python 正则表达式 RE模块汇总记录
- re.compile(pattern, flags=0)
- re.search(pattern, string, flags=0)
- re.match(pattern, string, flags=0)
- re.fullmatch(pattern, string, flags=0)
- re.split(pattern, string, maxsplit=0, flags=0)
- re.findall(pattern, string, flags=0)
- re.finditer(pattern, string, flags=0)
- re.sub(pattern, repl, string, count=0, flags=0)
- re.subn(pattern, repl, string, count=0, flags=0)
- re.escape(string)
- re.purge()
1.re.compile(pattern, flags=0)
把一个表达式字符串转化成为一个RegexObject
pattern:正则表达式字符,如'\d'
flags:匹配模式,可以使用按位或'|'表示同时生效
匹配模式有:
re.A/re.ASCII:仅执行8位的ASCII码字符匹配
re.DEBUG:查看正则表达式的匹配过程
re.I/re.IGNORECASE:忽略大小写
re.L/re.LOCALE:使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.M/re.MULTILINE:多行匹配。当指定时,模式字符' ^'匹配字符串的开头以及每个行的开头(紧接每个换行符); 模式字符'$'匹配字符串的末尾以及每一行的结尾(紧靠每个换行符之前)。默认情况下, '^'只匹配字符串的开始,'$'只匹配字符串的末尾和字符串末尾换行符(如果有的话)之前的位置。
re.S/re.DOTALL:使.匹配包括换行在内的所有字符
re.X/re.VERBOSE:允许在正则表达式规则中加入注释,但默认会去掉所有空格。
re.U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
例子:
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
4 b = re.compile(r"\d+\.\d*")
以上a等价于b
import re
s="123abc45AB"
reg=re.compile('a',re.I)
reg.findall(s)
输出:
['a','A']
2.re.search(pattern, string, flags=0)
pattern:正则表达式模式字符串,如'\d'
string:要匹配的字符串
flags:匹配模式,可以使用按位或'|'表示同时生效
将字符串的所有字符尝试与正则表达式匹配,如果匹配成功,返回matchobject,否则返回None.若有多个匹配成功,只返回第一个匹配结果。matchobject有多个属性和方法。
import re
m= re.search(r'(\d+)\w(\d+)', 'ab12c34d56')
print("m.string:", m.string)
print("m.re:", m.re)
print("m.pos:", m.pos)
print("m.endpos:", m.endpos)
print("m.lastindex:", m.lastindex)
print("m.lastgroup:", m.lastgroup)
print("m.group(1,2):", m.group(1, 2))
print("m.groups():", m.groups())
print("m.groupdict():", m.groupdict())
print("m.start(2):", m.start(2))
print("m.end(2):", m.end(2))
print("m.span(2):", m.span(2))
print("m.expand(r'\\2\\1'):", m.expand(r'\2 \1'))
#
#m.string: ab12c34d56
#m.re: re.compile('(\\d+)\\w(\\d+)')
#m.pos: 0 #代表RE开始搜索字符串的位置。
#m.endpos: 10 #代表RE搜索字符串的结束位置。
#m.lastindex: 2 #最后一次匹配到的组的数字序号,如果没有匹配到,将得到None
#m.lastgroup: None #最后一次匹配到的组的名字,如果没有匹配到或者最后的组没有名字,将得到None。
#m.group(1,2): ('12', '34') #返回一个或多个子组,如果不传任何参数,效果和传入一个0一样,将返回整个匹配。
#m.groups(): ('12', '34') #返回一个由所有匹配到的子串组成的元组。
#m.groupdict(): {} #返回一个包含所有命名组的名字和子串的字典
#m.start(2): 5 #返回被组group匹配到的子串在原字符串中的开始位置。如果不指定group或group指定为0,则代表整个匹配。如果group未匹配到,则返回 -1。
#m.end(2): 7 #返回被组group匹配到的子串在原字符串中的后一个位置
#m.span(2): (5, 7) #返回一个元组: (m.start(group), m.end(group))
#m.expand(r'\2\1'): 34 12
3.re.match(pattern, string, flags=0)
参数同re.search
