《神经网络的梯度推导与代码验证》之vanilla RNN的前向传播和反向梯度推导
在本篇章,我们将专门针对vanilla RNN,也就是所谓的原始RNN这种网络结构进行前向传播介绍和反向梯度推导。更多相关内容请见《神经网络的梯度推导与代码验证》系列介绍。
注意:
- 本系列的关注点主要在反向梯度推导以及代码上的验证,涉及到的前向传播相对而言不会做太详细的介绍。
- 反向梯度求导涉及到矩阵微分和求导的相关知识,请见《神经网络的梯度推导与代码验证》之数学基础篇:矩阵微分与求导
目录
提醒:
- 后续会反复出现$\boldsymbol{\delta}^{l}$这个(类)符号,它的定义为$\boldsymbol{\delta}^{l} = \frac{\partial l}{\partial\boldsymbol{z}^{\boldsymbol{l}}}$,即loss $l$对$\boldsymbol{z}^{\boldsymbol{l}}$的导数
- 其中$\boldsymbol{z}^{\boldsymbol{l}}$表示第$l$层(DNN,CNN,RNN或其他例如max pooling层等)未经过激活函数的输出。
- $\boldsymbol{a}^{\boldsymbol{l}}$则表示$\boldsymbol{z}^{\boldsymbol{l}}$经过激活函数后的输出。
这些符号会贯穿整个系列,还请留意。
4.1 vanilla RNN的前向传播
先贴一张vanilla(朴素)RNN的前传示意图。
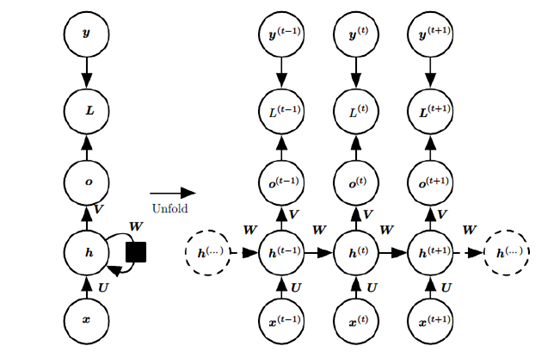
上图中左边是RNN模型没有按时间展开的图,如果按时间序列展开,则是上图中的右边部分。我们重点观察右边部分的图。这幅图描述了在序列索引号t附近RNN的模型。其中:
- $\boldsymbol{x}^{(t)}$代表在序列索引号$t$时训练样本的输入。注意这里的$t$只是代表序列索引,不一定非得具备时间上的含义,例如$\boldsymbol{x}^{(t)}$可以是某句子的第$t$个字(的词向量)。
- $\boldsymbol{h}^{(t)}$代表在序列索引号$t$时模型的隐藏状态。$\boldsymbol{h}^{(t)}$由$\boldsymbol{x}^{(t)}$和$\boldsymbol{h}^{(t-1)}$共同决定
- $\boldsymbol{a}^{(t)}$代表在序列索引号$t$时模型的输出。$\boldsymbol{o}^{(t)}$只由模型当前的隐藏状态$\boldsymbol{h}^{(t-1)}$决定
- $\boldsymbol{L}^{(t)}$代表在序列索引号$t$时模型的损失函数。
- $\boldsymbol{y}^{(t)}$代表在序列索引号$t$时训练样本序列的真实输出
- $\boldsymbol{U},\boldsymbol{W},\boldsymbol{V}$三个矩阵式我们模型的线性相关系数,它们在整个vanilla RNN网络中共享的,这点和DNN很不同。也正因为是共享的,它体现了RNN模型的“循环/递归”的核心思想。
4.1.1 RNN前向传播计算公式
有了上面的模型,RNN的前向传播算法就很容易得到了。
对于任意一个序列索引号$t$,我们隐藏状态$\boldsymbol{h}^{(t)}$由$\boldsymbol{x}^{(t)}$和$\boldsymbol{h}^{(t-1)}$共同得到:
$\boldsymbol{h}^{(t)} = \sigma\left( \boldsymbol{z}^{(t)} \right) = \sigma\left( {\boldsymbol{U}\boldsymbol{x}^{(t)} + \boldsymbol{W}\boldsymbol{h}^{(t - 1)} + \boldsymbol{b}} \right)$
其中$\sigma$为RNN的激活函数,一般为$tanh$。
序列索引号为$t$时,模型的输出$\boldsymbol{o}^{(t)}$的表达式也比较简单:
$\boldsymbol{o}^{(t)} = \boldsymbol{V}\boldsymbol{h}^{(t - 1)} + \boldsymbol{c}$
在最终在序列索引号t
时我们的预测输出为:
${\hat{\boldsymbol{y}}}^{(t)} = \sigma\left( \boldsymbol{o}^{(t)} \right)$
对比下列公式:
$\boldsymbol{h}^{(t)} = \sigma\left( {\boldsymbol{U}\boldsymbol{x}^{(t)} + \boldsymbol{W}\boldsymbol{h}^{(t - 1)} + \boldsymbol{b}} \right)$
$\boldsymbol{a}^{l} = \sigma\left( {\boldsymbol{W}^{l}\boldsymbol{a}^{l - 1} + \boldsymbol{b}^{l}} \right)$
