使用scikit-learn决策树实现简单预测
1、scikit-learn决策树算法库介绍
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。
本实例采用分类库来做。
2、各环境安装
我使用的是python3环境
安装scikit-learn:pip3 install scikit-learn
安装numpy:pip3 install numpy
安装scipy:pip3 install scipy
安装matplotlib:pip3 install matplotlib
3、切入正题
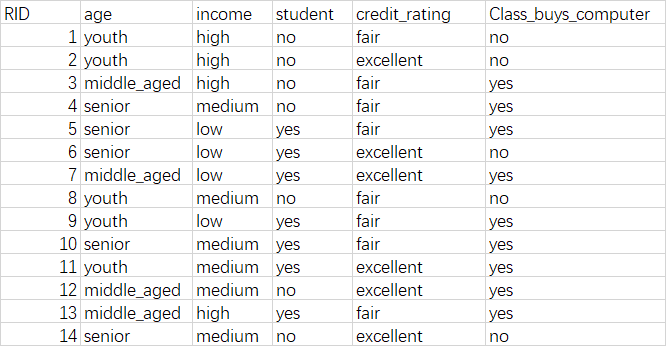
首先:我的原始数据是Excel文件,将它保存为csv格式,如data.csv
下面建一个python文件
首先读取数据
import csv # 这个库是python自带的用来处理csv数据的库
# 读取csv数据文件
allElectronicsData = open('data.csv', 'r',encoding='utf8')
reader = csv.reader(allElectronicsData) # 按行读取内容
headers=next(reader) #读取第一行的标题
因为scikit-learn处理数据时对数据的格式有要求,要求是矩阵格式的,所以对读取的数据进行预处理,处理成要求的格式。
# 对数据进行预处理,转换为字典形式
featureList = []
labelList = [] # 将每一行的数据编程字典的形式存入列表
for row in [rows for rows in reader]:
# print(row)
labelList.append(row[len(row) - 1]) # 存入目标结果的数据最后一列的
rowDict = {}
for i in range(1, len(row) - 1):
# print(row[i])
rowDict[headers[i]] = row[i]
# print('rowDict:', rowDict)
featureList.append(rowDict)
print(featureList)
使用scikit-learn自带的DictVectorizer()类将字典转换为要求的矩阵数据
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
# 将原始数据转换成矩阵数据
vec=DictVectorizer()
dummyX=vec.fit_transform(featureList).toarray() # 将参考的列转化维数组 print('dummyX:'+str(dummyX))
print(vec.get_feature_names()) print('labellist:'+str(labelList)) # 将要预测的列转化为数组
lb=preprocessing.LabelBinarizer()
dummyY=lb.fit_transform(labelList)
print('dummyY:'+str(dummyY))
创建决策树:
from sklearn import tree
# 创建决策树
clf=tree.DecisionTreeClassifier(criterion='entropy')#指明为那个算法
clf=clf.fit(dummyX,dummyY)
print('clf:'+str(clf))
将决策树可视化输出:使用graphviz(下载地址)进行可视化
安装:将下载的zip文件解压到合适的位置,然后将bin目录添加到系统path中。
使用pydotplus模块输出pdf决策树。pydotplus安装:pip3 install pydotplus
# 直接导出为pdf树形结构
#import pydot
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
# graph = pydot.graph_from_dot_data(dot_data.getvalue())
# graph[0].write_pdf("iris.pdf")
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("mytree.pdf")
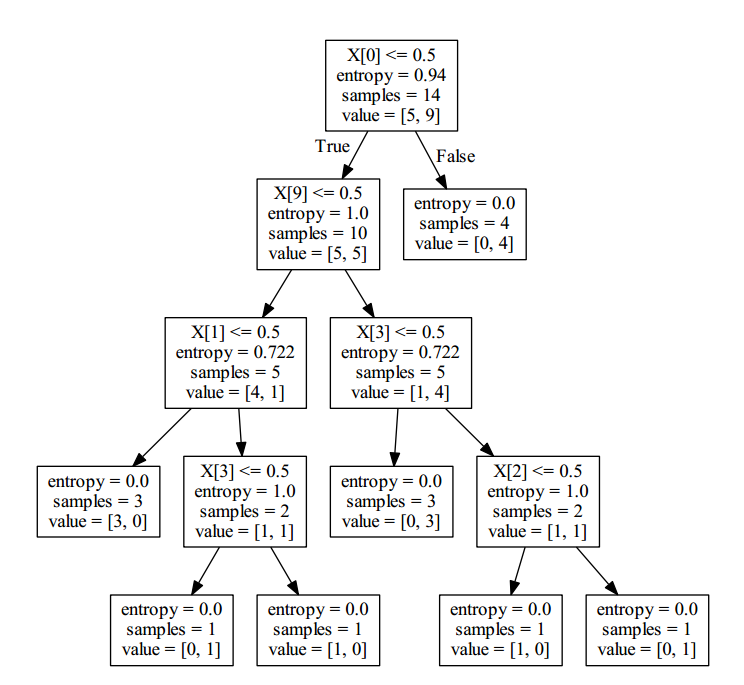
最后对新的数据进行预测:
# 预测数据
one=dummyX[2, :]
print('one'+str(one))
# one输出为one[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
# 上面的数据对应下面列表:
#['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes'] # 设置新数据
new=one
new[4]=1
new[3]=0
predictedY=clf.predict(new.reshape(-1,10))# 对新数据进行预测
print('predictedY:'+str(predictedY)) # 输出为predictedY:[1],表示愿意购买,1表示yes
下面附上全部代码:
# -*- coding: utf-8 -*-
# @Author : FELIX
# @Date : 2018/3/20 20:37
import csv
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO # 读取csv数据文件
allElectronicsData = open('data.csv', 'r',encoding='utf8')
reader = csv.reader(allElectronicsData)# 按行读取内容
headers=next(reader) # print(list(reader))
#
# 对数据进行预处理,转换为矩阵形式
featureList = []
labelList = [] # 将每一行的数据编程字典的形式存入列表
for row in [rows for rows in reader]:
# print(row)
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
# print(row[i])
rowDict[headers[i]] = row[i]
# print('rowDict:', rowDict)
featureList.append(rowDict)
print(featureList) # 将原始数据转换成矩阵数据
vec=DictVectorizer()
dummyX=vec.fit_transform(featureList).toarray() # 将参考的列转化维数组 print('dummyX:'+str(dummyX))
