Oracle分区索引
索引与表类似,也可以分区;
分区索引分为两类:
- Locally partitioned index(局部分区索引)
- Globally partitioned index(全局分区索引)
下面就来详细解析一下这两类索引。
一:Locally partitioned index(局部分区索引)
1. 概念:
局部分区索引随表对索引完成相应的分区(即索引会使用与底层表相同的机制分区),每个表分区都有一个索引分区,并且只索引该表分区。
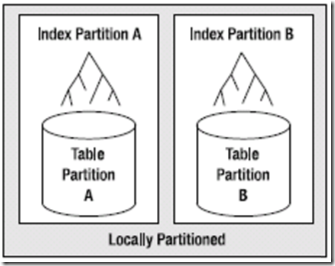
如图,若一个表被划分为AB两个分区,则局部分区索引A就只索引A分区中的数据,局部分区索引B只索引B分区中的数据;
2. 分类:
局部分区索引又分为两类:
- Local prefixed index(局部前缀索引)
- Local nonprefixed index(局部非前缀索引)
Ⅰ:局部前缀索引:以分区键作为索引定义的第一列
Ⅱ:局部非前缀索引:分区键没有作为索引定义的第一列
示例语句:
create table local_index_example
(
id number(2),
name varchar2(50),
sex varchar2(10)
) partition by range (id)
(
partition part_1 values less than (5),
partition part_2 values less than (10)
) --创建局部前缀索引;分区键(id)作为索引定义的第一列
create index local_prefixed_index on local_index_example (id, name) local; --创建局部非前缀索引;分区键未作为索引定义的第一列
create index local_nonprefixed_index on local_index_example (name, id) local;
注意:判断局部索引是前缀还是非前缀的只需要看分区键是否作为索引定义的第一列
3. 什么时候该使用前缀索引?什么时候该使用非前缀索引?
对于该使用前缀还是非前缀索引,这完全取决于你的实际需求,你应该尽量从实际角度出发选择合适的索引方式以充分利用到其分区消除的特性。
如果查询首先访问索引的话,它能否实现分区消除完全取决于查询中使用的谓词(即Where筛选条件);
比如用上面的 local_index_example 表举例,现有两个查询:
①: select … from local_index_example where id = :id and name = :name;
②: select … from local_index_example where name = :name;
对于以上两个查询来说,如果查询第一步是走索引的话,则:
局部前缀索引 local_prefixed_index 只对 ① 有用;
局部非前缀索引 local_nonprefixed_index 则对 ① 和 ② 均有用;
如果你有多个类似 ① 和 ② 的查询的话,则可以考虑建立局部非前缀索引;如果平常多使用查询 ① 的话,则可以考虑建立局部前缀索引;
总之,重点是你要尽可能保证查询包含的谓词允许索引分区消除
-------------------延伸阅读:绑定变量(bind variable)--------------------
绑定变量是查询中的一个占位符,形如 :xxx 。
例如,要获取 emp 表中 empno 为 123 的记录,你可以执行如下两种查询:
①: select * from emp where empno = 123;
②: 先将绑定变量 :empno 的值设置为 123,再执行查询 select * from emp where empno = :empno;
第一种查询使用了 123 这样一个直接量(常量),如果有多个这样的查询的话,则每一个查询对数据库来说都是一个全新的查询,Oracle每次都会对查询进行解析、限定(命名解析)、安全性检查、优化等(简单地讲,就是每次执行时都要先编译);
第二种查询使用了 :empno 这样一个绑定变量,变量值在查询时动态指定,这个查询只会在第一次时编译,随后Oracle会把查询计划存储在一个共享池中方便以后重用,如此当以后再传入不同的 empno 值进行查询时,Oracle会直接调用第一次解析好的这个执行计划进行执行,这样查询效率将大幅提升
------------------------------------------------------------------------
4. 局部索引的唯一性
