leetcode28 strstr kmp bm sunday
字符串匹配有KMP,BM,SUNDAY算法。
https://www.cnblogs.com/ZuoAndFutureGirl/p/9028287.html
KMP核心就是next数组(pattern接下来向后移动的位数) (text 当前匹配到的index不变)
模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值
即移动的实际位数为:j - next[j],且此值大于等于1。
操作为
if(text[i]!=p[j])
j=next[j]; // next[j] 即为p[0,j-1]串中最长前后缀长度. p[j]与text[i]失配,但text[X,i-1]与p[0,j-1]匹配,其中最长前后缀也匹配,直接移动pattern,前缀覆盖后缀,比较下一位p[k]与text[i]是否匹配
//p[next[j]] 即为最长前后缀后面一位p[k]
//k为 next[j]. 即p[0,j-1]串最长前后缀的长度
next求法:
next[0]=-1 //若text[i]与pattern第一个字符失配,直接向后移动pattern一位
k =next [j] // j-1串中,最长的前后缀长度为k
if p[j]==p[k] //j串中最长前后缀长度为k+1
next[j + 1] = next[j] + 1
else
k=next[k] //画个图就很好想.
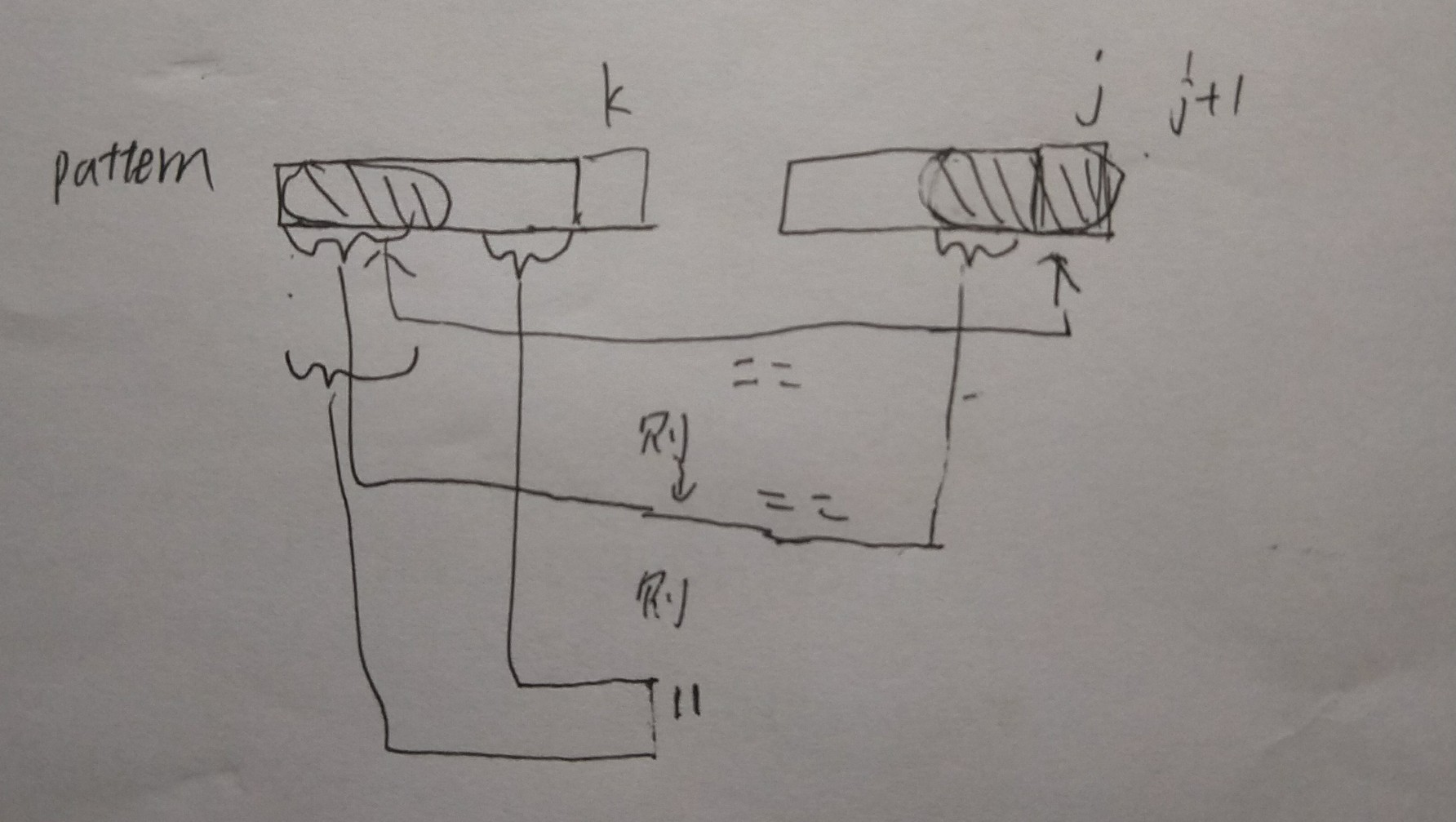
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
}
next优化:
问题出在不该出现p[j] = p[ next[j] ]。
理由是:当p[j] != text[i] 时,下次匹配必然是p[ next [j]] 跟text[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败
(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),
所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ],则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。
//优化过后的next 数组求法
void GetNextval(char* p, int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++j;
++k;
//较之前next数组求法,改动在下面4行
if (p[j] != p[k])
next[j] = k; //之前只有这一行
else
//因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
next[j] = next[k];
}
else
{
k = next[k];
}
}
}
因为比较熟悉KMP,就用KMP了
class Solution {
public:
vector<int> getnext(string str)
{
int len=str.size();
vector<int> next;
next.push_back(-1);//next数组初值为-1
int j=0,k=-1;
while(j<len-1)
{
if(k==-1||str[j]==str[k])//str[j]后缀 str[k]前缀
{
j++;
k++;
if(str[j]!=str[k])
next.push_back(k);
else
next.push_back(next[k]);
}
else
{
k=next[k];
}
}
return next;
}
int strStr(string haystack, string needle) {
if(needle.empty())
return 0;
int i=0;
int j=0;
int len1=haystack.size();
int len2=needle.size();
vector<int> next;
next=getnext(needle);
while((i<len1)&&(j<len2))
{
if((j==-1)||(haystack[i]==needle[j]))
{
i++;
j++;
}
else
{
j=next[j];//获取下一次匹配的位置
}
}
if(j==len2)
return i-j;
return -1;
}
};
然后看题解,有SunDay算法,更好理解(https://leetcode-cn.com/problems/implement-strstr/solution/python3-sundayjie-fa-9996-by-tes/)
偏移表告诉我们下一步可能匹配需要移动的最小步数
设text,patternlen=len
核心思想就是当前匹配若失败,那么当前text中开始匹配的位置i+len-1必不可能匹配上。此时检查i+len处的字符,当其等于pattern中的某个字符(从右向左找),则将pattern移动使text[i+len]与pattern中相应字符对应。
