《Mysql 一条 SQL 更新语句是如何执行的?(Redo log)》
一:更新流程
- 对于更新来说,也同样会根据 SQL 的执行流程进行。
- 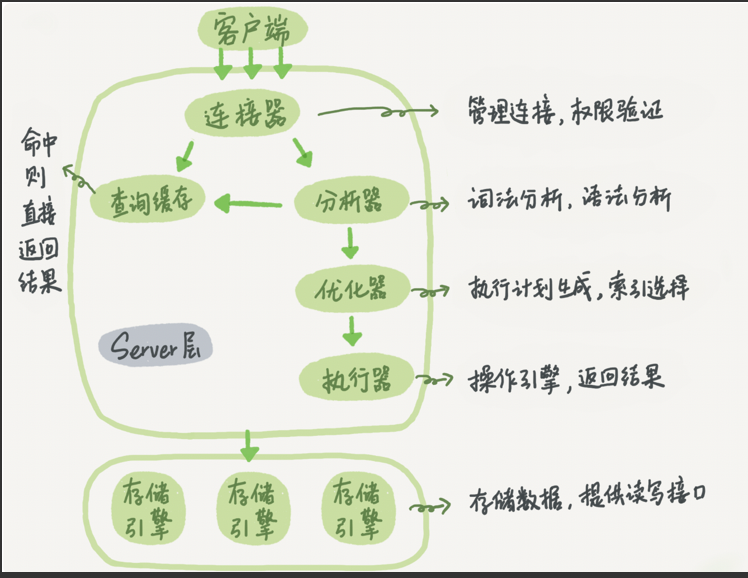
- 连接器
- 连接数据库,具体的不做赘述。
- 查询缓存
- 在一个表上有更新的时候,跟这个表有关的查询缓存会失效。
- 这也就是我们一般不建议使用查询缓存的原因。
- 分析器
- 接下来,分析器会通过词法和语法解析知道这是一条更新语句。
- 优化器
- 优化器决定要使用 ID 这个索引。
- 执行器
- 然后,执行器负责具体执行,找到这一行,然后更新。
- PS
- 与查询流程不一样的是,更新流程还涉及两个重要的日志模块,它们正是我们今天要讨论的主角:
- redo log(重做日志)和 binlog(归档日志)。
二: redo log
- Mysql 更新存在的问题
- 在 MySQL 中,如果每一条更新记录,都需要写入磁盘。
- 然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。
- 为了解决这个问题,MySQL 的设计者就用了 redo log 的概念来解决这个问题。
- redo log 概述
- redo log 是 InnoDB 独有的,属于 存储引擎层的
- redo log 工作流程
- 具体来说,当有一条记录更新的时候,InnoDB 引擎就会先把记录写到 redo log 里面,并更新内存,这个时候更新就算完成了。
- 同时,InnoDB 会在适当的时候,将这个操作记录更新到磁盘里面.
- PS
- InnoDB 的 redo log 是固定大小的
- 比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。
- 从头开始写,写到末尾就又回到开头循环写
- 当 redo log 被写满时候,这时候不能在执行新的更新,必须停下来,擦除一些 redo log 的日志,写入磁盘
- 有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe
三 :binlog
- binlog 概述
- binlog(归档日志) 是 Server 层特有的
- 为什么会有两份日志?
