ElasticSearch——分词
前言:
最近在使用elasticSearch中发现有些数据查不出来,于是研究了一下,发现是分词导致的,现梳理并总结一下。
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
ElasticSearch字符串将默认被同时映射成text和keyword类型,将会自动创建下面的动态映射(dynamic mappings):
"relateId": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
这就是造成部分字段还会自动生成一个与之对应的“.keyword”字段的原因。
存储查询示例:
relateId存储:20191101R672499460503 1个值
relateId.keyword存储:20191101 R 672499460503 3个值
这时用relateId进行精确查询,查不出数据,因为已经被分成3个词了:
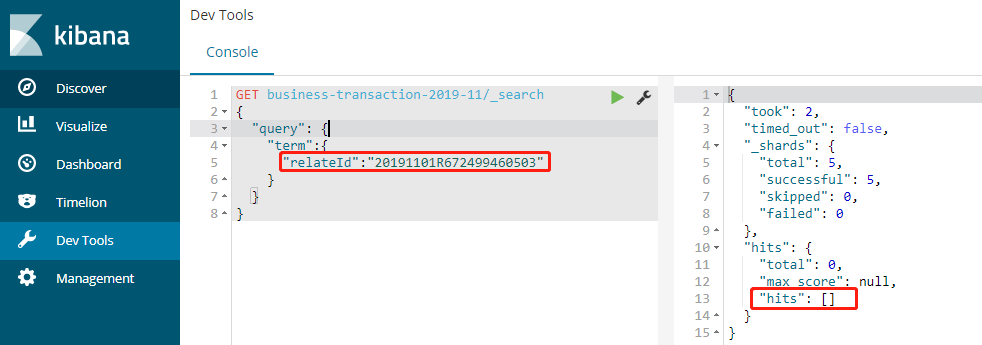
用relateId.keyword进行精确查询则可以查出数据来:
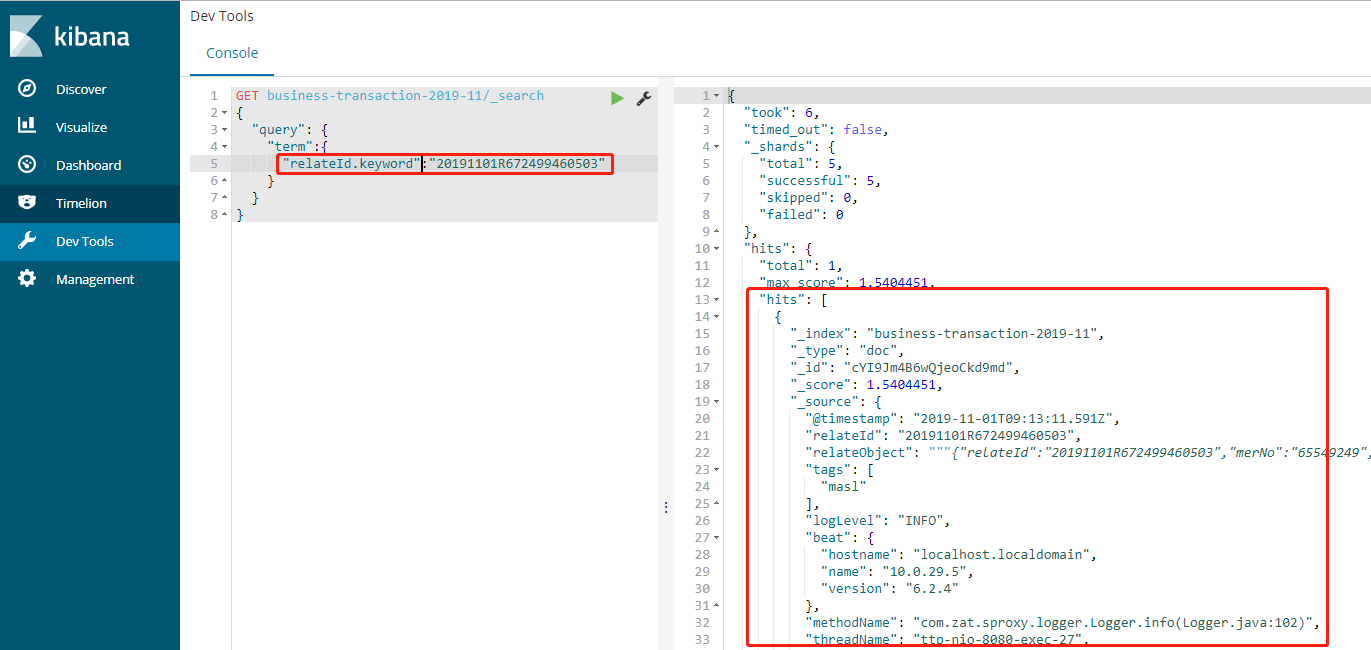
两者比较:
Text:默认会分词,然后进行索引,支持模糊、精确查询,不支持聚合
keyword:不进行分词,直接索引,支持模糊、精确查询,支持聚合
进阶处理:
注意:Text默认会分词,这是很智能的,但在有些字段里面是没用的,所以对于有些字段使用text则浪费了空间。这时可以设置mapping为not analyzied,让它不分词。
"relateId": {
"type": "text",
"index": "not_analyzed"
}
如果要指定分词则用下面的方式:
"relateId": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above":
}
}
}
ElasticSearch——分词的更多相关文章
- Elasticsearch——分词器对String的作用
更多内容参考:Elasticsearch学习总结 关于String类型--分词与不分词 在Elasticsearch中String是最基本的数据类型,如果不是数字或者标准格式的日期等这种很明显的类型, ...
