kafka生产者数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后,都需要向 producer 发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
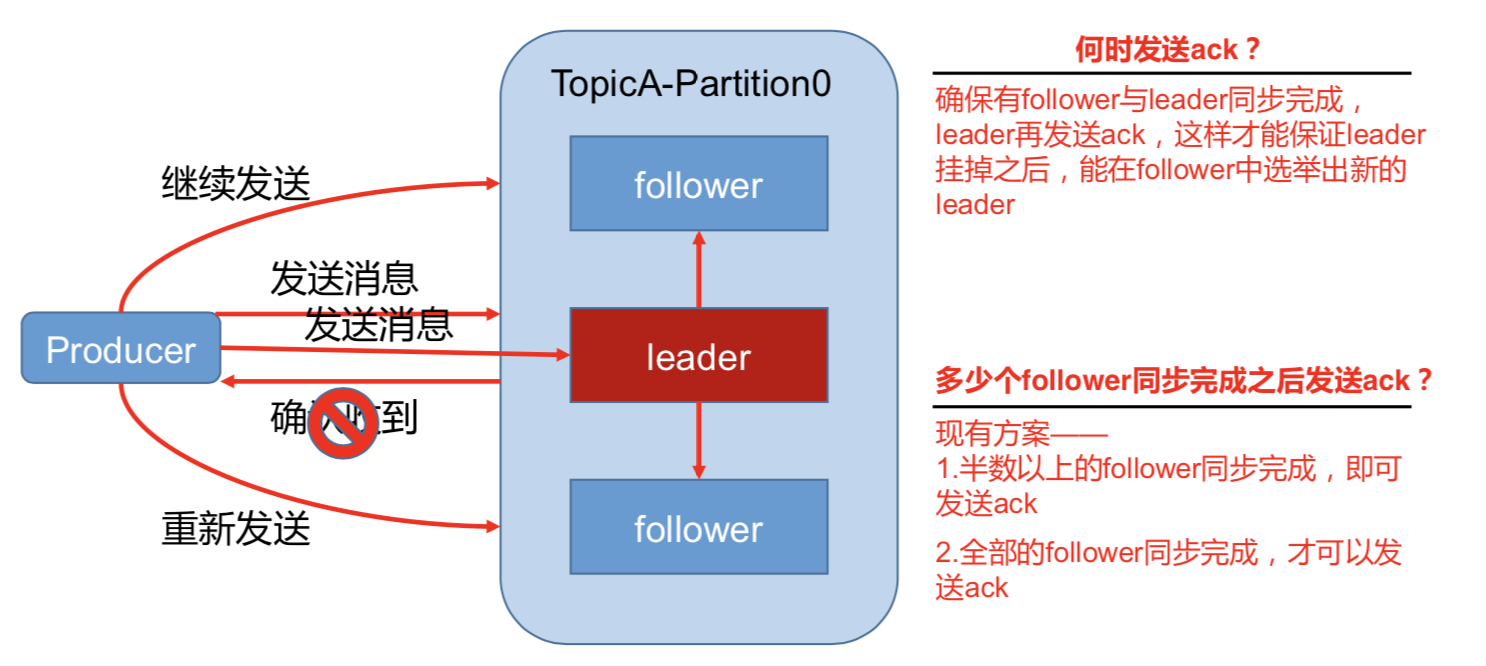
1)副本数据同步策略
|
方案 |
优点 |
缺点 |
|
半数以上完成同步,就发 送 ack |
延迟低 |
选举新的 leader 时,容忍 n 台 节点的故障,需要 2n+1 个副 本(N+1台同步完成) |
|
全部完成同步,才发送 ack |
选举新的 leader 时,容忍 n 台 节点的故障,需要 n+1 个副 本 |
延迟高(N+1台同步完成) |
Kafka 选择了第二种方案,原因如下:
1.同样为了容忍 n 台节点的故障,第一种方案需要 2n+1 个副本,而第二种方案只需要 n+1
个副本,而 Kafka 的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
2.虽然第二种方案的网络延迟会比较高,但网络延迟对 Kafka 的影响较小。
存在的问题:如果有10个副本。有一个挂了,那么永远都不会有ack发送回去。
kafak做了一个优化:

ISR(同步副本):消息条数差值replica.lag.time.max.messages/通信时间长短(同步时间replica.lag.time.max.ms) 两个条件来选副本进ISR, 高版本中不再关注副本的消息条数最大条件。 新版本:如果副本同步时间超过replica.lag.time.max.ms(默认10s),follower就会被移出ISR.
采用第二种方案之后,设想以下情景:leader 收到数据,所有 follower 都开始同步数据, 但有一个 follower,因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去, 直到它完成同步,才能发送 ack。这个问题怎么解决呢?
Leader 维护了一个动态的 in-sync replica set (ISR),意为和 leader 保持同步的 follower 集 合。
当 ISR 中的 follower 完成数据的同步之后,leader 就会给 follower 发送 ack。如果 follower 长时间未向 leader 同步数据,则该 follower 将被踢出 ISR,该时间阈值由
replica.lag.time.max.ms 参数设定。Leader 发生故障之后,就会从 ISR (同步副本)中选举新的 leader。
为何会去掉消息条数差值参数?