- 因为最开始 MySQL 里并没有 InnoDB 引擎。
- MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
- 而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的
- 所以 InnoDB 使用另外一套日志系统-- 就是 redo log 来实现 crash-safe 能力。
四 :binlog 和 redo log 的不同
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”
- binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;
- binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
五:再看 Update 执行过程
- 例如
- mysql> update T set c=c+1 where ID=2;
- 流程
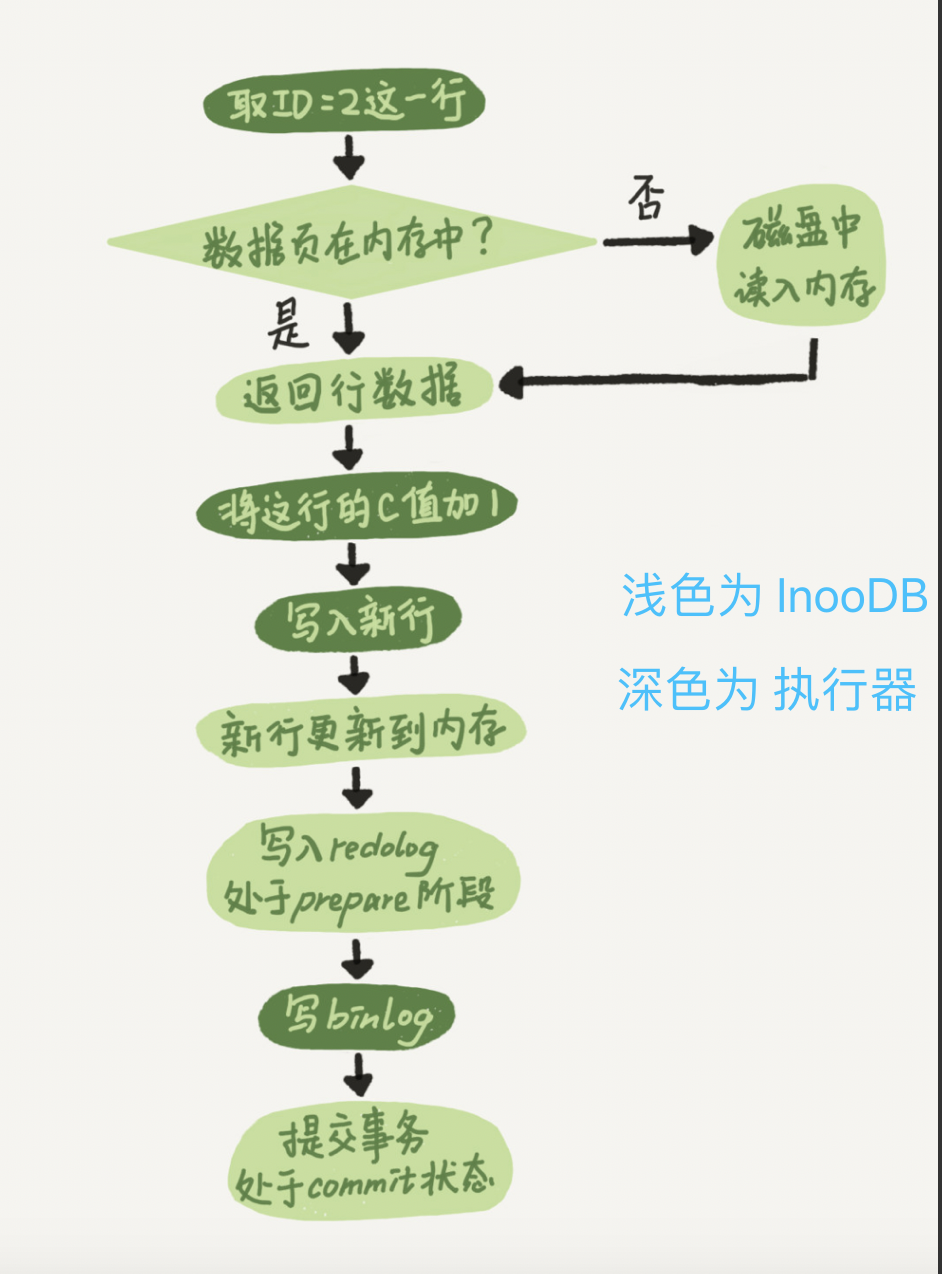
- 执行器先找引擎取 ID=2 这一行。
- ID 是主键,引擎直接用树搜索找到这一行。
- 如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器
- 否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据
- 把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中
- 同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。
- 然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
- 
六:redo 的 “两阶段提交”
- 根据上面的流程图,可以看到,redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。
- 原因
- 由于 redo log 和 binlog 是两个独立的逻辑
- 如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者采用反过来的顺序,会导致数据的不一致出现。
- 简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
- 举例一个完整的交易流程
- 账本记上 卖一瓶可乐(redo log为 prepare状态),然后收钱放入钱箱(bin log记录)然后回过头在账本上打个勾(redo log置为commit)表示一笔交易结束。
- 如果收钱时交易被打断,回过头来整理此次交易,发现只有记账没有收钱,则交易失败,删掉账本上的记录(回滚)
- 如果收了钱后被终止,然后回过头发现账本有记录(prepare)而且钱箱有本次收入(bin log),则继续完善账本(commit),本次交易有效。
七:小结
- redo log 用于保证 crash-safe 能力。
- innodb_flush_log_at_trx_commit 这个参数设置成 1 的时候,表示每次事务的 redo log 都直接持久化到磁盘。
- 这个参数建议设置成 1,这样可以保证 MySQL 异常重启之后数据不丢失。
- sync_binlog 这个参数设置成 1 的时候,表示每次事务的 binlog 都持久化到磁盘。