在字符串开头匹配,其他re.search一致。不同的是如果匹配的字符不在字符串开头,re.search可以寻到,re.match不可以。
4.re.fullmatch(pattern, string, flags=0)
如果模式完全匹配字符串,则返回一个matchobject,不匹配则返回None
import re
m1=re.fullmatch(r'\d',"")
print('m1.group():', m1.group())
print('m1.groups():', m1)
#
#m1.group(): 3
#m1.groups(): <_sre.SRE_Match object; span=(0, 1), match='3'> m1=re.fullmatch(r'\d',"3d")
print('m1.groups():', m1)
#
#m1.groups(): None
5.re.split(pattern, string, maxsplit=0, flags=0)
maxsplit:分割次数
其他参数同上
通过正则表达式将字符串分割,匹配到符合的字符就把字符串分割一次,maxsplit没有赋值,找到几个匹配项就分割几次,若maxsplit赋值小于匹配项个数,则分割maxsplit次。返回一个list。
import re
print("re.split('\d','ab12c4d56d'):",re.split('\d','ab12c4d56d'))
print("re.split('\d','ab12c4d56d'):",re.split('\d','ab12c4d56d',3))
print("re.split('\d','ab12c4d56d'):",re.split('\d','ab12c4d56d',2))
#
#re.split('\d','ab12c4d56d'): ['ab', '', 'c', 'd', '', 'd']
#re.split('\d','ab12c4d56d'): ['ab', '', 'c', 'd56d']
#re.split('\d','ab12c4d56d'): ['ab', '', 'c4d56d']
6.re.findall(pattern, string, flags=0)
7.re.finditer(pattern, string, flags=0)
查找整个字符串,返回所有的匹配项。参数与re.search一致。
re.search和re.match只会返回一个匹配项,而re.findall和re.finditer返回所有匹配项。
re.findall返回一个列表,包含所有匹配项。
re.finditer返回一个迭代器。
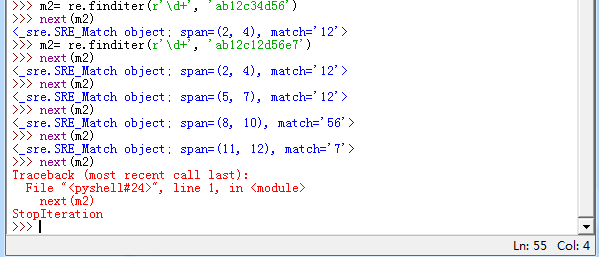
import re
m1= re.findall(r'\d+', 'ab12c12d56e7')
print("m1:", m1) m2= re.finditer(r'\d+', 'ab12c12d56e7')
print("m2:", m2) #
#m1: ['12', '12', '56', '7']
#m2: <callable_iterator object at 0x000000000112EE80>
8.re.sub(pattern, repl, string, count=0, flags=0)
9.re.subn(pattern, repl, string, count=0, flags=0)
pattern:表示需要匹配的正则表达式模式字符,匹配到的字符将会被替换
repl:表示替换的字符串,可以是字符串,也可以是函数
string:要被处理的字符串
count:替换次数
把string中所有符合pattern的字符串,替换成repl,count如赋值小于匹配项个数,则把前count个匹配项替换掉,其他字符不变。
re.sub返回完成替换之后的字符串。
re.subn返回元组,(完成替换之后的字符串,替换次数)。
(特殊情况:如果匹配不到,则返回原字符串)
import re
s1=re.sub(r'\d','w','qqq12q3',1)
print("s1:", s1)
s2=re.subn(r'\d','w','qqq12q3',1)
print("s2:", s2)
#
#s1: qqqw2q3
#s2: ('qqqw2q3', 1) s1=re.sub(r'\d','w','qqq12q3')
print("s1:", s1)
s2=re.subn(r'\d','w','qqq12q3')
print("s2:", s2)
#
#s1: qqqwwqw
#s2: ('qqqwwqw', 3)
#---------sub利用函数替换----------
s3=re.sub('\d',lambda m:'-'+m.group(0)+'-','sd1w2ed3e4') #在数字前后加上'-' print('s3=',s3)
#
#s3='sd-1-w-2-ed-3-e-4-'
10.re.escape(string)
对string字符串中的除了字母数字以外所有字符进行转义,都加上反斜杆。
import re
s=re.escape('a1.*@')
print("s:", s)
#
#s: a1\.\*\@
11.re.purge()
清空缓存中的正则表达式
(此图源自网络,不记得原出处,若侵权,请联系,必马上删除)

python 正则表达式 RE模块汇总记录的更多相关文章
- python正则表达式Re模块备忘录
title: python正则表达式Re模块备忘录 date: 2019/1/31 18:17:08 toc: true --- python正则表达式Re模块备忘录 备忘录 python中的数量词为 ...
