用R语言的quantreg包进行分位数回归
什么是分位数回归
分位数回归(Quantile Regression)是计量经济学的研究前沿方向之一,它利用解释变量的多个分位数(例如四分位、十分位、百分位等)来得到被解释变量的条件分布的相应的分位数方程。
与传统的OLS只得到均值方程相比,分位数回归可以更详细地描述变量的统计分布。它是给定回归变量X,估计响应变量Y条件分位数的一个基本方法;它不仅可以度量回归变量在分布中心的影响,而且还可以度量在分布上尾和下尾的影响,因此较之经典的最小二乘回归具有独特的优势。众所周知,经典的最小二乘回归是针对因变量的均值(期望)的:模型反映了因变量的均值怎样受自变量的影响,
$y=\beta X+\epsilon$,$E(y)=\beta X$
分位数回归的核心思想就是从均值推广到分位数。最小二乘回归的目标是最小化误差平方和,分位数回归也是最小化一个新的目标函数:
$\min_{\xi \in \mathcal{R}} \sum \rho_{\tau}(y_i-\xi)$
quantreg包
quantreg即:Quantile Regression,拥有条件分位数模型的估计和推断方法,包括线性、非线性和非参模型;处理单变量响应的条件分位数方法;处理删失数据的几种方法。此外,还包括基于预期风险损失的投资组合选择方法。
实例
library(quantreg) # 载入quantreg包
data(engel) # 加载quantreg包自带的数据集
分位数回归(tau = 0.5)
fit1 = rq(foodexp ~ income, tau = 0.5, data = engel)
r1 = resid(fit1) # 得到残差序列,并赋值为变量r1
c1 = coef(fit1) # 得到模型的系数,并赋值给变量c1
summary(fit1) # 显示分位数回归的模型和系数
`
Call: rq(formula = foodexp ~ income, tau = 0.5, data = engel)
tau: [1] 0.5
Coefficients:
coefficients lower bd upper bd
(Intercept) 81.48225 53.25915 114.01156
income 0.56018 0.48702 0.60199
`
summary(fit1, se = "boot") # 通过设置参数se,可以得到系数的假设检验
`
Call: rq(formula = foodexp ~ income, tau = 0.5, data = engel)
tau: [1] 0.5
Coefficients:
Value Std. Error t value Pr(>|t|)
(Intercept) 81.48225 27.57092 2.95537 0.00344
income 0.56018 0.03507 15.97392 0.00000
`
分位数回归(tau = 0.5、0.75)
fit1 = rq(foodexp ~ income, tau = 0.5, data = engel)
fit2 = rq(foodexp ~ income, tau = 0.75, data = engel)
模型比较
anova(fit1,fit2) #方差分析
`
Quantile Regression Analysis of Deviance Table
Model: foodexp ~ income
Joint Test of Equality of Slopes: tau in { 0.5 0.75 }
Df Resid Df F value Pr(>F)
1 1 469 12.093 0.0005532 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
`
画图比较分析
plot(engel$foodexp , engel$income,pch=20, col = "#2E8B57",
main = "家庭收入与食品支出的分位数回归",xlab="食品支出",ylab="家庭收入")
lines(fitted(fit1), engel$income,lwd=2, col = "#EEEE00")
