Spark应用开发调优要点总结
调试Spark应用性能的时候,首先应该理解spark是如何工作以及你的spark应用需要何种类型的资源。比如说,机器学习相关的spark应用更依赖cpu计算能力,ETL应用更依赖I/O能力,以此进行有针对的优化和配置。
硬件配置
正确的硬件配置要根据实际的情况来看。可以从以下几个方面来考虑:
- 存储系统 由于Spark作业一般都需要从外部存储系统里面读入数据,所以一个重要的原则就是就近计算。直接在HDFS的集群上运行Spark应用,并将Spark应用提交给YARN。实在不行的话,也要保持和HDFS集群在同一个局域网内。对于目标数据存储在HBase这样的低延迟介质中,那么为了避免干扰,最好在不同于HBase集群的节点上进行Spark计算。
- 本地磁盘 虽然Spark可以在内存中执行大量计算,但它仍然使用本地磁盘来存储不适合RAM的数据,并且会保留计算阶段间的中间数据。所以我们建议每个节点4-8个硬盘,不需要组RAID。在Linux操作系统中,以noatiome的选项挂载这些磁盘,同时把这些磁盘目录配置到spark.local.dir属性(和HDFS集群相同)
- 内存 Spark应用运行的每台机器的最低内存要求是8GB,当然越高越好。另外,建议最多将每台机器总内存的75%分配给Spark应用,剩余部分留给系统操作和缓存区缓存。每个Spark应用会消耗不同的内存,为了准确知道一个应用需要多少内存,可以加载一部分数据到Spark RDD中,然后在Spark的监控页面中页面
http: //<driver-node>:4040查看内存大小。 - 网络 当数据在内存当中的时候,很多Spark应用都是和网络绑定,所以保证一个至少10GB带宽的网络是很有必要的。同样,可以在Spark的监控页
http: //<driver-node>:4040中查看有多少数据通过网络来进行Spark shuffle的操作。 - Cpu核心 至少保证每台机器8-16个核心,根据应用的情况,适当增加cpu核心。
submit 参数详解
Executor的内存分为3块:
第一块:用于task执行代码,默认占executor总内存的20%
第二块:task通过shuffle过程拉取上一个stage的task的输出后,进行聚合等操作时使用,默认也是占20%
第三块:让RDD持久化时使用,默认占executor总内存的60%
Task的执行速度和每个executor进程的CPU Core数量有直接关系,一个CPU Core同一时间只能执行一个线程,每个executor进程上分配到的多个task,都是以task一条线程的方式,多线程并发运行的。如果CPU Core数量比较充足,而且分配到的task数量比较合理,那么可以比较快速和高效地执行完这些task线程。具体参数如下:
- num-executors:该作业总共需要多少executor进程执行,每个作业运行一般设置5-~100个左右较合适。
- executor-memory:设置每个executor进程的内存,设置4G~8G较合适。 num-executors* num-executors代表作业申请的总内存量(尽量不要超过最大总内存的1/3~1/2)
- executor-cores:每个executor进程的CPU Core数量,该参数决定每个
executor进程并行执行task线程的能力,设置2~4个较合适。num-executors* executor-cores代表作业申请总CPU core数(不要超过总CPU Core的 1/3~1/2 ) - driver-memory:设置Driver进程的内存。通常不用设置,一般1G就够了,若出现使用collect算子将RDD数据全部拉取到Driver上处理,就必须确保该值足够大,否则OOM内存溢出。
- spark.default.parallelism:每个stage的默认task数量。设置500~1000较合适,默认一个HDFS的block对应一个task,Spark默认值偏少,这样导致不能充分利用资源
- spark.storage.memoryFraction:设置RDD持久化数据在executor内存中能占的比例,默认0.6,即默认executor 60%的内存可以保存持久化RDD数据。若有较多的持久化操作,可以设置高些,超出内存的会频繁gc导致运行缓慢
- spark.shuffle.memoryFraction:聚合操作占executor内存的比例,默认0.2。若持久化操作较少,但shuffle较多时,可以降低持久化内存占比,提高shuffle操作内存占比。
应用代码编写原则
- 避免创建重复的RDD。对同一份数据,只应该创建一个RDD,不能创建多个RDD来代表同一份数据,极大浪费内存。
- 尽可能复用同一个RDD。比如:一个RDD数据格式是key-value,另一个是单独value类型,这两个RDD的value部分完全一样,这样可以复用RDD达到减少算子执行的次数。
- 对多次使用的RDD进行持久化处理。每次对一个RDD执行一个算子操作时,都会重新从源头处理计算一遍,计算出那个RDD出来,然后进一步操作,这种方式性能很差。对多次使用的RDD进行持久化,借助cache()和persist()方法将RDD的数据保存在内存或磁盘中,避免重复劳动。
- persist持久化级别

- 避免使用shuffle类算子。在spark作业运行过程中,最消耗性能的地方就是shuffle过程。将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合和join处理,比如groupByKey、reduceByKey、join等算子,都会触发shuffle。
- 使用map-side预聚合的shuffle操作。一定要使用shuffle的,无法用map类算子替代的,那么尽量使用map-site预聚合的算子。类似MapReduce中的Combiner。可能的情况下使用reduceByKey或aggregateByKey算子替代groupByKey算子,因为reduceByKey或aggregateByKey算子会使用用户自定义的函数对每个节点本地相同的key进行预聚合,而groupByKey算子不会预聚合。