上面的是vanilla RNN的$\boldsymbol{h}^{(t)}$的递推公式,而下面的是DNN中的层间关系的公式。我们可以发现这两组公式在形式上非常接近。如果将$\boldsymbol{h}^{(t)}$的这种时间上的展开看成类似于DNN这种层间堆叠的话,可以发现vanilla RNN每一“层”除了有来自上一“层”的输入$\boldsymbol{h}^{(t - 1)}$,还有专属于这一层的输入$\boldsymbol{x}^{(t)}$,最重要的是,每一“层”的参数$\boldsymbol{W}$和$\boldsymbol{b}$都是同一组。而DNN则是有专属于那一层的$\boldsymbol{W}^{l}$和$\boldsymbol{b}^{l}$。
4.2 vanilla RNN的反向梯度推导
RNN反向传播算法的思路和DNN是一样的,即通过梯度下降法一轮轮的迭代,得到合适的RNN模型参数$\boldsymbol{U},\boldsymbol{W},\boldsymbol{V},\boldsymbol{b},\boldsymbol{c}$。由于我们是基于时间反向传播,所以RNN的反向传播有时也叫做BPTT(back-propagation through
time)。当然这里的BPTT和DNN也有很大的不同点,即这里所有的$\boldsymbol{U},\boldsymbol{W},\boldsymbol{V},\boldsymbol{b},\boldsymbol{c}$在序列的各个位置是共享的,反向传播时我们更新的是相同的参数。
为了简化描述,这里的损失函数我们为交叉熵损失函数,输出的激活函数为softmax函数,隐藏层的激活函数为tanh函数。
如果RNN在序列t
的每个位置有输出,则最终的损失L为所有时间步$t$的loss之和:
$L = {\sum\limits_{t = 1}^{T}L^{(t)}}$
其中,$\boldsymbol{V},\boldsymbol{c}$的梯度计算比较简单,跟求DNN的BP是一样的。
根据 数学基础篇:矩阵微分与求导 1.8节例子的中间结果,我们可以知道:
$\frac{\partial L}{\partial\boldsymbol{c}} = {\sum\limits_{t = 1}^{T}\frac{\partial L^{(t)}}{\partial\boldsymbol{c}}} = {\sum\limits_{t = 1}^{T}{{\hat{\boldsymbol{y}}}^{(t)} - \boldsymbol{y}^{(t)}}}$
$\frac{\partial L}{\partial\boldsymbol{V}} = {\sum\limits_{t = 1}^{T}\frac{\partial L^{(t)}}{\partial\boldsymbol{V}}} = {\sum\limits_{t = 1}^{T}\left( {{\hat{\boldsymbol{y}}}^{(t)} - \boldsymbol{y}^{(t)}} \right)}\left( \boldsymbol{h}^{(t)} \right)^{T}$
接下来的$\boldsymbol{U},\boldsymbol{W},\boldsymbol{b}$的梯度计算就相对复杂了。从RNN的模型可以看出,在反向传播时,某一序列位置$t$的梯度由当前位置的输出对应的梯度和序列索引位置$t+1$时的梯度两部分共同决定。对于$\boldsymbol{W}$在某一序列位置$t$的梯度损失需要反向传播一步一步地计算。我们定义序列索引$t$位置的隐藏状态的梯度为:
$\boldsymbol{\delta}^{(t)} = \frac{\partial L}{\partial\boldsymbol{h}^{(t)}}$
如果我们能知道$\boldsymbol{\delta}^{(t)}$,那么根据$\boldsymbol{h}^{(t)} = \sigma\left( \boldsymbol{z}^{(t)} \right) = \sigma\left( {\boldsymbol{U}\boldsymbol{x}^{(t)} + \boldsymbol{W}\boldsymbol{h}^{(t - 1)} + \boldsymbol{b}} \right)$我们就像DNN那样套用标量对矩阵的链式求导法则来进一步得到$\boldsymbol{U},\boldsymbol{W},\boldsymbol{b}$的梯度了。
根据4.1节中的示意图我们可以轻易发现,当$t = T$,则误差只有$\left. L^{(T)}\rightarrow\boldsymbol{h}^{(T)} \right.$这么一条。
所以:
$\boldsymbol{\delta}^{(T)} = \boldsymbol{V}^{T}\left( {{\hat{\boldsymbol{y}}}^{(T)} - \boldsymbol{y}^{(T)}} \right)$
而当$t<T$时,$\boldsymbol{h}^{(t)}$的误差来源有两条:
1)$\left. L^{(t)}\rightarrow\boldsymbol{h}^{(t)} \right.$
2)$\left. \boldsymbol{h}^{({t + 1})}\rightarrow\boldsymbol{h}^{(t)} \right.$
