Google earth爬取卫星影像数据并进行标注路网的方法
一、下载goole earth 和GetScreen:
试了很多,找了可以使用的上传到百度网盘,链接如下所示:
链接:https://pan.baidu.com/s/1fp-W8u68iRsJ0xcu-pJWhg
提取码:zrsw
使用方法:
1、首先打开Google earth,并将球锁定到要截取影像的位置
2、打开GetScreen插件,定位到要截取的区域,选择“两点定位”;
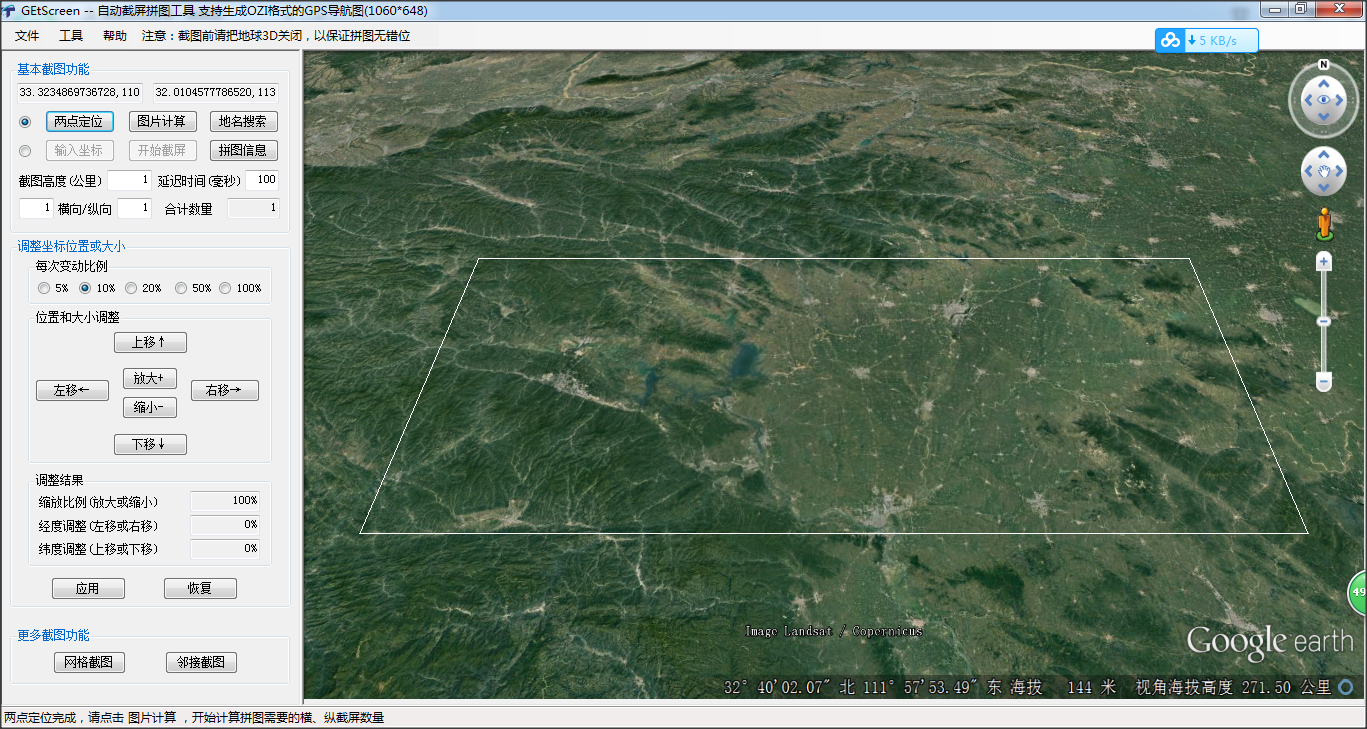
3、在右侧的影像中右键单击,输入两点(两点连成的直线是框选区域的对角线)
4、点击“图片计算”,待计算完成后,进行下一步操作;
5、点击“开始截图”,会截取选中的区域,在截图过程中,保持GetScreen不变,也不要进行其他任何操作。
6、点击“拼图信息”,可查看截取的影像图片
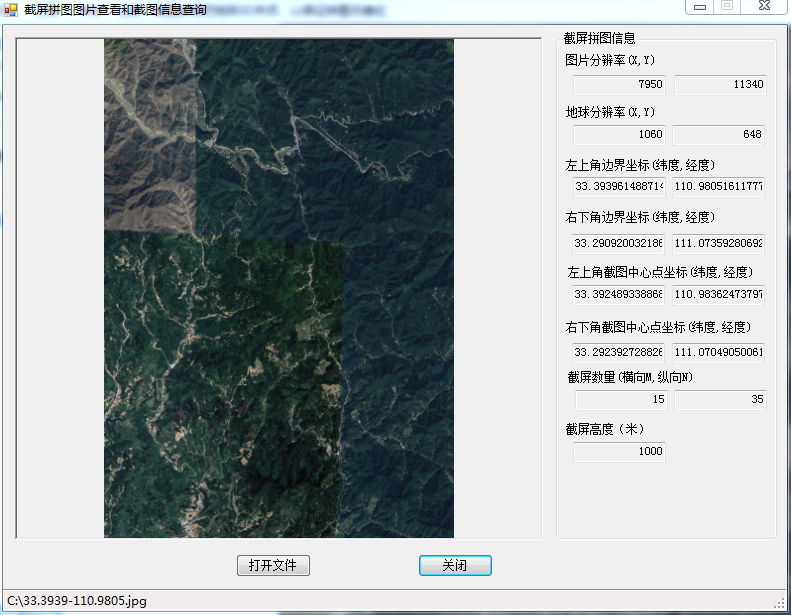
7、根据上图中的拼图信息,可以给截取的图片添加位置信息:
参考:https://blog.csdn.net/llw01/article/details/8918514
假设:左上角坐标(minX,maxY),右上角坐标(maxX,maxY),右下角坐标(maxX,minY),左下角坐标(minX,minY)
步骤:
(1)在放图片的目录下新建TXT文本文档,将文件名改为与图片相同,扩展名改为jgw(JPG图片),(TIF要改为tfw)。
(2)用记事本打开扩展名为*.jgw或*.tfw的文件,在其中输入下列五行数字:
A=X方向上的象素分辨率
D=旋转系统
B=旋转系统
E=Y方向上的象素分辨素
C=栅格地图左上角象素中心X坐标
F=栅格地图左上角象素中心Y坐标
其中:A=(maxX – minX)/numX;D、B一般默认为0;E=(minY – maxY)/numY;C=minX;F=maxY;注意X指经度,y指纬度
(3)最终jgw或tfw文件如下:
