Google earth爬取卫星影像数据并进行标注路网的方法
一、下载goole earth 和GetScreen:
试了很多,找了可以使用的上传到百度网盘,链接如下所示:
链接:https://pan.baidu.com/s/1fp-W8u68iRsJ0xcu-pJWhg
提取码:zrsw
使用方法:
1、首先打开Google earth,并将球锁定到要截取影像的位置
2、打开GetScreen插件,定位到要截取的区域,选择“两点定位”;
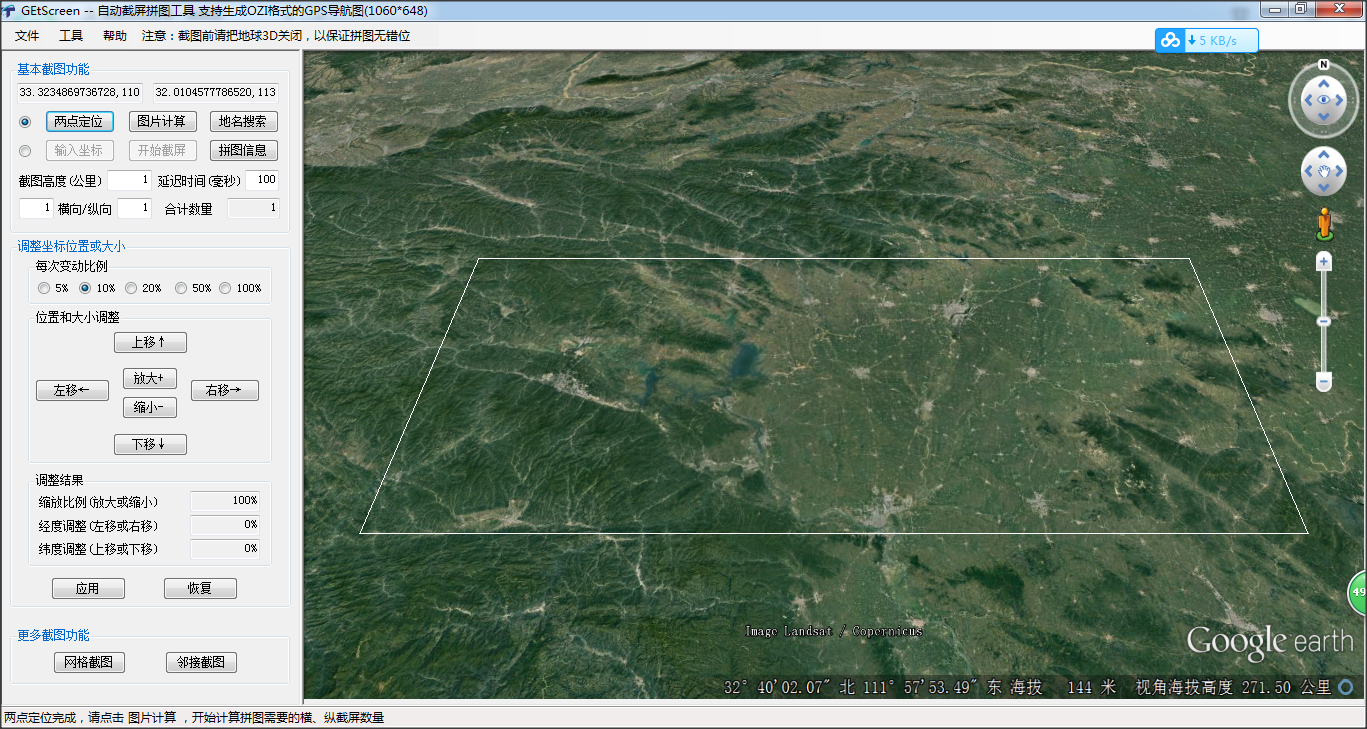
3、在右侧的影像中右键单击,输入两点(两点连成的直线是框选区域的对角线)
4、点击“图片计算”,待计算完成后,进行下一步操作;
5、点击“开始截图”,会截取选中的区域,在截图过程中,保持GetScreen不变,也不要进行其他任何操作。
6、点击“拼图信息”,可查看截取的影像图片
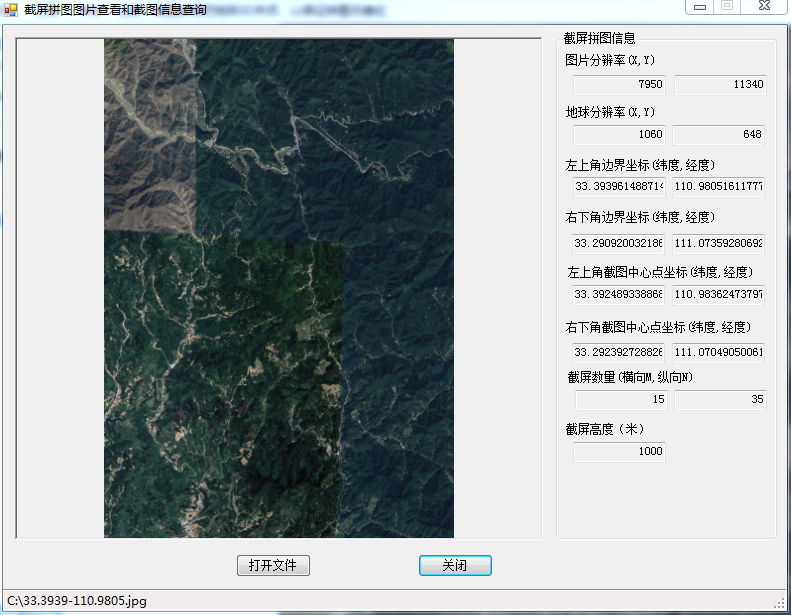
7、根据上图中的拼图信息,可以给截取的图片添加位置信息:
参考:https://blog.csdn.net/llw01/article/details/8918514
假设:左上角坐标(minX,maxY),右上角坐标(maxX,maxY),右下角坐标(maxX,minY),左下角坐标(minX,minY)
步骤:
(1)在放图片的目录下新建TXT文本文档,将文件名改为与图片相同,扩展名改为jgw(JPG图片),(TIF要改为tfw)。
(2)用记事本打开扩展名为*.jgw或*.tfw的文件,在其中输入下列五行数字:
A=X方向上的象素分辨率
D=旋转系统
B=旋转系统
E=Y方向上的象素分辨素
C=栅格地图左上角象素中心X坐标
F=栅格地图左上角象素中心Y坐标
其中:A=(maxX – minX)/numX;D、B一般默认为0;E=(minY – maxY)/numY;C=minX;F=maxY;注意X指经度,y指纬度
(3)最终jgw或tfw文件如下:
-0.0000082078209126102292
0
0
0.0000129611895
110.9805161177790
33.3939614887145
用ArcGIS加载图片,该图片就具有了地理坐标。
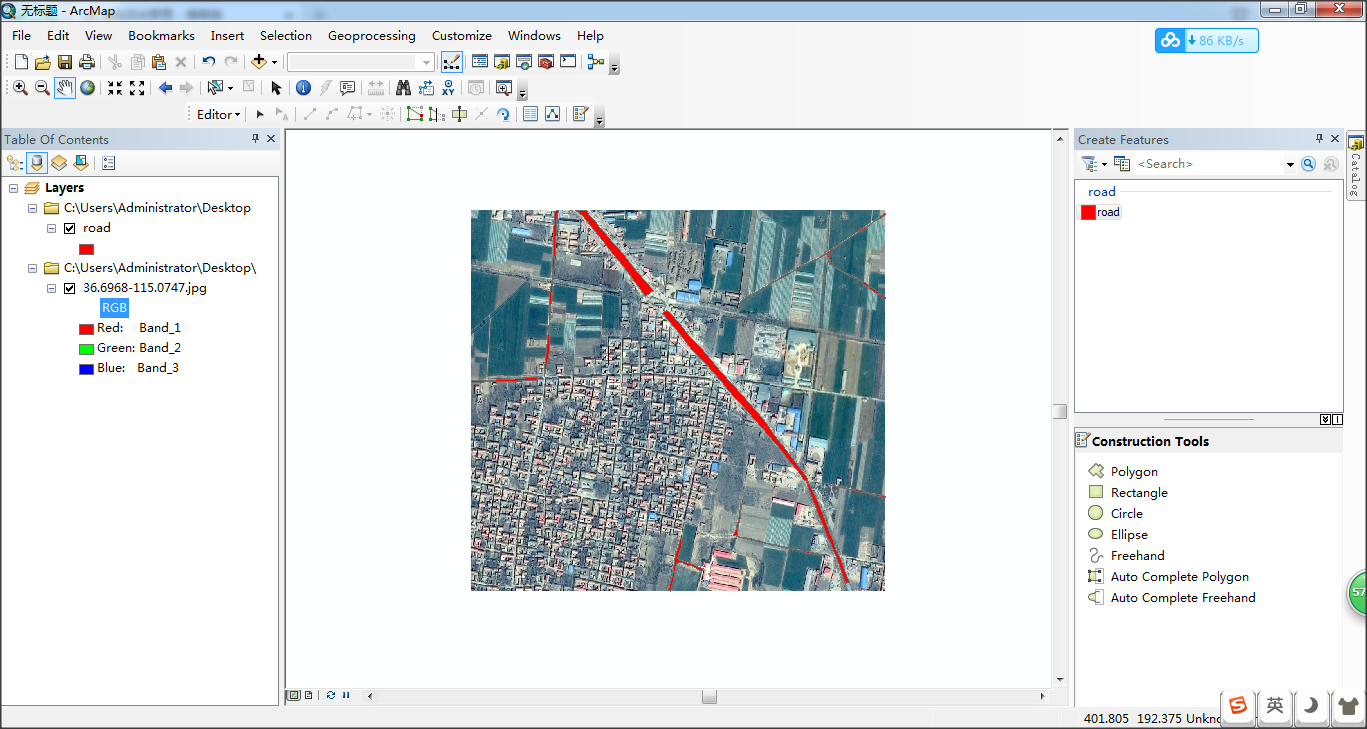
二、在arcmap中绘制路网,制作路网提取的样本
参考:https://blog.csdn.net/DoctorCuiLab/article/details/83060095
Google earth爬取卫星影像数据并进行标注路网的方法的更多相关文章
- xpath爬取网页评论,网址的的调用方法,数据库特殊字符的替换
# -*- coding:utf-8-*-from lxml import etreeimport urllibimport jsonimport requestsimport MySQLdbid=0 ...
- Google Earth数据存储、管理、表现及开发机制
Google Earth数据存储.管理.表现及开发机制 一. Google Earth(Map)介绍 1.1 Google Earth介绍 在众多的地理信息服务提供商中,Google是较早 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- Scrapy Learning笔记(四)- Scrapy双向爬取
摘要:介绍了使用Scrapy进行双向爬取(对付分类信息网站)的方法. 所谓的双向爬取是指以下这种情况,我要对某个生活分类信息的网站进行数据爬取,譬如要爬取租房信息栏目,我在该栏目的索引页看到如下页面, ...
- 用WebCollector制作一个爬取《知乎》并进行问题精准抽取的爬虫(JAVA)
简单介绍: WebCollector是一个无须配置.便于二次开发的JAVA爬虫框架(内核),它提供精简的的API.仅仅需少量代码就可以实现一个功能强大的爬虫. 怎样将WebCollector导入项目请 ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Crawlspider的自动爬取
引子 : 如果想要爬取 糗事百科 的全栈数据的方法 ? 方法一 : 基于scrapy框架中的scrapy的递归爬取进行实现(requests模块递归回调parse方法) . 方法二 : 基于Crawl ...
- scrapy(2)——scrapy爬取新浪微博(单机版)
Sina爬虫教程 Scrapy环境搭建 环境:window10 + python2.7(包含scrapy)+ mongoDB 1.1 安装集成了python2.7的anaconda ana ...
随机推荐
- SPSS实例教程:多重线性回归,你用对了么
SPSS实例教程:多重线性回归,你用对了么 在实际的医学研究中,一个生理指标或疾病指标往往受到多种因素的共同作用和影响,当研究的因变量为连续变量时,我们通常在统计分析过程中引入多重线性回归模型,来分析 ...
