win8下使用eclipse进行hadoop2.6.2开发
最近在win平台下使用eclipse Mars做在远程linux上的hadoop2.6开发,出现很多问题,让人心力交瘁,在经过不懈努力后,终于解决了,让人欢欣雀跃。
1、安装JDK
在做hadoop2.6最好使用jdk7版本的,下载后安装。
2、下载eclipse
去http://www.eclipse.org/downloads/ 下载你需要的版本,我们这里下载的是win64位版。直接解压到目录中。进行简单设置,根据你的开发需要,选择jdk的版本


3、安装Hadoop2.6.0-eclipse-plugin
去https://github.com/winghc/hadoop2x-eclipse-plugin,在下载zip包后,在release目录中,有hadoop-eclipse-plugin-2.6.0.jar可以直接使用,不用在行编译。如使用其他版本,请参考其他文档。直接将hadoop-eclipse-plugin-2.6.0.jar复制到eclipse的plugins目录中即可。
4、安装Hadoop windows插件
包括hadoop.dll、winutils.exe。下载地址:https://github.com/srccodes/hadoop-common-2.2.0-bin
下载解压后,还需要配置环境变量,HADOOP_HOME = 解压目录,Path后增加 %HADOOP_HOME%\bin;
5、在eclipse中设置hadoop开发插件
打开eclipse,设置好工作区域后,点击

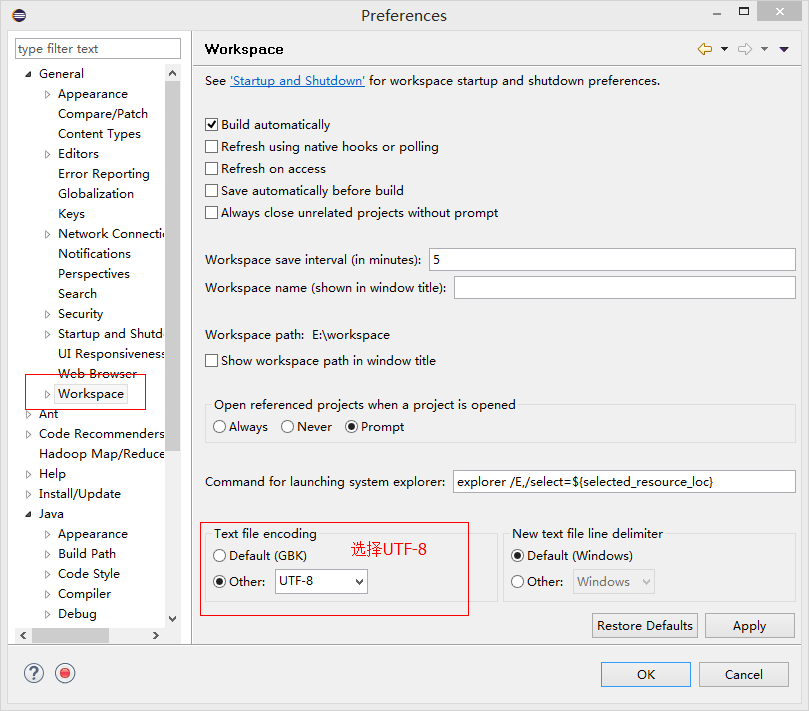
选择下图中红色标记,

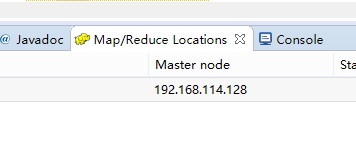
在eclipse的工作区间中,左上角和下方会出现图中标记,如果出现,则说明前几步你都正确了。接下来对插件进行设置
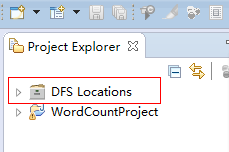
6、设置hadoop插件
在eclipse菜单中选择,window - preferences,打开设置菜单

这里所用的hadoop版本需要和你linux上安装的hadoop版本一致,开发的时候插件会在这个目录中获取需要的开发包。设置完成后保存。
注:需要用二进制包,不用修改配置文件


设置完成后,就可以在eclipse的右上角看到你的hadoop的目录结构了。
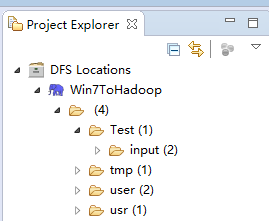
7、上面只是点毛毛雨,下面才真正开始重点了,如何进行开发,我们使用hadoop的wordcount来做测试。
创建mr项目
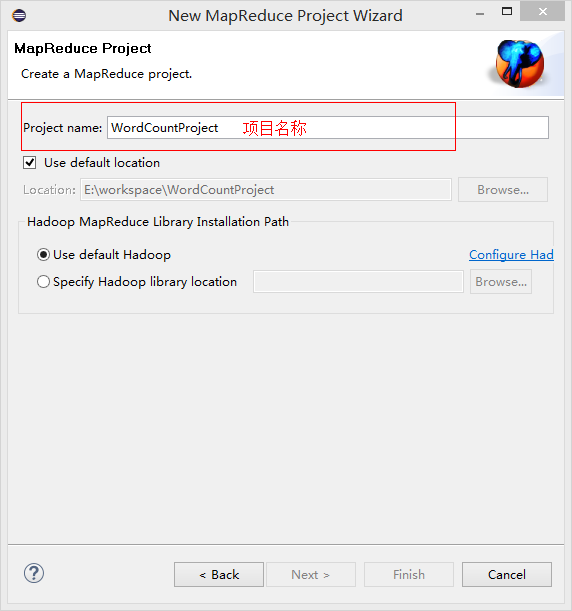
设置项目名称
创建类