-0.0000082078209126102292
0
0
0.0000129611895
110.9805161177790
33.3939614887145
用ArcGIS加载图片,该图片就具有了地理坐标。
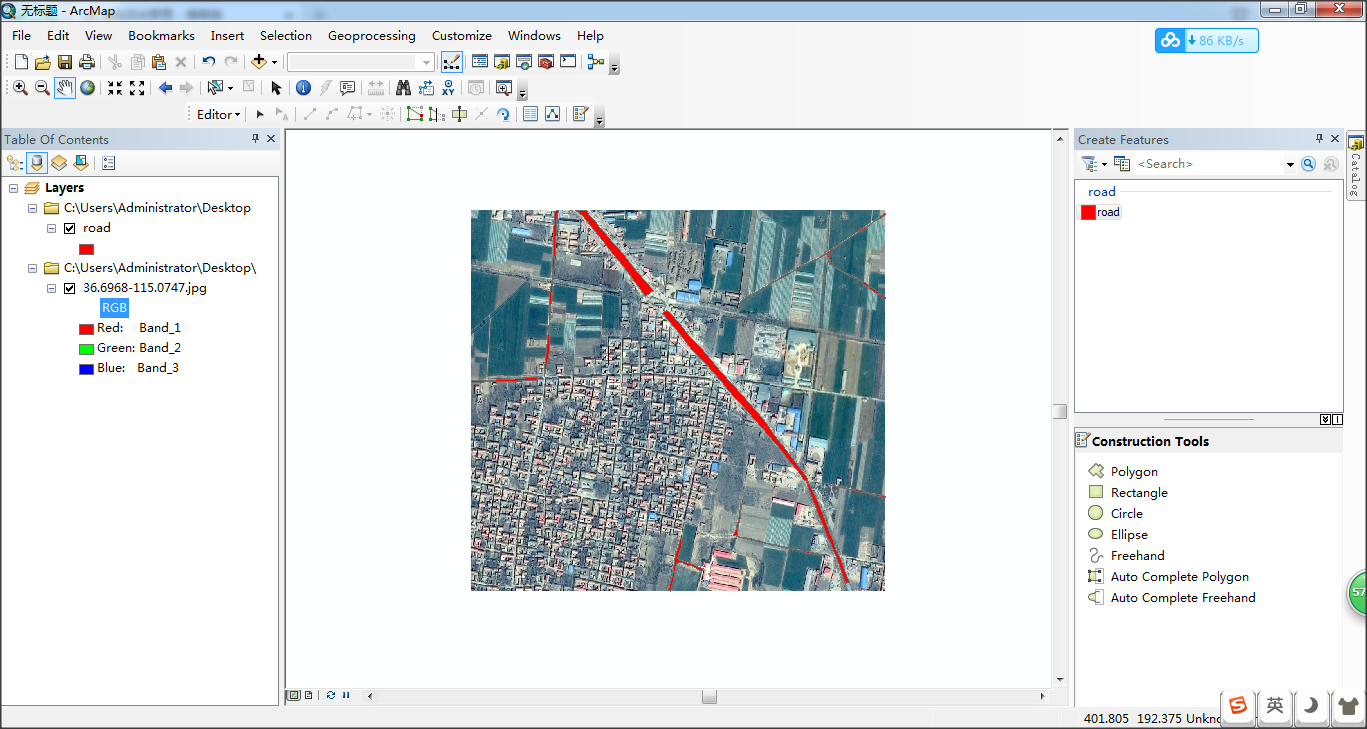
二、在arcmap中绘制路网,制作路网提取的样本
参考:https://blog.csdn.net/DoctorCuiLab/article/details/83060095
Google earth爬取卫星影像数据并进行标注路网的方法的更多相关文章
- xpath爬取网页评论,网址的的调用方法,数据库特殊字符的替换
# -*- coding:utf-8-*-from lxml import etreeimport urllibimport jsonimport requestsimport MySQLdbid=0 ...
- Google Earth数据存储、管理、表现及开发机制
Google Earth数据存储.管理.表现及开发机制 一. Google Earth(Map)介绍 1.1 Google Earth介绍 在众多的地理信息服务提供商中,Google是较早 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- Scrapy Learning笔记(四)- Scrapy双向爬取
摘要:介绍了使用Scrapy进行双向爬取(对付分类信息网站)的方法. 所谓的双向爬取是指以下这种情况,我要对某个生活分类信息的网站进行数据爬取,譬如要爬取租房信息栏目,我在该栏目的索引页看到如下页面, ...
- 用WebCollector制作一个爬取《知乎》并进行问题精准抽取的爬虫(JAVA)
简单介绍: WebCollector是一个无须配置.便于二次开发的JAVA爬虫框架(内核),它提供精简的的API.仅仅需少量代码就可以实现一个功能强大的爬虫. 怎样将WebCollector导入项目请 ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Crawlspider的自动爬取
引子 : 如果想要爬取 糗事百科 的全栈数据的方法 ? 方法一 : 基于scrapy框架中的scrapy的递归爬取进行实现(requests模块递归回调parse方法) . 方法二 : 基于Crawl ...
- scrapy(2)——scrapy爬取新浪微博(单机版)
Sina爬虫教程 Scrapy环境搭建 环境:window10 + python2.7(包含scrapy)+ mongoDB 1.1 安装集成了python2.7的anaconda ana ...
随机推荐
- iOS之String动态书写