因为kafka一般是按batch批量发数据到leader, 如果批量条数12条,replica.lag.time.max.messages参数设置是10条(默认10000条),那么当一个批次消息发到kafka leader,此时,ISR中就要踢掉所有的follower,很快follower同步完所有数据后,follower又要被加入到ISR,频繁操作。
kafka生产者数据可靠性保证的更多相关文章
- Kafka消息delivery可靠性保证(Message Delivery Semantics)
原文见:http://kafka.apache.org/documentation.html#semantics kafka在生产者和消费者之间的传输是如何保证的,我们可以知道有这么几种可能提供的de ...
- kafka如何保证数据可靠性和数据一致性
数据可靠性 Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知.本文从 Producter 往 Broker 发送消息.Topic 分区副本以及 Leader 选举几个角度介绍数据的可靠 ...
- Kafka数据可靠性与一致性解析
Partition Recovery机制 每个Partition会在磁盘记录一个RecoveryPoint, 记录已经flush到磁盘的最大offset.broker fail 重启时,会进行load ...
- kafka学习(三)kafka生产者,消费者详解
文章更新时间:2020/06/14 一.生产者 当我们发送消息之前,先问几个问题:每条消息都是很关键且不能容忍丢失么?偶尔重复消息可以么?我们关注的是消息延迟还是写入消息的吞吐量? 举个例子,有一个信 ...
- Kafka数据可靠性深度解读
原文链接:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由Linked ...
- 【Kafka】Kafka数据可靠性深度解读
转帖:http://www.infoq.com/cn/articles/depth-interpretation-of-kafka-data-reliability Kafka起初是由LinkedIn ...
- kafka数据可靠性深度解读【转】
1 概述 Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cl ...
- Kafka权威指南 读书笔记之(三)Kafka 生产者一一向 Kafka 写入数据
不管是把 Kafka 作为消息队列.消息总线还是数据存储平台来使用 ,总是需要有一个可以往 Kafka 写入数据的生产者和一个从 Kafka 读取数据的消费者,或者一个兼具两种角色的应用程序. 开发者 ...
- Kafka生产者----向kafka写入数据
开发者可以使用kafka内置的客户端API开发kafka应用程序.除了内置的客户端之外,kafka还提供了二进制连接协议,也就是说,我们直接向kafka网络端口发送适当的字节序列,就可以实现从Kafk ...
随机推荐
- Linux系统安装JDK1.8
2020最新Linux系统发行版ContOS7演示安装JDK. 为防止操作权限不足,建议切换root用户,当然如果你对Linux命令熟悉,能够自主完成权限更新操作,可以不考虑此推荐. 更多命令学习推荐 ...
- HTTP 【一文看清所有概念】
HTTP 标头 HTTP 1.1 的标头主要分为四种,通用标头.实体标头.请求标头.响应标头,现在我们来对这几种标头进行介绍 通用标头 HTTP 通用标头之所以这样命名,是因为与其他三个类别不同,它们 ...
- ucore操作系统学习笔记(二) ucore lab2物理内存管理分析
一.lab2物理内存管理介绍 操作系统的一个主要职责是管理硬件资源,并向应用程序提供具有良好抽象的接口来使用这些资源. 而内存作为重要的计算机硬件资源,也必然需要被操作系统统一的管理.最初没有操作系统 ...
- element中过滤器filters的使用(开发小记)
之前在开发过程中遇到这么一个问题,一串数据需要在el-table中展示,其中含有金额字段,需要将其转换成标准数据格式,即三位一个逗号间隔. 今年刚毕业就上手项目了,第一次接触的Vue,开发经验少,也忘 ...
- go语言安装使用
go语言安装使用 下载地址 https://golang.google.cn/dl/ https://studygolang.com/dl windows https://studygolang.co ...
- selenium自动登陆
import osfrom selenium import webdriverimport time,jsonclass Cookie(object): def __init__(self,drive ...
- requests设置代理ip
# coding=utf-8 import requests url = "http://test.yeves.cn/test_header.php" headers = { &q ...
- C# 微支付 JSAPI支付方式 V3.3.6版本
<script type="text/javascript">//结算 (订单号) function PayClearing(num) { $.ajax({ type: ...
- SaaS系统怎么做物流行业年度经营报告,MVC+js+echarts实现
前言 马上就到年底了,很多公司都要汇总这一年的经营情况,如果一个系统没有自动生成年报的功能, 需要人工手工去做年报,我相信可能是一个不小的工作量,最近我通过一个星期的时间,结合系统情况自动生成年报,全 ...
- 开发笔记:PDF生成文字和图片水印
背景 团队手里在做的一个项目,其中一个小功能是用户需要上传PDF文件到文件服务器上,都是一些合同或者技术评估文档,鉴于知识版权和防伪的目的,需要在上传的PDF文件打上水印, 这时候我们需要提供能力给客 ...