Oracle只保证索引分区内部的唯一性,跨分区的唯一性无法保证。
如果你想使用局部索引实现唯一性约束的话,则必须让分区键实现唯一性约束(UNIQUE 或 PRIMARY KEY)
二:Globally partitioned index(全局分区索引)
1. 概念:
全局分区索引,顾名思义,就是针对整个表空间(全局)来说的。
在此,索引按范围(Range)或散列(Hash,Oracle 10g中引入)进行分区,一个分区索引(全局)可能指向任何(或全部的)表分区。
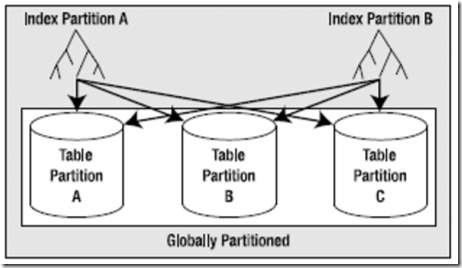
对于全局分区索引来说,索引的实际分区数可能不同于表的分区数量;
全局索引的分区机制有别于底层表,例如表可以按 done_date 列划分为10个分区,表上的一个全局索引可以按 id 列划分为5个分区。
与局部索引不同,全局索引只有一类,即全局前缀索引(prefixed global index),索引分区键必须作为索引定义的第一列,否则执行会报错。
用例语句:
--创建示例表,按id进行范围分区
create table global_index_example
(
id number(2),
name varchar2(50),
age number(2)
) partition by range (id)
(
partition part_1 values less than (5),
partition part_2 values less than (10)
) --创建按age进行范围分区的全局分区索引
create index global_index on global_index_example(age) global partition by range (age)
(
partition index_part_1 values less than (20),
partition index_part_2 values less than (maxvalue)
)
注意:
全局索引要求最高分区(即最后一个分区)必须有一个值为 maxvalue 的最大上限值,这样可以确保底层表的所有行都能放在这个索引中;
一般情况下,大多数分区操作(如删除一个旧分区)都会使全局索引无效,除非重建全局索引,否则无法使用
2. 全局索引的使用:
1) 数据仓库
许多数据仓库系统都存在大量的数据出入,如典型的数据“滑入滑出”(即删除表中最旧的分区,并为新加载的数据增加一个新分区);
这个过程涉及:
- 去除老数据:最旧的分区要么被删除,要么与一个空表交换(将最旧的分区变为一个表),从而允许对旧数据进行归档;
- 加载新数据并建立索引:将新数据加载到一个“工作”表中,建立索引并进行验证;
- 关联新数据:一旦加载并处理了新数据,数据所在的表会与分区表中的一个空分区交换,将表中的这些新加载的数据变成分区表中的一个分区(分区表会变得更大)
在 Oracle 9i 之前,对于创建的全局索引来说,这样增删分区的过程,意味着该全局索引的失效,你将不得不在最后花费相当长的时间重建全局索引;
在 Oracle 9i 之后,你可以在分区操作期间使用 UPDATE GLOBAL INEXES 子句来维护全局索引,这意味着当你在分区上执行删除、分解或其他操作时,Oracle会对原先建立的全局索引执行必要的修改,以保证它是最新的
使用示例:
--删除global_index_example表中的part_1分区,同时同步维护全局索引
alter table global_index_example drop partition part_1 update global indexes;
使用 UPDATE GLOBAL INEXES子句后,在删除一个分区时,必须删除可能指向该分区的所有全局索引条目;
执行表与分区的交换时,必须删除指向原数据的所有全局索引条目,再插入指向刚加载的数据的新条目;
如此一来 ALTER 命令执行的工作量会大幅增加;
注意:使用 UPDATE GLOBAL INDEXES,将不能绕过 undo 或 redo 生成;
小结:
分区操作执行完成后重建全局索引方式占用的数据库资源更少,因此完成的相对“更快”,但是会带来显著的“停机时间”(重建索引时会有一个可观的不可用窗口);
在分区操作执行的同时执行 UPDATE GLOBAL INEXES 子句方式会占用更多的资源,且可能需要花费更长的时间才能完成操作,但好处是不会带来任何的停机时间
----------------------------延伸阅读:redo(重做信息) 与 undo(撤销信息)------------------------------
什么是redo?