于是我们得到:
$\boldsymbol{\delta}^{(t)} = \frac{\partial L^{(t)}}{\partial\boldsymbol{h}^{(t)}} + \left( \frac{\partial\boldsymbol{h}^{(t + 1)}}{\partial\boldsymbol{h}^{(t)}} \right)^{T}\frac{\partial L}{\partial\boldsymbol{h}^{(t + 1)}}$
我们来逐项求解:
首先对于$\frac{\partial L^{(t)}}{\partial\boldsymbol{h}^{(t)}}$:
$\boldsymbol{\delta}^{(t)} = \frac{\partial L}{\partial\boldsymbol{h}^{(t)}} = \left( \frac{\partial\boldsymbol{o}^{(t)}}{\partial\boldsymbol{h}^{(t)}} \right)^{T}\frac{\partial L}{\partial\boldsymbol{o}^{(t)}} = \boldsymbol{V}^{T}\left( {{\hat{\boldsymbol{y}}}^{(t)} - \boldsymbol{y}^{(t)}} \right)$
对于$\left( \frac{\partial\boldsymbol{h}^{(t + 1)}}{\partial\boldsymbol{h}^{(t)}} \right)^{T}\frac{\partial L^{({t + 1})}}{\partial\boldsymbol{h}^{(t + 1)}}$,我们先关注$\frac{\partial\boldsymbol{h}^{(t + 1)}}{\partial\boldsymbol{h}^{(t)}}$:
因为$\boldsymbol{h}^{(t + 1)} = \sigma\left( \boldsymbol{z}^{(t)} \right) = \sigma\left( {\boldsymbol{U}\boldsymbol{x}^{(t + 1)} + \boldsymbol{W}\boldsymbol{h}^{(t)} + \boldsymbol{b}} \right)$
所以有:
$d\boldsymbol{h}^{(t + 1)} = \sigma^{'}\left( \boldsymbol{h}^{(t + 1)} \right)\bigodot d\boldsymbol{z}^{(t)} = diag\left( {\sigma^{'}\left( \boldsymbol{h}^{({t + 1})} \right)} \right)d\boldsymbol{z}^{(t)} = diag\left( {\sigma^{'}\left( \boldsymbol{h}^{({t + 1})} \right)} \right)d\left( {\boldsymbol{W}\boldsymbol{h}^{(t)}} \right) = diag\left( {\sigma^{'}\left( \boldsymbol{h}^{({t + 1})} \right)} \right)\boldsymbol{W}d\boldsymbol{h}^{(t)}$
所以有:$\frac{\partial\boldsymbol{h}^{(t + 1)}}{\partial\boldsymbol{h}^{(t)}} = diag\left( {\sigma^{'}\left( \boldsymbol{h}^{({t + 1})} \right)} \right)\boldsymbol{W}$
于是:
$\boldsymbol{\delta}^{(t)} = \boldsymbol{V}^{T}\left( {{\hat{\boldsymbol{y}}}^{(t)} - \boldsymbol{y}^{(t)}} \right) + \boldsymbol{W}^{T}diag\left( {\sigma^{'}\left( \boldsymbol{h}^{(t + 1)} \right)} \right)\boldsymbol{\delta}^{(t + 1)}$
有了$\boldsymbol{\delta}^{(T)}$以及从$\boldsymbol{\delta}^{(t + 1)}$到$\boldsymbol{\delta}^{(t)}$的递推公式,我们可以轻易求出$\boldsymbol{U},\boldsymbol{W},\boldsymbol{b}$的梯度,由于这三组变量在不同的$t$下是公用的,所以由全微分方程可知,这三个变量应当都是在$t$上的某种累加形式。我们定义只在时间步$t$使用的虚拟变量$\boldsymbol{U}^{(t)},\boldsymbol{W}^{(t)},\boldsymbol{b}^{(t)}$,这样就可以用$\frac{\partial L}{\partial\boldsymbol{W}^{(t)}}$来表示$\boldsymbol{W}$在时间步$t$的时候对梯度的贡献:
$\frac{\partial L}{\partial\boldsymbol{W}} = {\sum\limits_{t = 1}^{T}\frac{\partial L}{\partial\boldsymbol{W}^{(t)}}} = {\sum\limits_{t = 1}^{T}{\left( \frac{\partial\boldsymbol{h}^{(t)}}{\partial\boldsymbol{W}^{(t)}} \right)^{T}\frac{\partial L}{\partial\boldsymbol{h}^{(t)}} =}}{\sum\limits_{t = 1}^{T}{diag\left( {\sigma^{'}\left( \boldsymbol{h}^{(t + 1)} \right)} \right)\boldsymbol{\delta}^{(t)}\left( \boldsymbol{h}^{(t - 1)} \right)^{T}}}$
同理,我们得到:
$\frac{\partial L}{\partial\boldsymbol{b}} = {\sum\limits_{t = 1}^{T}{\frac{\partial L}{\partial\boldsymbol{b}^{(t)}} =}}{\sum\limits_{t = 1}^{T}{\left( \frac{\partial\boldsymbol{h}^{(t)}}{\partial\boldsymbol{b}^{(t)}} \right)^{T}\frac{\partial L}{\partial\boldsymbol{h}^{(t)}} = {\sum\limits_{t = 1}^{T}{diag\left( {\sigma^{'}\left( \boldsymbol{h}^{(t + 1)} \right)} \right)\boldsymbol{\delta}^{(t)}}}}}$
$\frac{\partial L}{\partial\boldsymbol{U}} = {\sum\limits_{t = 1}^{T}{\frac{\partial L}{\partial\boldsymbol{U}^{(t)}} =}}{\sum\limits_{t = 1}^{T}{\left( \frac{\partial\boldsymbol{h}^{(t)}}{\partial\boldsymbol{U}^{(t)}} \right)^{T}\frac{\partial L}{\partial\boldsymbol{h}^{(t)}} = {\sum\limits_{t = 1}^{T}{diag\left( {\sigma^{'}\left( \boldsymbol{h}^{(t + 1)} \right)} \right)\boldsymbol{\delta}^{(t)}\left( \boldsymbol{x}^{(t)} \right)^{T}}}}}$
4.3 RNN发生梯度消失与梯度爆炸的原因分析
上一节我们得到了从$\boldsymbol{h}^{(t + 1)}$到$\boldsymbol{h}^{(t)}$的递推公式:
$\frac{\partial\boldsymbol{h}^{(t + 1)}}{\partial\boldsymbol{h}^{(t)}} = diag\left( {\sigma^{'}\left( \boldsymbol{h}^{({t + 1})} \right)} \right)\boldsymbol{W}$
在求$\boldsymbol{h}^{(t)}$的时候,我们需要从$\boldsymbol{h}^{(T)}$开始根据上面这个公式一步一步推到$\boldsymbol{h}^{(t)}$,可以想象$\boldsymbol{W}$在这期间会被疯狂地连乘。当我们要求某个时间步$t$下的$\frac{\partial L}{\partial\boldsymbol{W}^{(t)}}$时,这一堆连乘的$\boldsymbol{W}$也会被带上。结果就是(粗略地分析),如果$\boldsymbol{W}$里的值都比较大,就会发生梯度爆炸,反之则发生梯度消失。
参考资料
- 书籍:《Deep Learning》(深度学习)
(欢迎转载,转载请注明出处。欢迎留言或沟通交流: lxwalyw@gmail.com)
《神经网络的梯度推导与代码验证》之vanilla RNN的前向传播和反向梯度推导的更多相关文章
- 《神经网络的梯度推导与代码验证》之LSTM的前向传播和反向梯度推导
前言 在本篇章,我们将专门针对LSTM这种网络结构进行前向传播介绍和反向梯度推导. 关于LSTM的梯度推导,这一块确实挺不好掌握,原因有: 一些经典的deep learning 教程,例如花书缺乏相关 ...
- 《神经网络的梯度推导与代码验证》之CNN的前向传播和反向梯度推导
在FNN(DNN)的前向传播,反向梯度推导以及代码验证中,我们不仅总结了FNN(DNN)这种神经网络结构的前向传播和反向梯度求导公式,还通过tensorflow的自动求微分工具验证了其准确性.在本篇章 ...