然后重复。
若没有匹配上,那么直接移动len+1
最坏情况:O(nm)
平均情况:O(n)
(实际提交的 时候,确实sunday比kmp快一点。可能是测试用例的关系)
class Solution {
public:
int strStr(string haystack, string needle) {
if(needle.empty())
return 0;
int slen=haystack.size();
int tlen=needle.size();
if(slen<tlen)
return -1;
int i=0,j=0;//i指向源串首位 j指向子串首位
int k;
int m=tlen;//第一次匹配时 源串中参与匹配的元素的下一位
while(i<slen)
{
if(haystack[i]!=needle[j])
{
for(k=tlen-1;k>=0;k--)//遍历查找此时pattern与源串[i+tlen+1]相等的最右位置
{
if(needle[k]==haystack[m])
break;
}
i=m-k;//i为下一次匹配源串开始首位 Sunday算法核心:最大限度跳过相同元素
j=0;//j依然为子串首位
m=i+tlen;//m为下一次参与匹配的源串最后一位元素的下一位
if(m>slen)
return -1;
}
else
{
if(j==tlen-1)//若j为子串末位 匹配成功 返回源串此时匹配首位
return i-j;
i++;
j++;
}
}
return -1;//当超过源串长度时
}
};
还有bm算法 O(N) - O(M+N)
class Solution {
public:
void get_bmB(string& T,vector<int>& bmB)//坏字符
{
int tlen=T.size();
for(int i=0;i<256;i++)//不匹配直接移动子串
{
bmB.push_back(tlen);
}
for(int i=0;i<tlen-1;i++)//靠右原则
{
bmB[T[i]]=tlen-i-1;
}
}
void get_suff(string& T,vector<int>& suff)
{
int tlen=T.size();
int k;
for(int i=tlen-2;i>=0;i--)
{
k=i;
while(k>=0&&T[k]==T[tlen-1-i+k])
k--;
suff[i]=i-k;
}
}
void get_bmG(string& T,vector<int>& bmG)//好后缀
{
int i,j;
int tlen=T.size();
vector<int> suff(tlen+1,0);
get_suff(T,suff);//suff存储子串的最长匹配长度
//初始化 当没有好后缀也没有公共前缀时
for(i=0;i<tlen;i++)
bmG[i]=tlen;
//没有好后缀 有公共前缀 调用suff 但是要右移一位 类似KMP里的next数组
for(i=tlen-1;i>=0;i--)
if(suff[i]==i+1)
for(j=0;j<tlen-1;j++)
if(bmG[j]==tlen)//保证每个位置不会重复修改
bmG[j]=tlen-1-i;
//有好后缀 有公共前缀
for(i=0;i<tlen-1;i++)
bmG[tlen-1-suff[i]]=tlen-1-i;//移动距离
}
int strStr(string haystack, string needle) {
int i=0;
int j=0;
int tlen=needle.size();
int slen=haystack.size();
vector<int> bmG(tlen,0);
vector<int> bmB;
get_bmB(needle,bmB);
get_bmG(needle,bmG);
while(i<=slen-tlen)
{
for(j=tlen-1;j>-1&&haystack[i+j]==needle[j];j--);
if(j==(-1))
return i;
i+=max(bmG[j],bmB[haystack[i+j]]-(tlen-1-j));
}
return -1;
}
};
作者:2227
链接:https://leetcode-cn.com/problems/implement-strstr/solution/c5chong-jie-fa-ku-han-shu-bfkmpbmsunday-by-2227/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
leetcode28 strstr kmp bm sunday的更多相关文章
- 字符串匹配 扩展KMP BM&Sunday
复杂度都是O(n) 扩展1:BM算法 KMP的匹配是从模式串的开头开始匹配的,而1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了一种新的字符串匹 ...
