hystrix文档翻译之工作原理
流程图
下面的图片显示了一个请求在hystrix中的流程图。

1.构造一个HystrixCommand或者HystrixObservableCommand对象
第一步是创建一个HystrixCommand或者HystrixObservableCommand对象来执行依赖请求。创建时需要传递相应的参数。
如果请求只返回一个单一值,使用HystrixCommand。
HystrixCommand command = new HystrixCommand(arg1, arg2);
如果希望返回一个Observable来监听多个值,使用HystrixObservableCommand。
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2.执行命令
有四种方法来执行命令(前面两种只对HystrixCommand有用,HystrixObservableCommand没有相应的方法)。
- execute-阻塞,阻塞直到收到调用的返回值(或者抛出异常)
- queue 返回一个future,可以通过future来获取调用的返回值。
- observe 监听一个调用返回的Observable对象。
- toObservable 返回一个Observable,当监听该Observable后hystrix命令将会执行并返回结果。
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe(); //hot observable
Observable<K> ocValue = command.toObservable(); //cold observab
同步调用execute本质是调用了queue().get().queue() ,而queue本质上调用了toObservable().toBlocking().toFuture().本质上都是通过rxjava的Observable实现。
3.是否使用缓存
如果开启缓存,请求首先会返回缓存中的结果。
4.是否开启熔断
当运行hystrix命令时,会判断是否熔断,如果已经熔断,hystrix将不会执行命令,而是直接执行fallback。等熔断关闭了,在执行命令。
5.线程/队列/信号量是否已满
如果线程或队列(非线程池模式下是信号量)已满,将不会执行命令,而是直接执行fallback。
6.HystrixObservableCommand.construct() or HystrixCommand.run()
hystrix通过一下两种方式来调用依赖:
HystrixObservableCommand.construct() :返回一个Observable,发射多个值。
HystrixCommand.run():返回一个单一值,或抛异常。
如果HystrixCommand.run()或HystrixObservableCommand.construct() 发送超时,则执行的相应线程将会抛出TimeoutException的异常。然后执行fallback流程。并且丢弃run或construst的返回值。
注意,hystrix没有办法强制停止线程执行,hysrix能做的最好方式是抛出InterruptedException。如果hystrix执行的方法没有相应InterruptedException,那么它会继续执行,但是用户的已经收到TimeoutException异常。大多是的http client不回响应InterruptedException,确保正确配置了链接的timeout时间。
如果执行方法成功,hystrix会记录日志、上报metrics,然后返回执行结果。
7.熔断器计算
hystrix在成功、失败、拒绝、timeout时会上报到熔断器模块,熔断器会计算当前的熔断状态。熔断器使用一个状态来表示当前是否被熔断,一旦熔断所有的请求将不回执行命令直到熔断恢复。
8.执行fallback
当命令执行失败时,hystrix会执行fallback:当run或construct方法抛出异常;当熔断器被熔断;当线程池/队列/信号量使用完;当timeout。
通过fallback可以优雅降级,通过静态逻辑返回一个结果。如果你想要在fallback中执行依赖调用,那么必须把这个依赖封装成一个HystrixCommand或者HystrixObservableCommand。HystrixCommand中通过fallback方法来返回一个单一值,HystrixObservableCommand通过resumeWithFallback来返回一个 Observable来返回一个或多个值。hystrix将会把返回值返回给调用方。
如果不实现fallback方法,或者执行fallback方法抛出异常,hystrix仍然会返回一个Observable,但该Observable不会发射数据,而是直接执行error。通过onerror通知,告诉调用方失败结果。fallback不存在或者fallback执行失败,不同的方法将会有不同的表现:
execute,抛出一个异常。
queue,返回一个future,但是调用get方法时,将会抛出异常。
observe,返回一个Observable,一旦被监听会立即调用监听者的onError方法。
toObservable,返回一个Observable,一旦被监听会立即调用监听者的onError方法。
9.返回成功结果
如果hystrix命令执行成功,它将会返回一个Observable,根据调用的方法,Observable将会被转换成响应结果:
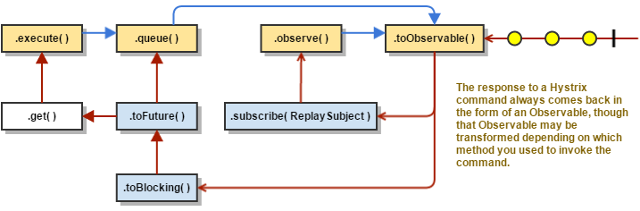
- execute-通过queue获取一个future,然后通过future对象的get方法获取一个值。
- queue-通过toObservable获取一个Observable对象,然后通过toBlocking方法获得一个Future.
- observe-返回Observable对象,当监听该Observable会把所有消息重新发送一边。
- toObservable-返回Observable对象,当监听该Observable,开始执行命令。
熔断器
下面的图表展示了HystrixCommand和HystrixObservableCommand与HystrixCircuitBreaker交互的流程,以及HystrixCircuitBreaker的原理。