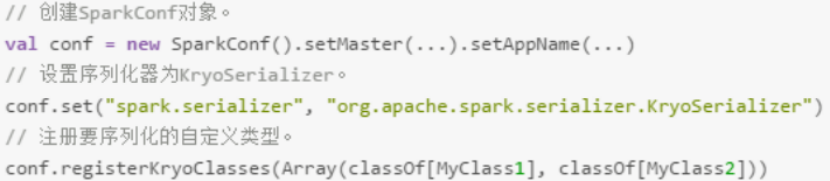
- 使用Kryo优化序列化性能。Kryo是一个序列化类库,来优化序列化和反序列化性能。Spark默认使用Java序列化机制(ObjectOutputStream/ ObjectInputStream API)进行序列化和反序列化。Spark支持使用Kryo序列化库,性能比Java序列化库高很多,10倍左右。
查看应用状态信息
如果某个应用很长时间没有结束,我们可以通过yarn命令来获取更多的信息。使用yarn application –list 命令可以列出所有的应用及应用id。另外可以在应用代码中对RDD使用toDebugString()来查看RDD的详细信息以及依赖关系。也可以对DataFrame使用explain()方法查看查询计划信息。
作业完成后从spark 历史服务器web页面或者yarn的web页面来查看spark作业的历史信息。也可以使用命令行查看yarn logs -applicationId 。
从这些信息中或许能观察到某些优化线索。
Spark应用开发调优要点总结的更多相关文章
- Spark面试题(七)——Spark程序开发调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- Spark(六)Spark之开发调优以及资源调优
Spark调优主要分为开发调优.资源调优.数据倾斜调优.shuffle调优几个部分.开发调优和资源调优是所有Spark作业都需要注意和遵循的一些基本原则,是高性能Spark作业的基础:数据倾斜调优,主 ...
- [Spark性能调优] 第一章:性能调优的本质、Spark资源使用原理和调优要点分析
本課主題 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- spark 性能调优(一) 性能调优的本质、spark资源使用原理、调优要点分析
转载:http://www.cnblogs.com/jcchoiling/p/6440709.html 一.大数据性能调优的本质 编程的时候发现一个惊人的规律,软件是不存在的!所有编程高手级别的人无论 ...
- 性能调优的本质、Spark资源使用原理和调优要点分析
本课主题 大数据性能调优的本质 Spark 性能调优要点分析 Spark 资源使用原理流程 Spark 资源调优最佳实战 Spark 更高性能的算子 引言 我们谈大数据性能调优,到底在谈什么,它的本质 ...
- Spark性能优化--开发调优与资源调优
参考: https://tech.meituan.com/spark-tuning-basic.html https://zhuanlan.zhihu.com/p/22024169 一.开发调优 1. ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- Spark学习之路 (八)SparkCore的调优之开发调优[转]
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- QEMU和KVM的关系
首先KVM(Kernel Virtual Machine)是Linux的一个内核驱动模块,它能够让Linux主机成为一个Hypervisor(虚拟机监控器).在支持VMX(Virtual Machin ...
- python3操作MySQL的模块pymysql
本文介绍Python3连接MySQL的第三方库--PyMySQL的基本使用. PyMySQL介绍 PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中 ...
- mysql--->MySQL错误日志
MySQL错误日志 简介 MySQL错误日志是记录MySQL 运行过程中较为严重的警告和错误信息,以及MySQL每次启动和关闭的详细信息.错误日志的命名通常为hostname.err.其中,hostn ...
- Git详解之分布式应用
前言 为了便于项目中的所有开发者分享代码,我们准备好了一台服务器存放远程 Git 仓库.经过前面几章的学习,我们已经学会了一些基本的本地工作流程中所需用到的命令.接下来,我们要学习下如何利用 Git ...
- tomcat 持久区溢出
知识点:堆内存设置(JVM堆内存)java的堆内存分为两块:permantspace(持久带) 和 heap spaceOOM1.年老代溢出,表现为:java.lang.OutOfMemoryErro ...
- keywords in my life
在脑子里出现的灵光一现的话语总是美好的: 1.当你试图站在人的发展,历史的发展的角度上看待问题,会发现我们身上所发生的任何事情都是必然的. 2.永远不要以好人的身份去看待和分析一件事情. 3.历史悲剧 ...
- web通信类几个相关知识
1.什么是同源策略及限制? 同源策略限制从一个源加载的文档或者脚本如何与来自另一个源的资源进行交互. 这是一个用于隔离潜在恶意文件的关键安全机制. 所谓同源,就是指两个页面具有相同的协议,主机(也常说 ...
- Simscape Multibody 教程 —— 入门学习
写在前面 本文要点: Simscape Multibody 简介 Simscape Multibody 入门学习的推荐学习材料和学习顺序 建模仿真过程中的重要知识 模型的参数设置(Model Work ...
- 在form子句中使用子查询时的注意事项
今天中午为了弄清这个问题,本人真的是头都搞大了!最后明白了一点,在from子句中使用子查询是,一定要将临时表的别名带上,否则会灰常痛苦!!!
- 工业狗转行AI的心路历程
2020年2月16日,晴 昨晚下了一场雪,大概是晚上八九点的样子,细碎的雪花在无风的夜里直嗖嗖的往下掉,门前的轿车顶上覆了薄薄的一层.路灯下的小巷格外的寂静,裹着我的睡衣在昏黄的灯光下站了许久,冠状病 ...