- 《神经网络的梯度推导与代码验证》之CNN前向和反向传播过程的代码验证
在<神经网络的梯度推导与代码验证>之CNN的前向传播和反向梯度推导 中,我们学习了CNN的前向传播和反向梯度求导,但知识仍停留在纸面.本篇章将基于深度学习框架tensorflow验证我们所 ...
- 《神经网络的梯度推导与代码验证》之vanilla RNN前向和反向传播的代码验证
在<神经网络的梯度推导与代码验证>之vanilla RNN的前向传播和反向梯度推导中,我们学习了vanilla RNN的前向传播和反向梯度求导,但知识仍停留在纸面.本篇章将基于深度学习框架 ...
- 《神经网络的梯度推导与代码验证》之FNN(DNN)前向和反向过程的代码验证
在<神经网络的梯度推导与代码验证>之FNN(DNN)的前向传播和反向梯度推导中,我们学习了FNN(DNN)的前向传播和反向梯度求导,但知识仍停留在纸面.本篇章将基于深度学习框架tensor ...
- 《神经网络的梯度推导与代码验证》之FNN(DNN)的前向传播和反向推导
在<神经网络的梯度推导与代码验证>之数学基础篇:矩阵微分与求导中,我们总结了一些用于推导神经网络反向梯度求导的重要的数学技巧.此外,通过一个简单的demo,我们初步了解了使用矩阵求导来批量 ...
- [图解tensorflow源码] MatMul 矩阵乘积运算 (前向计算,反向梯度计算)
- [tensorflow源码分析] Conv2d卷积运算 (前向计算,反向梯度计算)
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
随机推荐
- 新浪、腾讯、淘宝为何如此重视Web前端?前端入门容易吗?
为什么新浪.搜狐.网易.腾讯.淘宝等在内的各种规模的IT企业,都对web前端越来越重视了呢?小编为您揭晓答案! web前端的由来 以前会Photoshop和Dreamweaver就可以制作网页.随着时 ...
- Docker 搭建 SonarQube
Docker 搭建 SonarQube Docker 搭建 SonarQube 步骤 创建项目目录 mkdir -p /usr/local/sonarqube && cd /usr/l ...
- 新司机的致胜法宝,使用ApexSql Log2018快速恢复数据库被删除的数据
作为开发人员,误操作数据delete.update.insert是最正常不过的了,比如: 删除忘记加where条件: 查询为了图方便按了F5,但是数据里面夹杂着delete语句. 不管是打着后发动机声 ...
- 来自灵魂的拷问——知道什么是SQL执行计划吗?
面试官说:工作这么久了,应该知道sql执行计划吧,讲讲Sql的执行计划吧! 看了看面试官手臂上纹的大花臂和一串看不懂的韩文,吞了吞口水,暗示自己镇定点,整理了一下思绪缓缓的对面试官说:我不会 面试官: ...
- Visual Studio安装
2017 安装的时候,一直显示,安装成功但是有告警. 解决方法: 将visual studio 2017 installer进行卸载,然后安装hw的ios 不能确保下次也可以成功
- LeetCode 64最小路径和
题目 给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小. 说明:每次只能向下或者向右移动一步. 示例: 输入: [ [1,3,1], [1,5 ...
- 配置 Eureka Server 集群
简介 为了使 Eureka Server 实现高可用,我们需要为它配置集群.这样当有一台 Eureka Server 有故障时,集群中的其他 Server 可以进行代替.Eureka 集群之中的 No ...
- 【NOI2015】荷马史诗 - 哈夫曼树
题目描述 追逐影子的人,自己就是影子 ——荷马 Allison 最近迷上了文学.她喜欢在一个慵懒的午后,细细地品上一杯卡布奇诺,静静地阅读她爱不释手的<荷马史诗>.但是由<奥德赛&g ...
- 为什么?为什么?Java处理排序后的数组比没有排序的快?想过没有?
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个有颜值却假装靠才华苟且的程序员.本文 GitHub github.com/itwanger 已收录,里面还有我精心为你准备的一线大厂面试题 ...
- HMM隐马尔可夫模型来龙去脉(一)
目录 隐马尔可夫模型HMM学习导航 一.认识贝叶斯网络 1.概念原理介绍 2.举例解析 二.马尔可夫模型 1.概念原理介绍 2.举例解析 三.隐马尔可夫模型 1.概念原理介绍 2.举例解析 四.隐马尔 ...