print(vec.get_feature_names()) print('labellist:'+str(labelList)) # 将要预测的列转化为数组
lb=preprocessing.LabelBinarizer()
dummyY=lb.fit_transform(labelList)
print('dummyY:'+str(dummyY)) # 创建决策树
clf=tree.DecisionTreeClassifier(criterion='entropy')#指明为那个算法
clf=clf.fit(dummyX,dummyY)
print('clf:'+str(clf)) # 直接导出为pdf树形结构
import pydot,pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data)
# graph = pydot.graph_from_dot_data(dot_data.getvalue())
# graph[0].write_pdf("iris.pdf")
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("iris2.pdf") with open('allElectronicInformationGainOri.dot','w') as f:
f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f)
# 通过命令行dot -Tpdf allElectronicInformationGainOri.dot -o output.pdf 输出树形结构 # 预测数据
one=dummyX[2, :]
print('one'+str(one))
# one输出为one[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
# 上面的数据对应下面列表:
#['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes'] # 设置新数据
new=one
new[4]=1
new[3]=0
predictedY=clf.predict(new.reshape(-1,10))# 对新数据进行预测
print('predictedY:'+str(predictedY)) # 输出为predictedY:[1],表示愿意购买,1表示yes
全部代码
使用scikit-learn决策树实现简单预测的更多相关文章
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- Spark技术在京东智能供应链预测的应用——按照业务进行划分,然后利用scikit learn进行单机训练并预测
3.3 Spark在预测核心层的应用 我们使用Spark SQL和Spark RDD相结合的方式来编写程序,对于一般的数据处理,我们使用Spark的方式与其他无异,但是对于模型训练.预测这些需要调用算 ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- 【Machine Learning in Action --3】决策树ID3算法预测隐形眼睛类型
本节讲解如何预测患者需要佩戴的隐形眼镜类型. 1.使用决策树预测隐形眼镜类型的一般流程 (1)收集数据:提供的文本文件(数据来源于UCI数据库) (2)准备数据:解析tab键分隔的数据行 (3)分析数 ...
随机推荐
- Board Game CodeForces - 605D (BFS)
大意: 给定$n$张卡$(a_i,b_i,c_i,d_i)$, 初始坐标$(0,0)$. 假设当前在$(x,y)$, 若$x\ge a_i,y\ge b_i$, 则可以使用第$i$张卡, 使用后达到坐 ...
- hdu 2844 多重背包的转化问题 以及这个dp状态的确定
在杭电上测试了下 这里的状态转移方程有两个.,. 现在有价值val[1],val[2],…val[n]的n种硬币, 它们的数量分别为num[i]个. 然后给你一个m, 问你区间[1,m]内的所有数目, ...
- (五)Maven中的聚合和继承
一.为什么要聚合? 定义:我们在开发过程中,创建了2个以上的模块,每个模块都是一个独立的maven project,在开始的时候我们可以独立的编译和测试运行每个模块,但是随着项目的不断变大和复杂化,我 ...
- 【转载】SpringBoot yml 配置
1. 在 spring boot 中,有两种配置文件,一种是application.properties,另一种是application.yml,两种都可以配置spring boot 项目中的一些变量 ...
- linux内核过高导致vm打开出错修复脚本
#!/bin/bashVMWARE_VERSION=workstation-15.1.0TMP_FOLDER=/tmp/patch-vmwarerm -fdr $TMP_FOLDERmkdir -p ...
- Android中ListView的使用
1.主要概念 ListView用于将大数据集以列表的形式展示. ListView可以看成一个容器,它有如下继承链: View <- ViewGroup <- AdapterView < ...
- php定界符介绍
php界定符就是为了照样输出内容.它的格式如下: <<<EOF ...... EOF; 其中EOF是自定义的变量,但要成对出现! 首先附上一段php代码: <?php $a = ...
- Cause: com.mysql.jdbc.PacketTooBigException: Packet for query is too large (16944839 > 16777216). You can change this value on the server by setting the max_allowed_packet' variable.
今天发现task微服务的error日志报如下错误: Cause: com.mysql.jdbc.PacketTooBigException: Packet for query is too large ...
- K2 BPM_万翼科技携手上海斯歌,全面启动K2平台升级项目_十年专注业务流程管理系统
2019年7月25日,万翼科技和上海斯歌在深圳召开了“2019年K2平台升级项目启动会”.万翼科技核心合伙人何建春.管金华,协同管理支撑组负责人贾磊,K2平台产品负责人黄平显,上海斯歌总裁李明,技术研 ...
- Spring3.2.2中相关Jar包的作用
今天在看Spring的源码的时候不知道从什么地方开启应该合适,因为不太清楚实现类所在的具体Jar包,就从网上找了些,可是网上有的说的是不清不楚,甚至是有些错误的,所以就把相关Jar包的大致作用给整理了 ...