dropout总结
1.伯努利分布:伯努利分布亦称“零一分布”、“两点分布”。称随机变量X有伯努利分布, 参数为p(0<p<1),如果它分别以概率p和1-p取1和0为值。EX= p,DX=p(1-p)。
2.
dropout其实也是一种正则化,因为也把参数变稀疏(l1,原论文)和变小(l2,caffe实际实现)。只有极少的训练样本可用时,Dropout不会很有效。因为Dropout是一个正则化技术,它减少了模 型的有效容量。为了抵消这种影响,我们必须增大模型规模。不出意外的话,使 用Dropout时较佳验证集的误差会低很多,但这是以更大的模型和更多训练算法的迭 代次数为代价换来的。对于非常大的数据集,正则化带来的泛化误差减少得很小。在 这些情况下,使用Dropout和更大模型的计算代价可能超过正则化带来的好处。http://www.dataguru.cn/article-10459-1.html
idea:想利用集成学习bagging的思想,通过训练多个不同的模型来预测结果。但是神经网络参数量巨大,训练和测试网络需要花费大量的时间和内存。
功能:1.解决过拟合
2.加快训练速度
为什么呢work:
1.dropout类似于多模型融合,多模型融合本身能解决解决一下过拟合
因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络(随机删掉一半隐藏神经元导致网络结构已经不同),整个dropout过程就相当于 对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。https://zhuanlan.zhihu.com/p/23178423
2.减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。(这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况)。 迫使网络去学习更加鲁棒的特征 (这些特征在其它的神经元的随机子集中也存在)。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的模式(鲁棒性)。(这个角度看 dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高)https://zhuanlan.zhihu.com/p/23178423
3.正则化。让参数稀疏和让参数变小
4.加噪声。观点十分明确,就是对于每一个dropout后的网络,进行训练时,相当于做了Data Augmentation,因为,总可以找到一个样本,使得在原始的网络上也能达到dropout单元后的效果。 比如,对于某一层,dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被drop的单元,那么总能找到一个样本,使得结果也是如此。这样,每一次dropout其实都相当于增加了样本。https://blog.csdn.net/stdcoutzyx/article/details/49022443
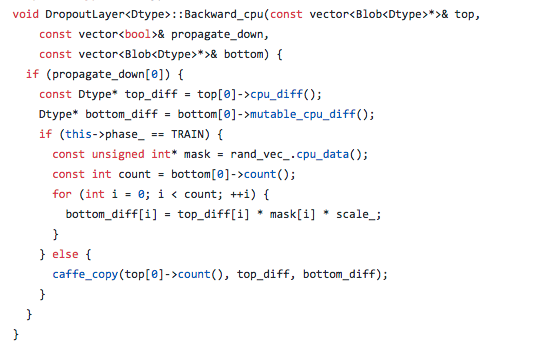
caffe的实现:
论文中的实现:
训练,用伯努利分布生成概率,以概率p打开,概率1-p关闭,打开就是直接把值正常传给下一层,关闭就是不进行正向传播,传给下一层的值是0
测试,用伯努利分布分成概率,将每个权重乘以概率p进行衰减
caffe实现:
训练,用伯努利分布生成概率,以概率p打开,概率1-p关闭。打开的同时要乘以一个系数,相当于把权重放大。关闭还是和论文一样。
测试,直接把上一层的数值传递给下一层,其实也可以直接不用这一层
为什么要这么去实现:
https://blog.csdn.net/u012702874/article/details/45030991解答了为什么要在测试的时候rescale,因为如果直接使用dropout丢弃,其实就是选择了其中的n*p个神经元,所有参数乘以p其实也就是相当于选择了n*p,数量级是至少是一样的
至于caffe为什么要放大,https://stackoverflow.com/questions/50853538/caffe-why-dropout-layer-exists-also-in-deploy-testing这个也没能很好解释,只能说是等效的
前向传播:


反向传播(注意:不进行反向传播,其实只是不求梯度,把上一层的梯度直接传给下一层):
如果进行反向传播,还是以概率p传播梯度,概率1-p不传梯度给下一层,也就是0
如果不进行反向传播,直接把上一层的梯度传给下一层
dropout与bagging的关系:
在Bagging的情况下,所有模型是独立 的。在Dropout的情况下,模型是共享参数的,其中每个模型继承的父神经网络参 数的不同子集。参数共享使得在有限可用的内存下代表指数数量的模型变得可能。 在Bagging的情况下,每一个模型在其相应训练集上训练到收敛。在Dropout的情况下,通常大部分模型都没有显式地被训练,通常该模型很大,以致到宇宙毁灭都不 能采样所有可能的子网络。取而代之的是,可能的子网络的一小部分训练单个步骤,参数共享导致剩余的子网络能有好的参数设定。这些是仅有的区别。除了这些,Dropout与Bagging算法一样。例如,每个子网络中遇到的训练集确实是替换采样的 原始训练集的一个子集。
关于Dropout的一个重要见解是,通过随机行为训练网络并平均多个随机决定进 行预测,通过参数共享实现了Bagging的一种形式。
dropout总结的更多相关文章
- 在RNN中使用Dropout
dropout在前向神经网络中效果很好,但是不能直接用于RNN,因为RNN中的循环会放大噪声,扰乱它自己的学习.那么如何让它适用于RNN,就是只将它应用于一些特定的RNN连接上. LSTM的长期记 ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- 深度学习(dropout)
other_techniques_for_regularization 随手翻译,略作参考,禁止转载 www.cnblogs.com/santian/p/5457412.html Dropout: D ...