- 这个参数也建议设置成 1,这样可以保证 MySQL 异常重启之后 binlog 不丢失。
- 还介绍了与 MySQL 日志系统密切相关的“两阶段提交”。
- 两阶段提交是跨系统维持数据逻辑一致性时常用的一个方案,即使你不做数据库内核开发,日常开发中也有可能会用到。
《Mysql 一条 SQL 更新语句是如何执行的?(Redo log)》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- windows gogs 安装
windows 安装gogs: 1. 先下载 gogs ,直接解压.不用安装 https://dl.gogs.io/0.11.86/gogs_0.11.86_windows_amd64_mws.zip ...
- CSPS模拟86-87
模拟86 T1,烧水,按位统计贡献,利用某种sao操作避免数位dp #include<iostream> #include<cstdio> #include<cstrin ...
- 二分算法题目训练(三)——Anton and Making Potions详解
codeforces734C——Anton and Making Potions详解 Anton and Making Potions 题目描述(google翻译) 安东正在玩一个非常有趣的电脑游戏, ...
- 经常用到(创建OS)的命令
1. 将汇编代码编译为二进制模块文件 nasm mbr.asm -o mbr nasm loader.asm -o loader 2. 将wirte.c ...
- faster-rcnn CUDA8.0编译错误
之前编译Faster-RCNN的时候用的都是CUDA7.5,最近换了机器,变成了CUDA8.0,果然编译出现错误了…… 参考下面这篇博客解决了问题: http://blog.csdn.net/kexi ...
- Flask上下文源码分析(二)
前面第一篇主要记录了Flask框架,从http请求发起,到返回响应,发生在server和app直接的过程. 里面有说到,Flask框架有设计了两种上下文,即应用上下文和请求上下文 官方文档里是说先理解 ...
- IIS/VS IIS Express 添加MIME映射 svg、woff、woff2、json
出现问题 页面提示 font-awesome/fonts/fontawesome-webfont.woff2?v=4.3.0 Failed to load resource: the server r ...
- CentOS7系统下GitLab的安装、汉化、修改默认端口、开启发送邮箱
一.centos7.4 下安装及汉化 =============================================== 2017/11/12_第6次修改 ...
- Java并发包线程池之ThreadPoolExecutor
参数详解 ExecutorService的最通用的线程池实现,ThreadPoolExecutor是一个支持通过配置一些参数达到满足不同使用场景的线程池实现,通常通过Executors的工厂方法进行配 ...
- CentOS7下搭建zabbix监控(五)——Web端配置自动发现并注册
好像有点问题,没法自动添加主机,我后期再测测 (1).自动发现主机并注册 1)创建发现规则 2)编辑自动发现规则信息(这两步不配置问题也不大,因为在动作中也有主机IP地址) 3)添加自动发现的动作 4 ...