熔断器开关条件:
- 如果请求量到达了指定值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold)
- 如果异常比率超过了指定值(HystrixCommandProperties.circuitBreakerErrorThresholdPercentage)
- 则,熔断器将状态设置为OPEN.
- 之后所有请求都会被直接熔断。
- 在经过指定窗口期(HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds)后,状态将会被设置为HALF-OPEN,如果该请求失败了,状态重新被设置为OPEN并且等待下一个窗口期,如果请求成功了,状态设置为CLOSE。
隔离
hystrix使用了舱壁隔离模式来隔离和限制各个请求。
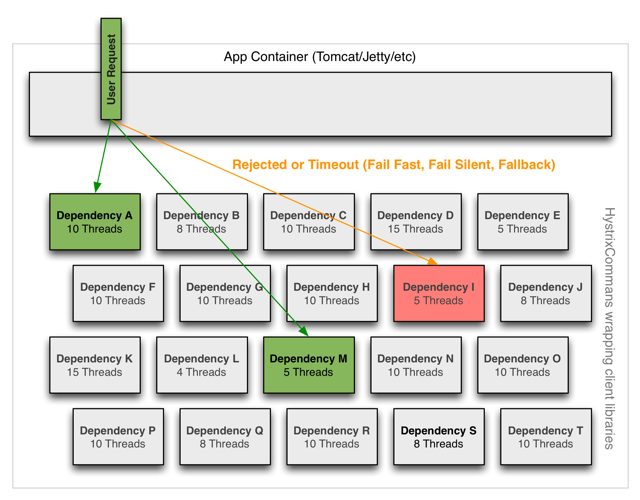
线程和线程池
第三方依赖在独立的线程池中执行,这样可以隔离调用线程(tomcat线程池)实现异步调用。
hystrix为每个依赖服务调用使用独立池。

在依赖调用能够快速失败或者可以一直运行良好的情况下,也可以不使用线程池来执行调用。
hystrix选择使用线程池有一下原因:
- 很多应用执行大量的第三方调用,这些第三方服务由不同的团队维护。
- 每一个服务有它自己的依赖包
- 这些依赖包时刻都可能变化。
- 依赖包对调用方来说是黑盒的。