redo log file(重做日志文件),是数据库的事务日志。
Oracle维护着两类重做日志文件:在线(online)重做日志文件和归档(archived)重做日志文件,这两类重做日志文件用于实例失败或是介质失败时的数据恢复;
如果数据库所在主机突然断电导致实例失败,则Oracle会使用在线重做日志将系统恰好恢复到掉电之前的时间点;
如果硬盘出现故障(即介质失败),Oracle会使用归档重做日志和在线重做日志将硬盘上的数据恢复到适当的时间点;
另外如果你无意地删除了某些重要信息并提交了这个操作,那么可以恢复受影响数据的一个备份,并使用在线和归档重做日志文件把它恢复到之前的一个时间点;
重做日志可能是数据库中最重要的恢复结构,但同时其他部分(如undo段、分布式事务恢复等)也不可或缺,重做日志是数据库区别于传统文件系统的一个主要特征;
什么是undo?
当你对数数据执行修改(增、删等)时,数据库会生成undo信息,万一你执行的事务或语句由于某些原因失败时,或者你用一条 rollback 语句请求回滚时,数据库就可以利用这些undo信息将数据返回到修改前的样子。
redo用于在失败时恢复事务,undo则用于取消一条语句或一组语句的作用;
undo信息存储在数据库内部一组特殊的段中(undo segment);
注意:
undo并不是使数据库物理地恢复到执行语句或事务之前的样子,数据库只是逻辑地恢复到原来的样子,所有修改都被逻辑地取消,但是数据结构以及数据库块在回滚后可能还与回滚前保持一致;
因为在多用户系统中,可能会有数百或数千个并发事务,不仅仅你的事务在修改一些块,其他许多人的事务可能也在修改这些块;因此,不能简单地将一个块放回到你的事务开始前的样子,这样很可能会撤销掉其他人的事务工作。
比如:
假设你的事务执行了一个 insert 语句,这条语句导致分配了一个新区段;
通过执行这个 insert,你将会获得一个新的数据库块,并在格式化该块后往其中放入一些数据;
此时,可能出现另外某个事务,它也往这个块中插入数据;如果要回滚你的事务,显然不能取消对这个数据库块已有的格式化和空间分配,否则会影响到另外的那个事务的工作。
因此在回滚时,Oracle实际上会做与先前逻辑上相反的工作,即:
对于每个 insert,会执行一个 delete;
对于每个 delete,会执行一个 insert;
对于每个 update,会执行一个“反update”,或者是执行另一个 update 将修改前的行放回去;
还有一点需要特别注意:undo生成对于直接路径操作(即使用append提示进行insert)不适用,直接路径操作能绕过表上的undo生成;
如此,redo与undo共同协作以保证数据的完整与安全性
--------------------------------------------------------------------------------------------------
2) OLTP系统
OLTP系统的特点是会频繁出现许多小的读写事务,一般在OLTP系统中,首要的是需要快速访问所需的行,其次数据的完整性、可用性也非常重要。
在OLTP系统中,很多情况下全局索引很有意义,比如当表按一列分区后,你可能还需要通过其他列来快速访问数据,如此便可以考虑在这些列上建立全局索引。
Oracle分区索引的更多相关文章
- 01 Oracle分区索引
Oracle分区索引 索引与表类似,也可以分区: 分区索引分为两类: Locally partitioned index(局部分区索引) Globally partitioned index(全局 ...
- [Oracle]分区索引
上一节学习了分区表,接着学习分区索引. (一)什么时候对索引进行分区 · 为了避免移动数据时重建整个索引,可对索引分区,在重建索引时,只需重建与数据分区相关的索引: · 在对分区表进行维护时,为了避免 ...