设置类属性

创建完成后,将hadoop-2.6.2-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples目录下的WordCount.java文件内容,copy到刚创建的文件中。
8、接下来创建配置环境
在项目中,再创建一个Source Folder,名字叫resources,把你集群里的hadoop配置文件(etc/hadoop)拷贝到这个目录中,包括log4j.properties、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。这几个配置文件除log4j.properties外,其他的因个人需求不一样而不同,但必须包括以下内容。
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.114.128:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zkpk/hadoop_data/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.114.128:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zkpk/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/zkpk/hadoop_data/dfs/data</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>远程开发必须</description>
</property>
<property>
<name>mapred.remote.os</name>
<value>Linux</value>
<description>远程开发必须</description>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
<description>远程开发必须</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/zkpk/hadoop-2.6.2/etc/hadoop,
/home/zkpk/hadoop-2.6.2/share/hadoop/common/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/common/lib/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/hdfs/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/hdfs/lib/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/mapreduce/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/mapreduce/lib/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/yarn/*,
/home/zkpk/hadoop-2.6.2/share/hadoop/yarn/lib/*
</value>
<description>远程开发必须,制定远程目录上</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.114.128:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.114.128:19888</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>远程开发必须</description>
</property>
<property>
<name>mapred.job.tracker</name>
<value>192.168.114.128:9001</value>
<description>远程开发必须</description>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>远程开发必须</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.114.128:8032</value>
</property>
</configuration>
以上完成后,即完成开发环境配置,接下来试试运行是否成功。