- java基础之静态代码块,局部代码块,构造代码块区别。
java中有几种常见的代码块,那怎样区别他们呢? 这里就这些问题,浅谈下我个人的理解. 1.局部代码块 局部代码块,又叫普通代码块.它是作用在方法中的代码块.例如: public void show( ...
- [转]【全面解禁!真正的Expression Blend实战开发技巧】第八章 FluidMoveBehavior完全解析之一漂浮移动
好久没更新博客了,今天如果没急事,准备连发三篇,完全讲解Blend最牛的元素-“FluidMoveBehavior”.我向大家保证这三章一定非常精彩,不看你肯定后悔.我相信这三篇文章发表后,国内很多s ...
- Joomla - akeeba backup(joomla网站备份、迁移扩展)
在所有 joomla 的网站中,如果只允许安装一个扩展,估计超过90%的人都会选择 akeeba backup,这基本是每个joomla都必备的一个扩展: akeeba backup 的更多资料可以到 ...
- angularjs中动态为audio绑定src问题总结
先上代码 <div class="block_area block_audio" ng-show="model.url"> <audio co ...
- maven项目mapper文件加载不到classpath问题解决方案
在调试我的maven项目的过程种,当我执行maven install时总提示找不到mapper.xml文件,看了一下大家的说法,都说是maven没有把src/main/java下的mapper包记载到 ...
- [Day6] Nginx 进阶模块
一. 使用变量防盗链referer模块 功能:通过验证referer请求头是否合法,来拒绝非正常的网站访问我们站点的资源 思路:通过referer模块,用invaild_refereri变量根据配置判 ...
- 逻辑备份(mysqldump/select into outfile)
#mysqldump备份 shell> mysqldump -uroot -p -P4306 sakila actor>E:\sakila-actor.sql shell> mysq ...
- Merge array and hash in ruby if key appears in array
I have two arrays one = [1,2,3,4,5,6,7] and two = [{1=>'10'},{3=>'22'},{7=>'40'}] Two will ...
- numpy.flatnonzero():
numpy.flatnonzero(): 该函数输入一个矩阵,返回扁平化后矩阵中非零元素的位置(index) 这是官方文档给出的用法,非常正规,输入一个矩阵,返回了其中非零元素的位置. 1 >& ...