- oracle 分区和分区索引
一.个人理解:建表时一般都会指定在一个表空间上,但是可能随着表空间扩大,查询越来越慢,分区表就是将一个表实际存在不同的表空间,oracle存储分为块,断,表空间.新建一个表,会给表分配指定大小的段,段 ...
- 深入学习Oracle分区表及分区索引
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: • Range(范围)分区 • Has ...
- 转:深入学习Oracle分区表及分区索引
转自:http://database.ctocio.com.cn/tips/286/8104286.shtml 关于分区表和分区索引(About Partitioned Tables and Inde ...
- oracle 分区表和分区索引
很复杂的样子,自己都没有看完,以备后用 http://hi.baidu.com/jsshm/item/cbfed8491d3863ee1e19bc3e ORACLE分区表.分区索引ORACLE对于分区 ...
- ORACLE分区表、分区索引详解
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt160 ORACLE分区表.分区索引ORACLE对于分区表方式其实就是将表分段 ...
- 【三思笔记】 全面学习Oracle分区表及分区索引
[三思笔记]全面学习Oracle分区表及分区索引 2008-04-15 关于分区表和分区索引(About PartitionedTables and Indexes) 对于 10gR2 而言,基本上可 ...
- 简单ORACLE分区表、分区索引
前一段听说CSDN.COM里面很多好东西,同事建议看看合适自己也可以写一写,呵呵,今天第一次开通博客,随便写点东西,就以第一印象分区表简单写第一个吧. ORACLE对于分区表方式其实就是将表分段存储, ...
随机推荐
- Entity Framework 6 Recipes 2nd Edition(10-1)译->非Code Frist方式返回一个实体集合
存储过程 存储过程一直存在于任何一种关系型数据库中,如微软的SQL Server.存储过程是包含在数据库中的一些代码,通常为数据执行一些操作,它能为数据密集型计算提高性能,也能执行一些为业务逻辑. 当 ...
- PHP 面向对象编程和设计模式 (4/5) - 异常的定义、扩展及捕获
PHP高级程序设计 学习笔记 2014.06.12 异常经常被用来处理一些在程序正常执行中遇到的各种类型的错误.比如做数据库链接时,你就要处理数据库连接失败的情况.使用异常可以提高我们程序的容错特性, ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(18)-权限管理系统-表数据
系列目录 这一节,我们插入数据来看看数据流,让各位同学,知道这个权限表交互是怎么一个流程,免得大家后天雾里来雾里去首先我再解释一些表,SysUser和SysRole表不用解释了. SysRoleSys ...
- JVM学习(4)——全面总结Java的GC算法和回收机制
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下: 一些JVM的跟踪参数的设置 Java堆的分配参数 -Xmx 和 –Xms 应该保持一个什么关系,可以让系统的 ...
- 【NLP】条件随机场知识扩展延伸(五)
条件随机场知识扩展延伸 作者:白宁超 2016年8月3日19:47:55 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有应 ...
- 【Android】开发中个人遇到和使用过的值得分享的资源合集
Android-Classical-OpenSource Android开发中 个人遇到和使用过的值得分享的资源合集 Trinea的OpenProject 强烈推荐的Android 开源项目分类汇总, ...
- ASP.NET Core 中文文档 第二章 指南(4.9)添加验证
原文:Adding Validation 作者:Rick Anderson 翻译:谢炀(Kiler) 校对:孟帅洋(书缘).娄宇(Lyrics).许登洋(Seay) 在本章节中你将为 Movie 模型 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Golang汇编命令解读
我们可以很容易将一个golang程序转变成汇编语言. 比如我写了一个main.go: package main func g(p int) int { return p+1; } func main( ...
- 自己封装的一个原生JS拖动方法。
代码: function drag(t,p){ var point = p || null, target = t || null, resultX = 0, resultY = 0; (!point ...