使用线程池的好处:
请求缓存
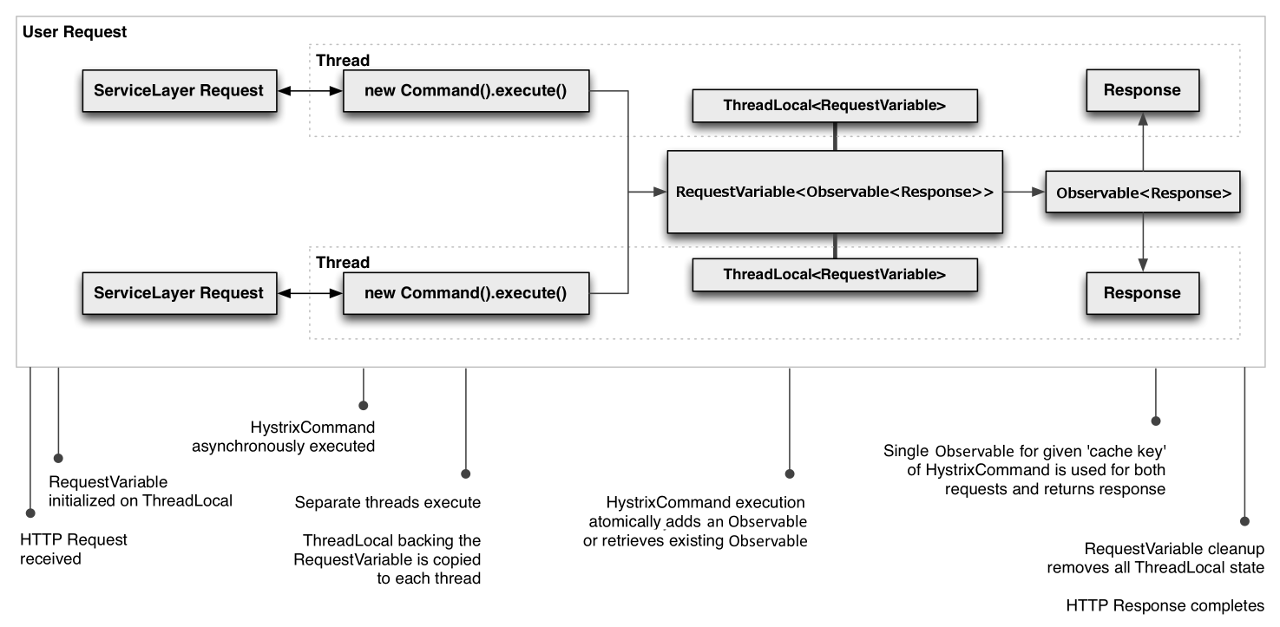
HystrixCommand和HystrixObservableCommand实现了缓存机制,通过指定一个cache key,它们能够在一个请求范围内对运行结果进行缓存以便下次使用。下面是在一个请求中两个线程执行同一个请求的流程:
使用缓存的好处:
- 线程池会隔离每一个依赖,避免他们相互影响,从而保护了整个系统
- 某几个依赖服务失败后,只要整个系统正常运行,那么恢复起来也很快。
- 通过线程池可以实现异步操作。
总之,通过线程池来隔离依赖服务可以很优雅的隔离那些经常发生变化的依赖服务从而保护整个系统的运行。
线程池的缺点
线程池的主要缺点就是增加了额外的计算资源,每一个命令的执行都需要系统进行调度。netflix基于线程池不会耗费大量计算资源而决定使用这样的设计。
线程池花费
hystrix计算了通过线程池执行construct和run的延时。Netflix API 每天使用线程池方式处理上百亿的请求,每一个API都有40多个线程池,每个线程池中有5~20个线程。线图显示了一个QPS为60的HystrixCommand在线程池模式下的执行性能

平均请求,线程池几乎没有什么花费。
90th%,线程池花费3ms
99th%,线程池花费达到了9ms。但是线程池的增长远远小于整个请求的延时增长。超过90th%的花费对于大多数的Netflix使用场景来说是可接受的。
信号量
也可以使用信号量来限制每个依赖的并发数量。他可以对依赖服务降级,但不能监听timeout,如果我们对依赖服务的调用确认不会出现timeout情况,我们也可以使用这中方式。
HystrixCommand和HystrixObservableCommand在下面两个地方支持使用信号量。
- 降级方法fallback:当Hystrix执行fallback方法时,总是会通过信号量检查并发量。
- 执行方法:如果设置了execution.isolation.strategy为SEMAPHORE,Hystrix将会使用信号量来控制并发数。
可以通过动态的配置来设置并发数。尽可能设置合适的并发数,不可设置过大的并发数,这样将导致无法起保护作用。
请求合并
通过使用HystrixCollapser可以实现合并多个请求批量执行。下面的图标显示了使用请求合并和不是请求合并,他们的线程迟和连接情况:

使用请求合并可以减少线程数和并发连接数,并且不需要使用这额外的工作。请求合并有两种作用域,全局作用域会合并全局内的同一个HystrixCommand请求,请求作用域只会合并同一个请求内的同一个HystrixCommand请求。但是请求合并会增加请求的延时。