- 第3章:LeetCode--算法:strStr KMP算法
https://leetcode.com/problems/implement-strstr/ 28. Implement strStr() 暴力算法: int ViolentMatch(char* ...
- 字符串匹配算法——BF、KMP、Sunday
一:Brute force 从源串的第一个字符开始扫描,逐一与模式串的对应字符进行匹配,若该组字符匹配,则检测下一组字符,如遇失配,则退回到源串的第二个字符,重复上述步骤,直到整个模式串在源串中找到匹 ...
- BF + KMP + BM 字符串搜索算法
BF #include <stdio.h> #include <string.h> int simplicity(char *s, char *t, int pos); int ...
- 28.Implement strStr()---kmp
题目链接:https://leetcode.com/problems/implement-strstr/description/ 题目大意:字符串匹配,从字符串中,找到给定字符串第一次出现的位置下标, ...
- LeetCode-Implement strStr()-KMP
Implement strStr(). Returns the index of the first occurrence of needle in haystack, or -1 if needle ...
- 28. Implement strStr()(KMP字符串匹配算法)
Implement strStr(). Return the index of the first occurrence of needle in haystack, or -1 if needle ...
- 阮一峰 KMP BM算法
存一个链接,讲得好啊! 点击这里打开 字符串KMP 点击这里打开 字符串匹配的Boyer-Moore算法
- 动画演示Sunday字符串匹配算法——比KMP算法快七倍!极易理解!
前言 上一篇我用动画的方式向大家详细说明了KMP算法(没看过的同学可以回去看看). 这次我依旧采用动画的方式向大家介绍另一个你用一次就会爱上的字符串匹配算法:Sunday算法,希望能收获你的点赞关注收 ...
随机推荐
- 分布式系统:dubbo的连接机制
目录 研究这个问题的起因 dubbo的连接机制 为什么这么做 dubbo同步转异步 dubbo的实现 纯netty的简单实现 总结 研究这个问题的起因 起因是一次面试,一次面试某电商网站,前面问到缓存 ...
- allator 对springBoot进行加密
1.对springboot项目添加jar包和xml文件 allatori.xml: <config> <input> <jar in="target/sprin ...
- Python安装教程之anaconda篇
[导读]我们知道,Python的功能非常强大.那么对于迫切想学习Python的新手同学来说,第一件事情可能需要了解python是什么?能用来做什么?语法结构是怎样的?这些我们几句话很难介绍清楚,后续会 ...
- CentOS系统内核升级(在线 离线)
为什么要升级内核? Docker 在CentOS系统中需要安装在 CentOS 7 64 位的平台,并且内核版本不低于 3.10:CentOS 7.× 满足要求的最低内核版本要求,但由于 CentOS ...
- Object level permissions support
django-guardian (1.1.1+) - Object level permissions support. Home - Django REST framework https://ww ...
- Springboot中mybatis控制台打印sql语句
Springboot中mybatis控制台打印sql语句 https://www.jianshu.com/p/3cfe5f6e9174 https://www.jianshu.com/go-wild? ...
- JVM笔记 -- Java跨平台和JVM跨语言
学习JVM的重要性 从上层应用程序到底层操作系统,到底有哪些东西? 平时开发的应用程序主要基于各种框架,譬如Spring,SpringMVC,Mybatis,而各种框架又是基于Java API来实现的 ...
- MySql(四)SQL注入
MySql(四)SQL注入 一.SQL注入简介 1.1 SQL注入流程 1.2 SQL注入的产生过程 1.2.1 构造动态字符串 转义字符处理不当 类型处理不当 查询语句组装不当 错误处理不当 多个提 ...
- jQuery.qrcode二维码插件生成网页二维码
如果是一个固定的二维码,我们只需要在网上找个地方生成图片,然后放上图片就可以了.但如果是地址不固定需要根据页面来生成的话.就有两种做法,一个是后端根据页面做一个动态的二维码.一种是前端使用插件生成. ...
- 天融信Top-app LB负载均衡SQL注入0day
POST /acc/clsf/report/datasource.php HTTP/1.1 Host: Connection: close Accept: text/javascript, text/ ...