/** String动画书写出来 @param string 要写的字 @param view 父视图 @param ui_font 字体大小 @param color 字体颜色 */ - (void ...
- 软件工程(C编码实践篇)学习总结
吴磊 SA17225400 学习完了孟老师的软件工程(C编码实践篇),跟着老师一步步的完成了代码的编写,收获真的很大. 在学习这门课之前,我还不会用Linux,也没接触过Git.如今我已成能够在Lin ...
- SpringBoot 04_热部署
热部署应用环境 IDEA2017.2 + MAVEN3.5 + SpringBoot1.5.6 热部署说明 1. devtools会监听classpath下的文件变动,并且会立即重启应用(发生在保存时 ...
- Delphi-DLL远程注入
1. 代码描述 枚举进程,然后向指定进程注入DLL 在被注入的进程窗口按下指定的键码值(#HOME),显示或者隐藏被注入的DLL窗口 未解决的问题: 卸载DLL DLL向exe发送消息 卸载键盘钩子 ...
- 从三层架构到Spring框架
首先是软件的应用分层架构 标准三层架构: 1:数据访问层:实现了数据的持久化 2:业务逻辑层:对逻辑的实现及处理,实际上不可能在表示层对数据不做任何处理,但是尽可能的将逻辑分为一层 3:表示层:数据的 ...
- python学习笔记4_数据清洗与准备
一.处理缺失值 pandas使用浮点值NaN(Not a Number)来显示缺失值,并将缺失值称为NA(not available(不可用)). NA常用处理方法: dropna:根据每个标签的值是 ...
- Jmeter接口测试(第二篇)
一.新建项目 1.运行Jmeter.bat打开Jmeter 2.添加线程组(测试计划->添加->Thread(users)->线程组) 3.添加HTTP请求(线程组->添加-& ...
- vue 可复用swiper以及scoped样式穿透(可以不受scoped的限制来修改样式)
参考: https://blog.csdn.net/dwb123456123456/article/details/82701740https://blog.csdn.net/u014027876/a ...
- 深入了解组件- -- 动态组件 & 异步组件
gitHub地址:https://github.com/huangpna/vue_learn/example里面的lesson11 一 在动态组件上使用keep-alive 在这之前我们已经有学习过用 ...
- Sublime text3 代码格式化插件vue
同事用的windows的sublime轻量级容易上手.我们现在强制eslint规范.我们就需要安装这个格式化代码的插件"html-css-js-prettify" 使用 Subli ...