缓存
一个请求对同一个Hystrix Command调用可以避免重复执行。
对于一些延时比较低的,不需要检测timeout的依赖,我们也可以使用信号量控制方式来做隔离,减少额外的花费。
这个功能对于多人协作开发的大型的项目非常有用。据一个例子,在一个请求中,多个地方需要使用用户的Account对象。
Account account = new UserGetAccount(accountId).execute();
//or
Observable<Account> accountObservable = new UserGetAccount(accountId).observe();
Hystrix将会执行run方法一次,两个线程都会接收到各自内容相同的Account对象。当执行第一次run方法后,结果将会被缓存起来,当在同一个请求执行同一个命令时,会直接使用缓存值。
减少线程重复执行。
因为缓存是在执行run或者construct方法前进行判断的,所以可以减少run和construct的调用。如果Hystrix没有实现缓存功能,那么每个调用都需要执行construct或者run方法。
hystrix文档翻译之工作原理的更多相关文章
- Feign 系列(03)Feign 工作原理
目录 Feign 系列(03)Feign 工作原理 1. Feign 是如何设计的 2. Feign 动态代理 2.1 ReflectiveFeign 构建 2.2 生成代理对象 2.3 Method ...
- 菜鸟学Struts2——Struts工作原理
在完成Struts2的HelloWorld后,对Struts2的工作原理进行学习.Struts2框架可以按照模块来划分为Servlet Filters,Struts核心模块,拦截器和用户实现部分,其中 ...
- 【夯实Nginx基础】Nginx工作原理和优化、漏洞
本文地址 原文地址 本文提纲: 1. Nginx的模块与工作原理 2. Nginx的进程模型 3 . NginxFastCGI运行原理 3.1 什么是 FastCGI ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 【Oracle 集群】ORACLE DATABASE 11G RAC 知识图文详细教程之RAC 工作原理和相关组件(三)
RAC 工作原理和相关组件(三) 概述:写下本文档的初衷和动力,来源于上篇的<oracle基本操作手册>.oracle基本操作手册是作者研一假期对oracle基础知识学习的汇总.然后形成体 ...
- ThreadLocal 工作原理、部分源码分析
1.大概去哪里看 ThreadLocal 其根本实现方法,是在Thread里面,有一个ThreadLocal.ThreadLocalMap属性 ThreadLocal.ThreadLocalMap t ...
- Servlet的生命周期及工作原理
Servlet生命周期分为三个阶段: 1,初始化阶段 调用init()方法 2,响应客户请求阶段 调用service()方法 3,终止阶段 调用destroy()方法 Servlet初始化阶段: 在 ...
- 代码管理工具 --- git的学习笔记二《git的工作原理》
通过几个问题来学习代码管理工具之git 一.git是什么?为什么要用它?使用它的好处?它与svn的区别,在Mac上,比较好用的git图形界面客户端有 git 是分布式的代码管理工具,使用它是因为,它便 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
随机推荐
- JAVA HTML 以压缩包下载多文件
Html: 利用form表单来发送下载请求 <form id ="submitForm" method="post"> </form> ...
- leetcode刷题记录——树
递归 104.二叉树的最大深度 /** * Definition for a binary tree node. * public class TreeNode { * int val; * Tree ...
- Java之Annotation(注解)——注解处理器
如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了.使用注解的过程中,很重要的一部分就是创建于使用注解处理器.Java SE5扩展了反射机制的API,以帮助程序员快速的构造自定义注解处 ...
- springboot~通过面向接口编程对控制反转IOC的理解
IOC,把控制反转到业务端,这句话没什么问题,在springboot框架里,对象的管理是通过spring ioc来实现的,而开发人员的开发原则里总是说"面向接口编程",而为什么要面 ...
- Cinder Volume 服务启动流程分析和周期性任务分析
1.cinder-volume服务的程序入口 #!/usr/bin/python2 # PBR Generated from u'console_scripts' import sys from ci ...
- 第一篇Scrum冲刺博客
目录 一.Alpha 阶段认领的任务 二.明日成员的任务安排 三.整个项目预期的任务量 四.敏捷开发前的感想 五.团队期望 一.Alpha 阶段认领的任务 陈起廷 任务 预计时间 日记天气.心情选择 ...
- 温故知新——Spring AOP(二)
上一篇我们介绍Spring AOP的注解的配置,也叫做Java Config.今天我们看看比较传统的xml的方式如何配置AOP.整体的场景我们还是用原来的,"我穿上跑鞋",&quo ...
- [PyTorch 学习笔记] 3.2 卷积层
本章代码:https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson3/nn_layers_convolution.py 这篇文 ...
- IDEA创建MAVEN项目并使用tomcat启动
一.开发环境准备 1.JDK1.8,已经配置好环境变量 2.IDEA2019.2,目前稳定版里面个人认为还不错的 3.tomcat服务器,笔者使用的是apache-tomcat-8.5.57 4.使用 ...
- 力扣Leetcode 1518. 换酒问题
小区便利店正在促销,用 numExchange 个空酒瓶可以兑换一瓶新酒.你购入了 numBottles 瓶酒. 如果喝掉了酒瓶中的酒,那么酒瓶就会变成空的. 请你计算 最多 能喝到多少瓶酒. 示例: ...