- Python面试题之Python正则表达式re模块
一.Python正则表达式re模块简介 正则表达式,是一门相对通用的语言.简单说就是:用一系列的规则语法,去匹配,查找,替换等操作字符串,以达到对应的目的:此套规则,就是所谓的正则表达式.各个语言都有 ...
- Python 正则表达式——re模块介绍
Python 正则表达式 re 模块使 Python 语言拥有全部的正则表达式功能,re模块常用方法: re.match函数 re.match从字符串的起始位置匹配,如果起始位置匹配不成功,则matc ...
- python正则表达式——re模块
http://blog.csdn.net/zm2714/article/details/8016323 re模块 开始使用re Python通过re模块提供对正则表达式的支持.使用re的一般步骤是先将 ...
- python 正则表达式re模块
#####################总结############## 优点: 灵活, 功能性强, 逻辑性强. 缺点: 上手难,旦上手, 会爱上这个东西 ...
- python正则表达式re模块详细介绍--转载
本模块提供了和Perl里的正则表达式类似的功能,不关是正则表达式本身还是被搜索的字符串,都可以是Unicode字符,这点不用担心,python会处理地和Ascii字符一样漂亮. 正则表达式使用反斜杆( ...
- python正则表达式-re模块的爱恨情仇
利用python的re模块,使用正则表达式对字符串进行处理 # 编辑者:闫龙 import re restr = "abccgccc123def456ghi789jgkl186000&quo ...
- python正则表达式-re模块
目录: 一.正则函数 二.re模块调用 三.贪婪模式 四.分组 五.正则表达式修饰符 六.正则表达式模式 七.常见的正则表达式 导读: 想要使用python的正则表达式功能就需要调用re模块,re模块 ...
- python -- 正则表达式&re模块(转载)
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十 ...
随机推荐
- MFC VC++ 根据文件名获取程序的Pid
环境:PC Win7 VS VC++ .MFC 使用,输入文件名即可获取程序的pid,进而可以对程序进行操作,比如关闭Porcess等. 头文件: #include <TlHelp32.h> ...
- ceph压力测试结果总结
万兆网速的ceph分布式存储单虚拟机下的带宽和iops测试结果: 带宽: 写:700-850MB 读:800-900MB iops: 写:15000-20000 读:45000-55000
- 如何执行Python代码
1.在linux系统中执行代码有两种方法 a.在脚本的当前目录下执行:python test.py b.给脚本赋予可执行权限,然后执行代码 chmod +x test.py test.py 2.在wi ...
- Dubbo的Filter实战--整合Oval校验框架
前言: 其实很早之前就想写一篇关于oval和具体服务相整合的常见做法, 并以此作为一篇笔记. 趁现在项目中间空闲期, 刚好对dubbo的filter有一些了解. 因此想结合两者, 写一下既结合校验框架 ...
- XXS level7
(1)输入与第六关相同的Payload:"><A HREF="javascript:alert()"> 查看页面源代码,发现“herf"被过滤 ...
- Reasoning With Neural Tensor Networks For Knowledge Base Completion-paper
https://www.socher.org/index.php/Main/ReasoningWithNeuralTensorNetworksForKnowledgeBaseCompletion 年份 ...
- solr增加中文分析器
我的solr版本是5.3.0 1将jar包ik-analyzer-solr5-5.x.jar放入sor的web-inf的lib里面 2 在web-inf下面新建classes目录,再新增三个配置文件: ...
- bzoj 2460 线性基
#include<bits/stdc++.h> #define ll long long #define LL long long #define int long long using ...
- Hibernate主键自增策略
hibernate 主键生成策略配置: 通过 实体类映射文件中 <id>元素的 子元素 <generator> 元素进行配置 <generator> 常用配置: ( ...
- 随机数的组合问题(JavaScript描述)
随机数的组合问题在面试时是经常考的,比如之前我就被问到:“有一个可以生成1-5的随机数函数,怎样把它扩大到1-7?” 在解决这个问题之前,先来看看另外一个比较简单的问题:“有一个可以生成1-7的函数, ...