- elasticsearch分词插件的安装
IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Luen ...
- elasticsearch分词器Jcseg安装手册
Jcseg是什么? Jcseg是基于mmseg算法的一个轻量级中文分词器,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了一个基于Jetty的web服务器,方便各大语言 ...
- Elasticsearch 分词器
无论是内置的分析器(analyzer),还是自定义的分析器(analyzer),都由三种构件块组成的:character filters , tokenizers , token filters. 内 ...
- elasticsearch分词器ik
1. 下载和es配套的版本 git clone https://github.com/medcl/elasticsearch-analysis-ik 2. 编译 cd elasticsearch-an ...
- Elasticsearch分词导致的查找错误
这周在做视频搜索的过程中遇到一个问题,就是用下面的查询表达式去Elasticsearch检索,检索不到想要的结果.查询语句如下: 而查询的字段的值为: "mergeVideoName&quo ...
- ElasticSearch分词器
什么是分词器? 分词器,是将用户输入的一段文本,分析成符合逻辑的一种工具.到目前为止呢,分词器没有办法做到完全的符合人们的要求.和我们有关的分词器有英文的和中文的.英文的分词器过程:输入文本-关键词切 ...
- 掌握 analyze API,一举搞定 Elasticsearch 分词难题
初次接触 Elasticsearch 的同学经常会遇到分词相关的难题,比如如下这些场景: 为什么明明有包含搜索关键词的文档,但结果里面就没有相关文档呢? 我存进去的文档到底被分成哪些词(term)了? ...
- ElasticSearch 分词器,了解一下
这篇文章主要来介绍下什么是 Analysis ,什么是分词器,以及 ElasticSearch 自带的分词器是怎么工作的,最后会介绍下中文分词是怎么做的. 首先来说下什么是 Analysis: 什么是 ...
随机推荐
- HandlerMethodArgumentResolver完美解决 springmvc注入参数多传报错
作为一个后端开发,能友好兼容前端参数传入错误等问题,在前端发布不小心多传一个参数导致系统错误的问题,一个广告系统是零容忍的,所以为了不犯错误,后端接收参数必须摒弃spring 的自动注入@Reques ...
- 少有人知的 GitHub 使用技巧
GitHub 大家常上吧?可是使用 GitHub 的各种小窍门你就不一定知道了.本文将各种使用 GitHub 的小窍门分享给大家. diff时忽略空格 有些修改只是增减了空格,在URL中添加?w=1就 ...
- Ubuntu 18.04实现实时显示网速
1.添加源 sudo add-apt-repository ppa:fossfreedom/indicator-sysmonitor 2.更新源 sudo apt-get update 3.安装sys ...
- [SCOI2016]美味——主席树+按位贪心
原题戳这里 题解 让异或值最大显然要按位贪心,然后我们还发现加上一个\(x_i\)的效果就是所有\(a_i\)整体向右偏移了,我们对于\({a_i}\)开个主席树,支持查询一个区间中有多少个在\([L ...
- 零基础免费搭建个人博客-hexo+github
使用hexo生成静态博客并架设在免费的github page平台 准备 系统: Window 7 64位 使用软件: Git v1.9.5[下载地址] 百度云 360云盘 访问密码 d269 Git官 ...
- 数字签名 转载:http://www.youdzone.com/signature.html
What is a Digital Signature?An introduction to Digital Signatures, by David Youd Bob (Bob's public k ...
- fsLayui缓存使用
概述 缓存主要使用在编辑或查看页面查询数据的方式,通过后端servlet接口获取数据还是通过前端缓存获取.缓存可以使用在实时性要求不高的上面.减少后端servlet请求. 使用步骤 配置支持缓存 需要 ...
- Jquery开发&BootStrap 实现“todolist项目”
作业题目:实现“todolist项目” 作业需求: 基础需求:85%参考链接http://www.todolist.cn/1. 将用户输入添加至待办项2. 可以对todolist进行分类(待办项和已完 ...
- 编译vim8
1.获取最新的vim源码 $ wget https://codeload.github.com/vim/vim/tar.gz/v8.1.2256 2.解压缩 $ tar -xvzf vim-8.1.2 ...
- [Python自学] day-18 (1) (JS正则、第三方组件)
一.JS的正则表达式 JS正则提供了两个方法: test():用于判断字符串是否符合规定: exec():获取匹配的数据: 1.test() 定义一个正则表达式: reg = /\d+/; // 用于 ...