扩展传统关系型数据库的服务能 ...
- 【Spring注解驱动开发】使用@Import注解给容器中快速导入一个组件
写在前面 我们可以将一些bean组件交由Spring管理,并且Spring支持单实例bean和多实例bean.我们自己写的类,可以通过包扫描+标注注解(@Controller.@Servcie.@Re ...
随机推荐
- js文件操作之——导出Excel (js-xlsx)
前阵子跟server同学讨论一个Excel导出的需求,我说JS搞不定,需要server来做,被server同学强行打脸. 今天研究了下,尼玛,不光可以,还很强大了! 总结:经验是害人的,尤其是在发展迅 ...
- shell常用命令及正则辅助日志分析统计
https://www.cnblogs.com/wj033/p/3451618.html 正则日志分析统计 3 grep 'onerror' v3-0621.log | egrep -v '(\d ...
- File、FileFilter、递归初步
java.io.File 文件和目录 路径名的抽象表示形式 文件:File 存储数据的 目录:Directory 文件夹 用来存储文件 路径:Path 定位具有平台无关性 在任意平台都可以使用 Fil ...
- POJ 1269 /// 判断两条直线的位置关系
题目大意: t个测试用例 每次给出一对直线的两点 判断直线的相对关系 平行输出NODE 重合输出LINE 相交输出POINT和交点坐标 1.直线平行 两向量叉积为0 2.求两直线ab与cd交点 设直线 ...
- vue+h-ui+layUI完成列表页及编辑页
最近做一个新项目,用H-ui做后台, 比较喜欢他的模仿bootsharp的栅格和表单样式. 感觉不好的是iframe加载速度比较慢. 这里在原有的H-ui页面基础上加入用vue来绑数据,用的还可以. ...
- Python全栈开发:初识Python
Pythton简介 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语 ...
- html--双飞翼布局
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- uoj60 怎样提高智商
题意:你需要构造n个四项选择题.格式为:问在前i个问题中选了几个hi字母? 输出有最多正确答案的构造方案. 标程: #include<cstdio> using namespace std ...
- php7 mysql_pconnect() 缺失 解决方法
php7 兼容 MySQL 相关函数 PHP7 废除了 ”mysql.dll” ,推荐使用 mysqli 或者 pdo_mysql http://PHP.net/manual/zh/mysqlinfo ...
- 【五校联考5day1】登山
题目 描述 题目大意 给你一个n∗nn*nn∗n的网格图.从(0,0)(0,0)(0,0)开始,每次只可以向右或向上移动一格,并且不能越过对角线(即不能为x<yx<yx<y). 网格 ...