lines(fitted(fit2), engel$income,lwd=2, col = "#EE6363")
legend("topright", c("tau=.5","tau=.75"), lty=c(1,1),
col=c("#EEEE00","#EE6363"))
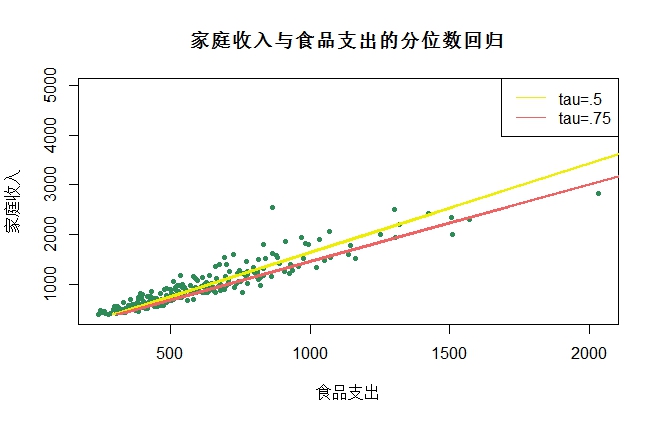
不同分位点的回归比较
fit = rq(foodexp ~ income, tau = c(0.05,0.25,0.5,0.75,0.95), data = engel)
plot( summary(fit))
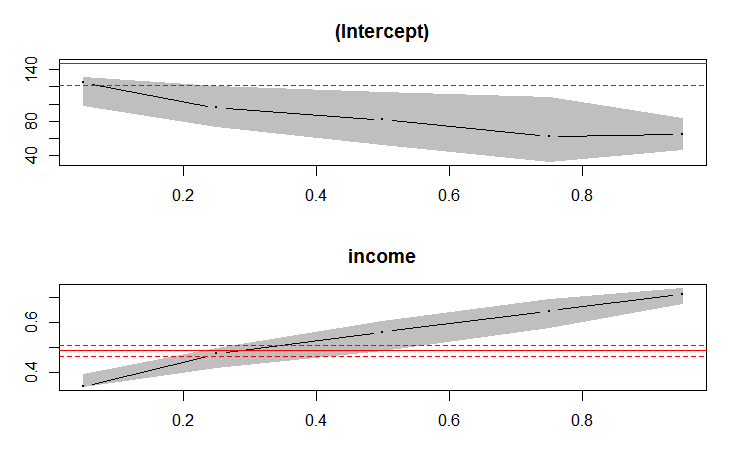
多元分位数回归
data(barro)
fit1 <- rq(y.net ~ lgdp2 + fse2 + gedy2 + Iy2 + gcony2, data = barro,tau=.25)
fit2 <- rq(y.net ~ lgdp2 + fse2 + gedy2 + Iy2 + gcony2, data = barro,tau=.50)
fit3 <- rq(y.net ~ lgdp2 + fse2 + gedy2 + Iy2 + gcony2, data = barro,tau=.75)
# 替代方式 fit <- rq(y.net ~ lgdp2 + fse2 + gedy2 + Iy2 + gcony2, method = "fn", tau = 1:4/5, data = barro)
anova(fit1,fit2,fit3) # 不同分位点模型比较-方差分析
anova(fit1,fit2,fit3,joint=FALSE)
`
Quantile Regression Analysis of Deviance Table
Model: y.net ~ lgdp2 + fse2 + gedy2 + Iy2 + gcony2
Tests of Equality of Distinct Slopes: tau in { 0.25 0.5 0.75 }
Df Resid Df F value Pr(>F)
lgdp2 2 481 1.0656 0.34535
fse2 2 481 2.6398 0.07241 .
gedy2 2 481 0.7862 0.45614
Iy2 2 481 0.0447 0.95632
gcony2 2 481 0.0653 0.93675
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Warning message:
In summary.rq(x, se = se, covariance = TRUE) : 1 non-positive fis
`
不同分位点拟合曲线的比较
plot(barro$y.net,pch=20, col = "#2E8B57",
main = "不同分位点拟合曲线的比较")
lines(fitted(fit1),lwd=2, col = "#FF00FF")
lines(fitted(fit2),lwd=2, col = "#EEEE00")
lines(fitted(fit3),lwd=2, col = "#EE6363")
legend("topright", c("tau=.25","tau=.50","tau=.75"), lty=c(1,1),
col=c( "#FF00FF","#EEEE00","#EE6363"))
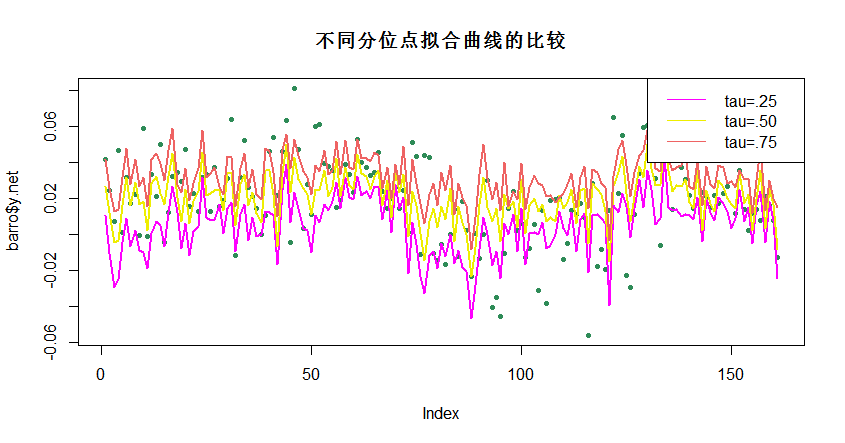
时间序列数据之动态线性分位数回归
library(zoo)
data("AirPassengers", package = "datasets")
ap <- log(AirPassengers)
fm <- dynrq(ap ~ trend(ap) + season(ap), tau = 1:4/5)
`
Dynamic quantile regression "matrix" data:
Start = 1949(1), End = 1960(12)
Call:
dynrq(formula = ap ~ trend(ap) + season(ap), tau = 1:4/5)
Coefficients:
tau= 0.2 tau= 0.4 tau= 0.6 tau= 0.8
(Intercept) 4.680165533 4.72442529 4.756389747 4.763636251
trend(ap) 0.122068032 0.11807467 0.120418846 0.122603451
season(ap)Feb -0.074408403 -0.02589716 -0.006661952 -0.013385535
season(ap)Mar 0.082349382 0.11526821 0.114939193 0.106390507
season(ap)Apr 0.062351869 0.07079315 0.063283042 0.066870808
season(ap)May 0.064763333 0.08453454 0.069344618 0.087566554
season(ap)Jun 0.195099116 0.19998275 0.194786890 0.192013960
season(ap)Jul 0.297796876 0.31034824 0.281698714 0.326054871
season(ap)Aug 0.287624540 0.30491687 0.290142727 0.275755490
season(ap)Sep 0.140938329 0.14399906 0.134373833 0.151793646
season(ap)Oct 0.002821207 0.01175582 0.013443965 0.002691383
season(ap)Nov -0.154101220 -0.12176290 -0.124004759 -0.136538575
season(ap)Dec -0.031548941 -0.01893221 -0.023048200 -0.019458814
Degrees of freedom: 144 total; 131 residual
`
sfm <- summary(fm)
plot(sfm)
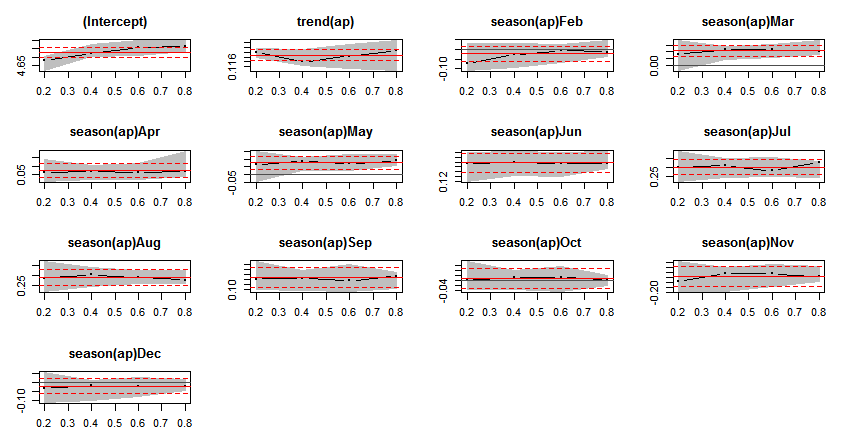
不同分位点拟合曲线的比较
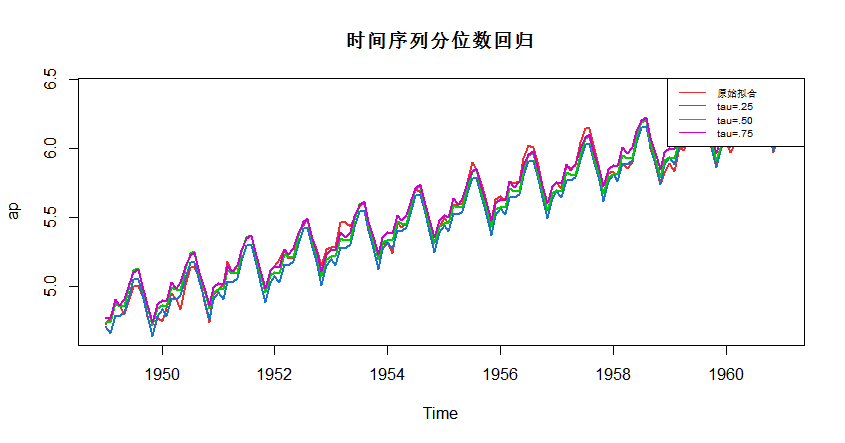
fm1 <- dynrq(ap ~ trend(ap) + season(ap), tau = .25)
fm2 <- dynrq(ap ~ trend(ap) + season(ap), tau = .50)
fm3 <- dynrq(ap ~ trend(ap) + season(ap), tau = .75)
plot(ap,cex = .5,lwd=2, col = "#EE2C2C",main = "时间序列分位数回归")
lines(fitted(fm1),lwd=2, col = "#1874CD")
lines(fitted(fm2),lwd=2, col = "#00CD00")
lines(fitted(fm3),lwd=2, col = "#CD00CD")
legend("topright", c("原始拟合","tau=.25","tau=.50","tau=.75"), lty=c(1,1),
col=c( "#EE2C2C","#1874CD","#00CD00","#CD00CD"),cex = 0.65)
除了本文介绍的以上内容,quantreg包还包含残差形态的检验、非线性分位数回归和半参数和非参数分位数回归等等,详细参见:用R语言进行分位数回归-詹鹏(北京师范大学经济管理学院)和Package ‘quantreg’。
反馈与建议
- 作者:ShangFR
- 邮箱:shangfr@foxmail.com
用R语言的quantreg包进行分位数回归的更多相关文章
- R语言︱H2o深度学习的一些R语言实践——H2o包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言H2o包的几个应用案例 笔者寄语:受启发 ...
