pytorch——预测值转换为概率,单层感知机
softmax函数,可以将算出来的预测值转换成0-1之间的概率形式

导数的形式

import torch
import torch.nn.functional as F
x=torch.tensor([3.3,2.2,1.0])
x.requires_grad_()
y=F.softmax(x,dim=0)
print('将x转换成概率型的y',y)
print(y[0],x[0])
print('对y1进行求导,由于y是由所有xi来生成的,所以传输入的时候要把所有的x传进去')
#由于y=0.6978,0.2323,0.07. 所以有导数公式dy1/dx1=0.6978*(1-0.6978)=0.2109 dy1/dx2=-0.6978*0.2323=-0.162
print('y0对上x0-x3三个方向上的导数',torch.autograd.grad(outputs=y[0], inputs=x))
y=F.softmax(x,dim=0)
print('y1对上x0-x3三个方向上的导数',torch.autograd.grad(outputs=y[1], inputs=x))
y=F.softmax(x,dim=0)
print('y2对上x0-x3三个方向上的导数',torch.autograd.grad(outputs=y[2], inputs=x))
单层感知机
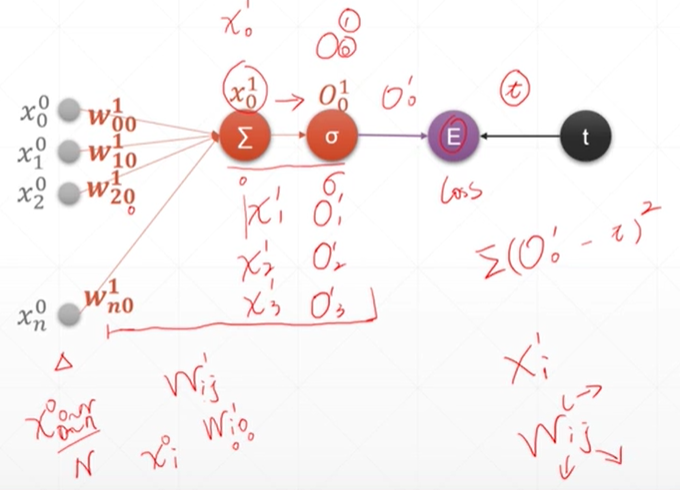
x的上标代表层数,下面的下标代表的是节点的编号。w的上标是下一层,下标的第一位是上一层的节点的编号,第二位是上一层
第0层的n个节点通过权值相乘再累加得到下一层的x,然后x通过激活函数再计算损失