完成后,直接点击运行即可

看结果,如下就恭喜你成功了
15/12/18 09:14:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/12/18 09:14:13 INFO client.RMProxy: Connecting to ResourceManager at /192.168.114.128:8032
15/12/18 09:14:14 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
15/12/18 09:14:14 INFO input.FileInputFormat: Total input paths to process : 2
15/12/18 09:14:14 INFO mapreduce.JobSubmitter: number of splits:2
15/12/18 09:14:14 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1450342418109_0004
15/12/18 09:14:14 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
15/12/18 09:14:14 INFO impl.YarnClientImpl: Submitted application application_1450342418109_0004
15/12/18 09:14:14 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1450342418109_0004/
15/12/18 09:14:14 INFO mapreduce.Job: Running job: job_1450342418109_0004
15/12/18 09:14:21 INFO mapreduce.Job: Job job_1450342418109_0004 running in uber mode : false
15/12/18 09:14:21 INFO mapreduce.Job: map 0% reduce 0%
15/12/18 09:14:31 INFO mapreduce.Job: map 100% reduce 0%
15/12/18 09:14:39 INFO mapreduce.Job: map 100% reduce 100%
15/12/18 09:14:40 INFO mapreduce.Job: Job job_1450342418109_0004 completed successfully
15/12/18 09:14:40 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=79
FILE: Number of bytes written=320590
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=268
HDFS: Number of bytes written=41
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=16220
Total time spent by all reduces in occupied slots (ms)=4519
Total time spent by all map tasks (ms)=16220
Total time spent by all reduce tasks (ms)=4519
Total vcore-seconds taken by all map tasks=16220
Total vcore-seconds taken by all reduce tasks=4519
Total megabyte-seconds taken by all map tasks=16609280
Total megabyte-seconds taken by all reduce tasks=4627456
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=82
Map output materialized bytes=85
Input split bytes=218
Combine input records=8
Combine output records=6
Reduce input groups=5
Reduce shuffle bytes=85
Reduce input records=6
Reduce output records=5
Spilled Records=12
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=385
CPU time spent (ms)=1660
Physical memory (bytes) snapshot=460673024
Virtual memory (bytes) snapshot=6179151872
Total committed heap usage (bytes)=259063808
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=50
File Output Format Counters
Bytes Written=41
错误解说:
1、WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
INFO mapreduce.Job: Task Id : attempt_1450852806248_0029_m_000000_0, Status : FAILED
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.mr.WordCount$TokenizerMapper not found
是由于没有jar上传到集群,所以mr的时候回出现找不到类的情况,需要再程序中增加以下语句
在mian函数的Configuration conf = new Configuration();后增加conf.set("mapred.jar", jar打包所在的地址);
例:conf.set("mapred.jar", "E:\\workspace\\WordCountTest\\bin\\org\\apache\\hadoop\\mr\\WordCountTest.jar");
win8下使用eclipse进行hadoop2.6.2开发的更多相关文章
- eclipse配置hadoop2.7.2开发环境并本地跑起来
先安装并启动hadoop,怎么弄见上文http://www.cnblogs.com/wuxun1997/p/6847950.html.这里说下怎么设置IDE来开发hadoop代码和调试.首先要确保你本 ...
- windows 下用eclipse搭建java、python开发环境
本人只针对小白!本文只针对小白!本文只针对小白! 最近闲来无事,加上之前虽没有做过eclipse上java.python的开发工作,但一直想尝试一下.于是边查找资料边试验,花了一天时间在自己的机器上用 ...
- 在Windows下用Eclipse+CDT+MinGW搭建C++开发平台
本文提供了在Windows下用Eclipse+CDT+MinGW搭建C / C++开发平台的方法, 测试平台为Windows XP Sp2 CHS. 以下软件均为Windows平台下的版本. 1. ...
- eclipse连hadoop2.x运行wordcount 转载
转载地址:http://my.oschina.net/cjun/blog/475576 一.新建java工程,并且导入hadoop相关jar包 此处可以直接创建mapreduce项目就可以,不用下面折 ...
- Windows 8.0上Eclipse 4.4.0 配置CentOS 6.5 上的Hadoop2.2.0开发环境
原文地址:http://www.linuxidc.com/Linux/2014-11/109200.htm 图文详解Windows 8.0上Eclipse 4.4.0 配置CentOS 6.5 上的H ...
- 从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码
从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码http://www.aboutyun.com/thread-8211-1-1.html(出处: about云开发) ...
- eclipse调试hadoop2.2.0源码笔记
在hadoop1.x版本时使用的是在Windows下编译Eclipse插件,远程调试集群.换成2.2.0,没有eclipse-plugin文件. hadoop2.2.0"远程调试集群&quo ...
- Windows下配置eclipse写WordCount
1 下载插件 hadoop-eclipse-plugin-2.7.2.jar github上下载源码后需要自己编译.这里使用已经编译好的插件即可 2 配置插件 把插件放到..\eclipse\plug ...
- 一次失败的尝试hdfs的java客户端编写(在linux下使用eclipse)
一次失败的尝试hdfs的java客户端编写(在linux下使用eclipse) 给centOS安装图形界面 GNOME桌面环境 https://blog.csdn.net/wh211212/artic ...
随机推荐
- EditText文本中用正则匹配是否包含数字,及判断文本只能是纯汉字或纯字母
遇到判断EditText中文本,是否为制定格式 EditText et; Button btn; @Override protected void onCreate(Bundle savedInsta ...
- JAVA内容回顾(一)——基本语法
一.基本数据类型 1.标识符. 标识符由字母.数字.下划线和美元符组成. 标识符不能是JAVA的关键字与保留字,但是可以包含其内. 标识符区分大小写.标识符长度没有限制.标识符不能含有空格. 2.注释 ...
- Python基础篇-day7
本节目录-面向对象1 类介绍1.1 面向对象oo特征1.2 类的特性1.3 创建与调用 1.3.1 基本结构 1.3.2 结构说明 1.3.3 对外部提供只读访问接口 1.3.4 析构方法2 继承2. ...
- Spark Streaming的wordcount案例
之前测试的一些spark案例都是采用离线处理,spark streaming的流处理一样可以运行经典的wordcount. 基本环境: spark-2.0.0 scala-2.11.0 IDEA-15 ...
- this的相关知识
一如既往,直接上代码: function fn(name,age){ var obj=new Object(); obj.name=name; obj.age=age; obj.talk=functi ...
- 为什么new的普通数组用delete 和 delete[]都能正确释放
由同事推荐的一篇博客: 为何new出的对象数组必须要用delete[]删除,而普通数组delete和delete[]都一样-------_CrtMemBlockHeader 文章解释了delete 内 ...
- sublime text3编译运行C,Java程序的一些配置
环境:linux 64位 桌面环境: gnome Java编译运行 (1)Preferences --> Browse Packages --> 在该文件夹下新建build文件如: Myj ...
- 第九十八节,JavaScript语法、关键保留字及变量
JavaScript语法.关键保留字及变量 学习要点: 1.语法构成 2.关键字保留字 3.变量 任何语言的核心都必然会描述这门语言最基本的工作原理.而JavaScript的语言核心就是ECMAScr ...
- Java中的DateFormatter
字母 日期或时间元素 表示 示例 G Era 标志符 Text AD y 年 Year 1996; 96 M 年中的月份 Month July; Jul;07 w 年中的周数 Number 27 W ...
- Ubuntu彻底删除mysql
删除 mysql sudo apt-get autoremove --purge mysql-server-5.0sudo apt-get remove mysql-serversudo apt-ge ...