- R语言:recommenderlab包的总结与应用案例
R语言:recommenderlab包的总结与应用案例 1. 推荐系统:recommenderlab包整体思路 recommenderlab包提供了一个可以用评分数据和0-1数据来发展和测试推荐算 ...
- 使用R语言的RTCGA包获取TCGA数据--转载
转载生信技能树 https://mp.weixin.qq.com/s/JB_329LCWqo5dY6MLawfEA TCGA数据源 - R包RTCGA的简单介绍 - 首先安装及加载包 - 指定任意基因 ...
- R语言中文分词包jiebaR
R语言中文分词包jiebaR R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到大数据 ...
- R语言中常用包(二)
数据导入 以下R包主要用于数据导入和保存数据 feather:一种快速,轻量级的文件格式.在R和python上都可使用readr:实现表格数据的快速导入.中文介绍可参考这里readxl:读取Micro ...
- R语言︱文本挖掘——jiabaR包与分词向量化的simhash算法(与word2vec简单比较)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- <数据挖掘之道>摘录话语:虽然我比 ...
- R语言 文本挖掘 tm包 使用
#清除内存空间 rm(list=ls()) #导入tm包 library(tm) library(SnowballC) #查看tm包的文档 #vignette("tm") ##1. ...
- R语言使用 multicore 包进行并行计算
R语言是单线程的,如果数据量比较大的情况下最好用并行计算来处理数据,这样会获得运行速度倍数的提升.这里介绍一个基于Unix系统的并行程序包:multicore. 我们用三种不同的方式来进行一个简单的数 ...
- R语言安装xlsx包,读入excel表格
开学的时候,男神给了数据(.xlsx格式)让用R语言分析分析,作为编程小白,读了一天都没读近R,更别提如何分析了. 现在小伙伴们都喜欢读txt 和csv格式的,好多xlsx的表格读不进R,将xlsx格 ...
随机推荐
- TroubleShooting笔记--快照进程sp_replupdateschema和索引重建发生冲突
今天早上服务器出现大面积的阻塞,上去排查blocking,最后大概确定的问题是: rebuild index job(243) --->blocked--->sp_replupdatesc ...
- CLR via C# 学习计划
本书是学习c#的人必读书,计划今年完成,读透. 书是在亚马逊买的,虽然有点小贵,但是为了情怀,咬咬牙买了. 需要学习的: CLR基础 (CH1-CH3) 设计类型 (CH4-CH13) 基本类型 (C ...
- kafka 安装出现的几个问题
1.安装kafka的过程出现两个问题 1)错误: 找不到或无法加载主类 kafka.Kafka 原因: 下载的是源码包,需要编译.可以下载Binary downloads: 2) ERROR I ...
- SSIS 处理NULL
不同于SQL Server中NULL表示值是未知的(Unknown Value),没有数据类型,但是,在SSIS中,NULL是有数据类型的,要获取某一个NULL值,必须指定数据类型,例如,变量 Int ...
- Myeclipse 安装SVN步骤
非在线安装 首先来这儿下载插件 http://subclipse.tigris.org/servlets/ProjectDocumentList?folderID=2240 找个最新的下载 解压到对应 ...
- Android 在Service中弹出对话框
1.在Androidmanifest.xml中插入 <uses-permission android:name="android.permission.SYSTEM_ALERT_WIN ...
- Lua 学习笔记(九)协同程序(线程thread)
协同程序与线程thread差不多,也就是一条执行序列,拥有自己独立的栈.局部变量和命令指针,同时又与其他协同程序共享全局变量和其他大部分东西.从概念上讲线程与协同程序的主要区别在于,一个具有多个线程的 ...
- 原创:从零开始,微信小程序新手入门宝典《一》
为了方便大家了解并入门微信小程序,我将一些可能会需要的知识,列在这里,让大家方便的从零开始学习:一:微信小程序的特点张小龙:张小龙全面阐述小程序,推荐通读此文: 小程序是一种不需要下载.安装即可使用的 ...
- mciSendString 的两个小坑
刚刚修正了自己用的小闹钟的代码. 坑1:REPEAT 选项的作用范围 原来用得好好的,之后选择 .wav 文件,居然不出声音了…… 诶,MCI 肯定支持 .wav 的啊…… 仔细想想,我以前都是选 . ...
- Kooboo CMS 之TextContent详解
TextCotent 在Kooboo.CMS.Content下面,在View中有使用到这个模型层. TextContent继承了ContentBase,而ContentBase是由2个部分类组成的,一 ...