pytorch——预测值转换为概率,单层感知机的更多相关文章
- 单层感知机_线性神经网络_BP神经网络
单层感知机 单层感知机基础总结很详细的博客 关于单层感知机的视频 最终y=t,说明经过训练预测值和真实值一致.下面图是sign函数 根据感知机规则实现的上述题目的代码 import numpy as ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- TensorFlow单层感知机实现
TensorFlow单层感知机实现 简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,只能解决线性可分的问题.虽然限制了单层感知机只能应用于线性可分 ...
- 动手学习pytorch——(3)多层感知机
多层感知机(multi perceptron,MLP).对于普通的含隐藏层的感知机,由于其全连接层只是对数据做了仿射变换,而多个仿射变换的叠加仍然是一个仿射变换,即使添加更多的隐藏层,这种设计也只能与 ...
- 非学习型单层感知机的java实现(日志三)
要求如下: 所以当神经元输出函数选择在硬极函数的时候,如果想分成上面的四个类型,则必须要2个神经元,其实至于所有的分类问题,n个神经元则可以分成2的n次方类型. 又前一节所证明出来的关系有: 从而算出 ...
- Matlab实现单层感知机网络识别字母
感知机网络的参数设置 % 具体用法: % net=newp(pr,T,TF,LF); % % pr: pr是一个R×2的矩阵,R为感知器中输入向量的维度(本例中使用35个字符表征一个字母,那么其维度为 ...
- 从头学pytorch(五) 多层感知机及其实现
多层感知机 上图所示的多层感知机中,输入和输出个数分别为4和3,中间的隐藏层中包含了5个隐藏单元(hidden unit).由于输入层不涉及计算,图3.3中的多层感知机的层数为2.由图3.3可见,隐藏 ...
- 深度学习:多层感知机和异或问题(Pytorch实现)
感知机模型 假设输入空间\(\mathcal{X}\subseteq \textbf{R}^n\),输出空间是\(\mathcal{Y}=\{-1,+1\}\).输入\(\textbf{x}\in \ ...
- 深度学习原理与框架-Tensorflow基本操作-mnist数据集的逻辑回归 1.tf.matmul(点乘操作) 2.tf.equal(对应位置是否相等) 3.tf.cast(将布尔类型转换为数值类型) 4.tf.argmax(返回最大值的索引) 5.tf.nn.softmax(计算softmax概率值) 6.tf.train.GradientDescentOptimizer(损失值梯度下降器)
1. tf.matmul(X, w) # 进行点乘操作 参数说明:X,w都表示输入的数据, 2.tf.equal(x, y) # 比较两个数据对应位置的数是否相等,返回值为True,或者False 参 ...
随机推荐
- CTF练习②
参考的文章链接 :https://www.cnblogs.com/chrysanthemum/p/11657008.html 这个题是强网杯的一道SQL注入的题,网上有不少的在线靶场和writeup, ...
- 第三章 Nacos Discovery--服务治理
之前我讲过 Nacos文章 的内容,想要深入了解的 朋友的话,可以去看看 ,我们继续承接上篇讲下去 --> 第二章 : 微服务环境搭建 3.1 服务治理介绍 先来思考一个问题 通过上一章的操作, ...
- C# 中 ConcurrentDictionary 一定线程安全吗?
根据 .NET 官方文档的定义:ConcurrentDictionary<TKey,TValue> Class 表示可由多个线程同时访问的线程安全的键/值对集合.这也是我们在并发任务中比较 ...
- Latex向上\向下取整语法 及卷积特征图高宽计算公式编辑
向下\向上取整 在编辑卷积网络输出特征高宽公式时,需用到向下取整,Mark一下. 向下取整 \(\lfloor x \rfloor\) $\lfloor x \rfloor$ 向上取整 \(\lcei ...
- BST和DST简单的matlab程序(图的广度和深度遍历)
图的广度和深度遍历,具体内容教材有 clc;clear all;close all; %初始化邻接压缩表compressTable=[1 2;1 3;1 4;2 4;2 5;3 6;4 6;4 7]; ...
- 在wildfly 21中搭建cluster集群
目录 简介 下载软件和相关组件 配置domain 创建应用程序 部署应用程序 集群配置 总结 简介 wildfly是一个非常强大的工具,我们可以轻松的使用wildfly部署应用程序,更为强大的是,wi ...
- 入门oj 6492: 小B的询问
Description 小B有一个序列,包含N个1~K之间的整数.他一共有M个询问,每个询问给定一个区间[L..R],求Sigma(c(i)^2)的值,其中i的值从1到K,其中c(i)表示数字i在[L ...
- Kubernetes官方java客户端之二:序列化和反序列化问题
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Redis性能篇(二)CPU核和NUMA架构的影响
Redis被广泛使用的一个很重要的原因是它的高性能.因此我们必要要重视所有可能影响Redis性能的因素.机制以及应对方案.影响Redis性能的五大方面的潜在因素,分别是: Redis内部的阻塞式操作 ...
- jQuery中toggle与slideToggle以及fadeToggle的显示、隐藏方法的比较
1.区别 ①动画效果的比较: toggle:直接显示.隐藏,如果有[时间参数]且[匹配的元素有宽度属性],则动态效果为左上角-右下角拉卷效果,透明度0-1之间的变化:若有时间参数但是[匹配的元素没有宽 ...