- Deep learning:四十一(Dropout简单理解)
前言 训练神经网络模型时,如果训练样本较少,为了防止模型过拟合,Dropout可以作为一种trikc供选择.Dropout是hintion最近2年提出的,源于其文章Improving neural n ...
- 简单理解dropout
dropout是CNN(卷积神经网络)中的一个trick,能防止过拟合. 关于dropout的详细内容,还是看论文原文好了: Hinton, G. E., et al. (2012). "I ...
- [转]理解dropout
理解dropout 原文地址:http://blog.csdn.net/stdcoutzyx/article/details/49022443 理解dropout 注意:图片都在github上 ...
- [CS231n-CNN] Training Neural Networks Part 1 : parameter updates, ensembles, dropout
课程主页:http://cs231n.stanford.edu/ ___________________________________________________________________ ...
- 正则化,数据集扩增,Dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- [Neural Networks] Dropout阅读笔记
多伦多大学Hinton组 http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf 一.目的 降低overfitting的风险 二.原理 ...
随机推荐
- 图像的点运算----底层代码与Halcon库函数
最基本的图像分析工具----灰度直方图.使用直方图辅助,可以实现4大灰度变换,包括线性灰度变换(灰度拉伸).灰度对数变换.灰度伽马变换.灰度分段线性变换:使用直方图修正技术,可以实现2大变换,包括直方 ...
- 阿里云服务器(ECS)购买及配置总结
云服务器是一种简单高效.安全可靠.处理能力可弹性伸缩的计算服务.其管理方式比物理服务器更简单高效.用户无需提前购买硬件,即可迅速创建或释放任意多台云服务器. 目前比较知名的与服务器提供商有:阿里云.百 ...
- Nuxt.js学习心得
一.官网 Nuxt.js - Universal Vue.js Applications https://nuxtjs.org/ 二.中文官网 Nuxt.js - Vue.js 通用应用框架 http ...
- 在 Web 应用中创建 Node.js 应用程序
本分步指南将通过 Azure Web 应用帮助您启动并运行示例 Node.JS 应用程序.除 Node.JS 外,Azure Web 应用还支持其他语言,如 PHP..NET.Node.JS.Pyth ...
- jdk各版本
1.jdk1.7: 1.1二进制变量的表示,支持将整数类型用二进制来表示,用0b开头: 1.2 Switch语句支持string类型: 2.jdk1.8:
- 谷歌在线appspot平台教你学Hacker(由浅如深)-XSS篇
练习链接 http://google-gruyere.appspot.com/ 点开是纯英文的 直接点翻译即可 一 .part1 http://google-gruyere.appspot.com/p ...
- Spring cloud ReadTimeout 问题解决
今天使用Spring cloud @FeignClient 调用远程服务的时候,出现readTimeout问题,通过找资料解决方式如下 在Spring.properties 配置文件中添加如下属性解决 ...
- 中南oj 1215: 稳定排序
1215: 稳定排序 Time Limit: 2 Sec Memory Limit: 128 MB Submit: 111 Solved: 43 [Submit][Status][Web Boar ...
- <head>标签和它的小伙伴们
head标签是HTML文档中最基本的必须元素之一(body:对,还有我): <html> <head> <title>文档的标题</title> < ...
- 1-4 Sass的基本特性-基础
[Sass]声明变量 定义变量的语法: 在有些编程语言中(如,JavaScript)声明变量都是使用关键词“var”开头,但是在 Sass 不使用这个关键词,而是使用大家都喜欢的美元符号“$”开头.我 ...