OpenTSDB在HBase中的底层数据结构设计
0.时序数据库
时间序列(Time Series):是一组按照时间发生先后顺序进行排列的数据点序列,通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,1小时等)。
时间序列数据可被简称为时序数据。实时监控系统所收集的监控指标数据,通常就是时序数据 。时序数据具有如下特点:
- 每一个时间序列通常为某一固定类型的数值
- 数据按一定的时间间隔持续产生,每条数据拥有自己的时间戳信息
- 通常只会不断的写入新的数据,几乎不会有更新、删除的场景
- 在读取上,也往往倾向于读取最近写入的数据。
OpenTSDB是其中一种时序数据库实现,是一种基于Hbase、分布式、可伸缩的时间序列数据库。
1.OpenTSDB基本概念
- metric:指标名,这个就是我们监控的指标,比如 sys.cpu.user;
- timestamp:时间戳,监控数据产生的时间;
- value:监控值,Long 或者 Double 类型的数据,这个是监控指标在某个时间的具体值;
- tag:标签,包括标签名字(tagk)和标签值(tagv),比如 tagk1=tagv1,主要用于描述数据属性,每条时序数据必须包含一组和多组的标签数据。目前 OpenTSDB 最多支持8组标签。
2.数据样例:
sys.cpu.user host=webserver01
sys.cpu.user host=webserver01,cpu=
sys.cpu.user host=webserver01,cpu=
sys.cpu.user host=webserver01,cpu=
sys.cpu.user host=webserver01,cpu=
............
sys.cpu.user host=webserver01,cpu=
其中,每一行表示时间序列中的一个DataPoint,每部分对应如下:

每一个Data Point,都关联一个metrics名称,但可能关联多组<tagKey,tagValue>信息。而关于时间序列,事实上就是具有相同的metrics名称以及相同的<tagKey,tagValue>组信息的Data Points的集合。
3.存储模型
OpenTSDB是基于HBase进行数据存储,在HBase中存放tsdb、tsdb-meta、tsdb-tree、tsdb-uid四张表,主要用到的是tsdb、tsdb-uid两个。
1)tsdb-uid
为了统一各个值的长度以及节省空间,OpenTSDB中为每一个metrics名、tagKey以及tagValue都定义了一个唯一的数字类型的标识码(Unique Identifier, UID),这些UID信息被保存在OpenTSDB的元数据表tsdb-uid中。同时,为了从UID索引到metrics(或tagKey、tagValue),同时也要从metrics(或tagKey、tagValue)索引到UID,OpenTSDB同时保存了这两种映射关系数据。
列族Column Family:
在元数据表中,把这两种数据分别保存到两个名为"id"与"name"的列族(Column Family)中,Column Family描述信息如下所示:
{NAME => 'id', BLOOMFILTER => 'ROW', COMPRESSION => 'SNAPPY'}
{NAME =>'name',BLOOMFILTER => 'ROW', COMPRESSION => 'SNAPPY', MIN_VERSIONS => '', BLOCKCACHE => 'true', BLOCKSIZE => '', REPLICATION_SCOPE => ''}
OpenTSDB分配UID时遵循如下规则:
- metrics、tagKey和tagValue的UID分别独立分配
- 每个metrics名称(或tagKey/tagValue)的UID值都是唯一。不存在不同的metrics(或tagKey/tagValue)使用相同的UID,也不存在同一个metrics(或tagKey/tagValue)使用多个不同的UID
- UID值使用三个字节进行存储,其范围是0x000000到0xFFFFFF。
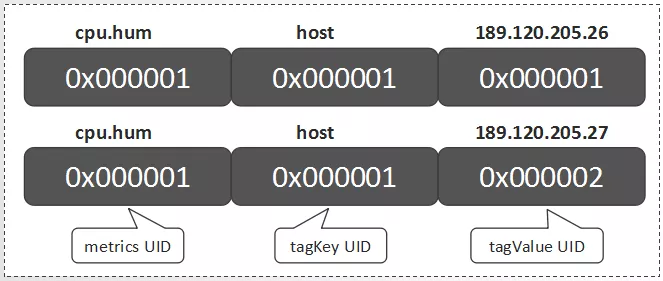
关于metrics名为"cpu.hum",tagKey值为"host",tagValue值分别为"189.120.205.26"、"189.120.205.27"的UID信息定义如下:

说明:
- RowKey为"0"的行中,分别保存了metrics、tagKey和tagValue的当前UID的最大值。当为新的metrics、tagKey和tagValue分配了新的UID后,会更新对应的最大值
- RowKey为"1"的行中,RowKey为UID,Qualifier(列名)为"id:metrics"的值"metrics",Qualifier为"id:tagk"的值为tagKey,Qualifier为id:tagv的值为tagValue
- RowKey为"2"的行中,RowKey为UID,Qualifier为"id:tagv"的值为tagValue,暂不存在UID为"2"的metrics和tagKey
- RowKey为"189.120.205.26"的行中,Qualifer为"name:tagv"的值为UID。表示当"189.120.205.26"为tagValue时,其UID为1
- RowKey为"189.120.205.27"的行中,Qualifer为"name:tagv"的值为UID。表示当"189.120.205.26"为tagValue时,其UID为2
- RowKey为"cpu.hum"的行中,Qualifer为"name:metrics"的值为UID。表示当cpu.hum为metrics时,其UID为1
- RowKey为"host"的行中,Qualifer为"name:tagk"的值为UID。表示当host为tagValue时,其UID为1
由于HBase的存储数据类型是Bytes,所以UID在存储时会被转换为3个字节长度的Bytes数组进行存储。
TUID:
对每一个Data Point,metrics、timestamp、tagKey和tagValue都是必要的构成元素。除timestamp外,metrics、tagKey和tagValue的UID就可组成一个TSUID,每一个TSUID关联一个时间序列,如下所示:
<metrics_UID><tagKey1_UID><tagValue1_UID>[...<tagKeyN_UID><tagValueN_UID>]
在上面的例子中就涉及两个TSUID,分别是:
2)tsdb

tsdb为存放OpenTSDB中所有数据记录的表,下面具体介绍tsdb的结构设计。
① RowKey设计
tsdb的HBase RowKey中包含主要组成部分为:盐值(Salt)、metrics名称、时间戳、tagKey、tagValue等部分。
在tsdb-uid中提到,为了统一各个值的长度以及节省空间,对metrics名称、tagKey和tagValue分配了UID信息。所以,在HBase RowKey中实际写入的是metrics UID、tagKey UID和tagValue UID(存放在tsdb-uid中)。
HBase RowKey的数据模型如下图所示:
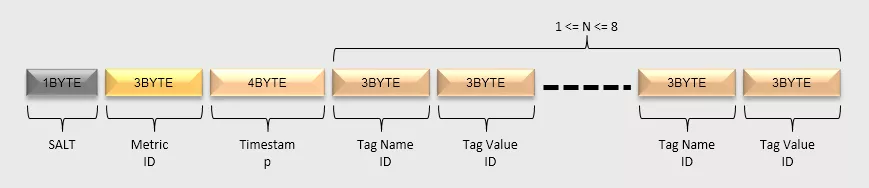
- SALT:建议开启SALT功能,可以有效提高性能。SALT数据的长度是变长的:如果SALT的值值少于256,那么只用一个字节表示即可;如果需要设置更大的SALT值,也会相应地占用更多的空间。
- Metric ID:metrics名经过编码后,每个Metric ID的长度为三个字节。
- Timestamp:这里整点小时级别的时间戳。
- tagKey UID & tagValue UID:tagKey和tagValue经过编码后,每个tagKey UID和tagValue UID的长度都为三个字节。tagKey UID和tagValue UID必须成对出现,最少必须存在1对,最多存在8对。
② Qualifier设计
Qualifier用于保存一个或多个DataPoint中的时间戳、数据类型、数据长度等信息。
由于时间戳中的小时级别的信息已经保存在RowKey中了,所以Qualifier只需要保存一个小时中具体某秒或某毫秒的信息即可,这样可以减少数据占用的空间。
一个小时中的某一秒(少于3600)最多需要2个字节即可表示,而某一毫秒(少于3600000)最多需要4个字节才可以表示。为了节省空间,OpenTSDB没有使用统一的长度,而是对特定的类型采用特性的编码方法。Qualifer的数据模型主要分为如下三种情况:秒、毫秒、秒和毫秒混合。
秒类型
当OpenTSDB接收到一个新的DataPoint的时候,如果请求中的时间戳是秒,那么就会插入一个如下模型的数据。
判断请求中的时间戳为秒或毫秒的方法是基于时间戳数值的大小,如果时间戳的值的超过无符号整数的最大值(即4个字节的长度),那么该时间戳是毫秒,否则为秒。

- Value长度:Value的实际长度是Qualifier的最后3个bit的值加1,即(qualifier & 0x07) + 1。表示该时间戳对应的值的字节数。所以,值的字节数的范围是1到8个字节。
- Value类型:Value的类型由Qualifier的倒数第4个bit表示,即(qualifier & 0x08)。如果值为1,表示Value的类型为float;如果值为0,表示Value的类型为long。
- 时间戳:时间戳的值由Qualifier的第1到第12个bit表示,即(qualifier & 0xFFF0) >>>4。由于秒级的时间戳最大值不会大于3600,所以qualifer的第1个bit肯定不会是1。
毫秒类型
当OpenTSDB接收到一个新的DataPoint的时候,如果请求中的时间戳是毫秒,那么就会插入一个如下模型的数据。

- Value长度:与秒类型相同。
- Value类型:与秒类型相同。
- 时间戳: 时间戳的值由Qualifier的第5到第26个bit表示,即(qualifier & 0x0FFFFFC0) >>>6。
- 标志位:标志位由Qualifier的前4个bit表示。当该Qualifier表示毫秒级数据时,必须全为1,即(qualifier[0] & 0xF0) == 0xF0。
- 第27到28个bit未使用。
混合类型
当同一小时的数据发生合并后,就会形成混合类型的Qualifier。
合并的方法很简单,就是按照时间戳顺序进行排序后,从小到大依次拼接秒类型和毫秒类型的Qualifier即可。

- 秒类型和毫秒类型的数量没有限制,并且可以任意组合。
- 不存在相同时间戳的数据,包括秒和毫秒的表示方式。
遍历混合类型中的所有DataPoint的方法是:
- 从左到右,先判断前4个bit是否为0xF
- 如果是,则当前DataPoint是毫秒型的,读取4个字节形成一个毫秒型的DataPoint
- 如果否,则当前DataPoint是秒型的,读取2个字节形成一个秒型的DataPoint
- 以此迭代即可遍历所有的DataPoint
③ Value设计
按照时间戳的顺序,把多个Value拼接起来的数据模型如下:

每个格子表示一个DataPoint Value的值,这个DataPoint Value的长度可能是1或2或4或8个字节。
DataPoint Value的顺序与Qualifier中时间戳的顺序一一对应。
混合标志:如果最后1个字节为0x01,表示存在秒级类型和毫秒级类型混合的情况。
指标名字:这个就是我们监控的指标,比如 sys.cpu.user;
时间戳:监控数据产生的时间;
值:Long 或者 Double 类型的数据,这个是监控指标在某个时间的具体值;
标签:包括标签名字(tagk)和标签值(tagv),比如 tagk1=tagv1,主要用于描述数据属性,每条时序数据必须包含一组和多组的标签数据。目前 OpenTSDB 最多支持8组标签。
参考:
OpenTSDB在HBase中的底层数据结构设计的更多相关文章
- 使用bulkload向hbase中批量写入数据
1.数据样式 写入之前,需要整理以下数据的格式,之后将数据保存到hdfs中,本例使用的样式如下(用tab分开): row1 N row2 M row3 B row4 V row5 N row6 M r ...
- 用Spark查询HBase中的表数据
java代码如下: package db.query; import org.apache.commons.logging.Log; import org.apache.commons.logging ...
- hbase中double类型数据做累加
public static Result incr(String tableFullName, String rowKey, String family, String qualifier, long ...
- Redis 底层数据结构设计
10万+QPS 真的只是因为单线程和基于内存?_Howinfun的博客-CSDN博客_qps面试题 https://blog.csdn.net/Howinfun/article/details/105 ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- talend 将hbase中数据导入到mysql中
首先,解决talend连接hbase的问题: 公司使用的机器是HDP2.2的机器,上面配置好Hbase服务,在集群的/etc/hbase/conf/hbase-site.xml下,有如下配置: < ...
- HBase中的备份和故障恢复方法
本文将对Apache HBase可用的数据备份机制和大量数据的故障恢复/容灾机制做简要介绍. 随着HBase在重要的商业系统中应用的大量添加,很多企业须要通过对它们的HBase集群建立健壮的备份和故障 ...
- hadoop生态系统学习之路(八)hbase与hive的数据同步以及hive与impala的数据同步
在之前的博文中提到,hive的表数据是能够同步到impala中去的. 一般impala是提供实时查询操作的,像比較耗时的入库操作我们能够使用hive.然后再将数据同步到impala中.另外,我们也能够 ...
- 将HBase中的表加载到hive中
两种方式加载hbase中的表到hive中,一是hive创建外部表关联hbase表数据,二是hive创建普通表将hbase的数据加载到本地 1. 创建外部表 hbase中已经有了一个test表,内容如下 ...
随机推荐
- LibreOffice/Calc:带条件判断的求和
本文适用于LibreOffice Calc 5.1.6.2 + Ubuntu 16.04,熊猫帮帮主@cnblogs 2018/3/7 以下图为例,假设要根据C列对D列中被选中单元进行求和,即对D列中 ...
- 【Nginx】 linux环境下安装nginx步骤
开始前,请确认gcc g++开发类库是否装好,默认已经安装. centos平台编译环境使用如下指令 安装make: yum -y install gcc automake autoconf libto ...
- elasticsearch 单实例安装启动
elasticsearch 初次启动 下载 elasticsearch-6.3.2.tar.gz 创建目录 /usr/local/elasticsearch/ 解压 tar -zxf elastics ...
- 学习 vue 需要了解的内容
总结 vue 的目录 1. vue 基础 指令 事件 动态的属性 组件 动画 2. vue 组件通信 1. 父传子 props 2. 子传父 ref 3. 插槽 4. 组件的生命周期 3. vue 的 ...
- Android jni/ndk编程三:native访问java
一.访问静态字段 Java层的field和method,不管它是public,还是package.private和protected,从 JNI都可以访问到,Java面向语言的封装性不见了. 静态字段 ...
- 代码实现:键盘录入一个int类型的整数,对其求二进制表现形式
package com.loaderman.test; import java.math.BigDecimal; import java.math.BigInteger; import java.ut ...
- 溢出overflow: hidden
如果要防止内容把div容器或者表格撑大,可以在CSS中设置一.overflow: hidden; 表示如果内容超出容器大小,就把超出部分隐藏(相当于切掉)二.overflow: scroll; 这个表 ...
- U盘文档自动备份
检测到插入U盘即复制其中doc.ppt文件到指定目录 (ucopy.bat): @echo off :again del /Q /f "%temp%\copy.tmp" >n ...
- 2019.12.24 【ABAP随笔】smartforms 打印及PDF转化
冬至已过,又临平安夜和圣诞,又是一年的末尾,闲暇时间需要静下心来温故而知新. 许久未碰打印,知识于脑子又有几分糊涂,遂整理些许知识,记录. 数据随便取于物料表 report Z_smartforms ...
- Jconsole、JvisualVM无法连接Tomcat服务
转载自:https://blog.csdn.net/qq_27790011/article/details/88799587 打开TomcatXw.exe找到java选项卡,添加以下参数 -Dcom. ...