自增ID算法snowflake - C#版
急景流年,铜壶滴漏,时光缱绻如画,岁月如诗如歌。转载一篇博客来慰藉,易逝的韶华。
使用UUID或者GUID产生的ID没有规则
Snowflake算法是Twitter的工程师为实现递增而不重复的ID实现的
概述
分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。而twitter的snowflake解决了这种需求,最初Twitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。
该项目地址为:https://github.com/twitter/snowflake是用Scala实现的。
python版详见开源项目https://github.com/erans/pysnowflake。
结构
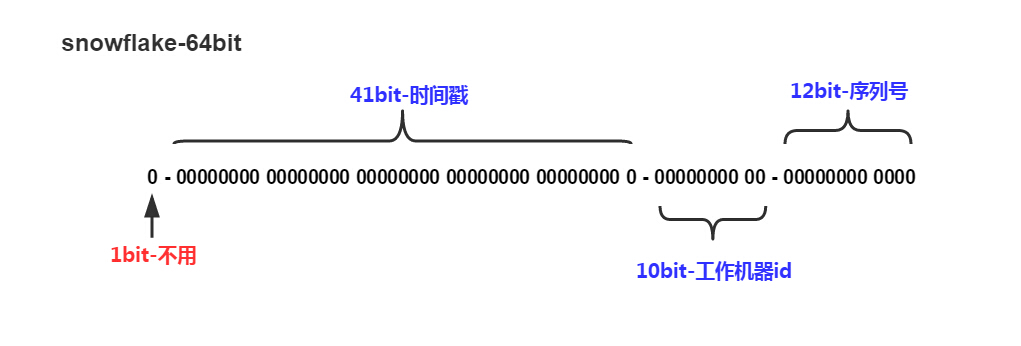
snowflake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。据说:snowflake每秒能够产生26万个ID。
从图上看除了第一位不可用之外其它三组均可浮动站位,据说前41位就可以支撑到2082年,10位的可支持1023台机器,最后12位序列号可以在1毫秒内产生4095个自增的ID。
在多线程中使用要加锁。
看懂代码前 先来点计算机常识:<<左移 假如1<<2 :1左移2位=1*2^2=4(这里^是多少次方的意思,和下面的不同,哈别混淆。)
^异或 :true^true=false false^false=false true^false=true false^true=true 例子: 1001^0001=1000
负数的二进制:
第二步:各位取反,0变1,1变0
第三步:最后面加1
好了废话不多说 直接代码:
public class IdWorker
{
//机器ID
private static long workerId;
private static long twepoch = 687888001020L; //唯一时间,这是一个避免重复的随机量,自行设定不要大于当前时间戳
private static long sequence = 0L;
private static int workerIdBits = ; //机器码字节数。4个字节用来保存机器码(定义为Long类型会出现,最大偏移64位,所以左移64位没有意义)
public static long maxWorkerId = -1L ^ -1L << workerIdBits; //最大机器ID
private static int sequenceBits = ; //计数器字节数,10个字节用来保存计数码
private static int workerIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数
private static int timestampLeftShift = sequenceBits + workerIdBits; //时间戳左移动位数就是机器码和计数器总字节数
public static long sequenceMask = -1L ^ -1L << sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微秒在进行生成
private long lastTimestamp = -1L; /// <summary>
/// 机器码
/// </summary>
/// <param name="workerId"></param>
public IdWorker(long workerId)
{
if (workerId > maxWorkerId || workerId < )
throw new Exception(string.Format("worker Id can't be greater than {0} or less than 0 ", workerId));
IdWorker.workerId = workerId;
} public long nextId()
{
lock (this)
{
long timestamp = timeGen();
if (this.lastTimestamp == timestamp)
{ //同一微秒中生成ID
IdWorker.sequence = (IdWorker.sequence + ) & IdWorker.sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限
if (IdWorker.sequence == )
{
//一微秒内产生的ID计数已达上限,等待下一微秒
timestamp = tillNextMillis(this.lastTimestamp);
}
}
else
{ //不同微秒生成ID
IdWorker.sequence = ; //计数清0
}
if (timestamp < lastTimestamp)
{ //如果当前时间戳比上一次生成ID时时间戳还小,抛出异常,因为不能保证现在生成的ID之前没有生成过
throw new Exception(string.Format("Clock moved backwards. Refusing to generate id for {0} milliseconds",
this.lastTimestamp - timestamp));
}
this.lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳
long nextId = (timestamp - twepoch << timestampLeftShift) | IdWorker.workerId << IdWorker.workerIdShift | IdWorker.sequence;
return nextId;
}
} /// <summary>
/// 获取下一微秒时间戳
/// </summary>
/// <param name="lastTimestamp"></param>
/// <returns></returns>
private long tillNextMillis(long lastTimestamp)
{
long timestamp = timeGen();
while (timestamp <= lastTimestamp)
{
timestamp = timeGen();
}
return timestamp;
} /// <summary>
/// 生成当前时间戳
/// </summary>
/// <returns></returns>
private long timeGen()
{
return (long)(DateTime.UtcNow - new DateTime(, , , , , , DateTimeKind.Utc)).TotalMilliseconds;
} }
调用:
IdWorker idworker = new IdWorker();
for (int i = ; i < ; i++)
{
Console.WriteLine(idworker.nextId());
}
其他算法:
方法一:UUID
UUID是通用唯一识别码 (Universally Unique Identifier),在其他语言中也叫GUID,可以生成一个长度32位的全局唯一识别码。
String uuid = UUID.randomUUID().toString()
结果示例:
046b6c7f-0b8a-43b9-b35d-6489e6daee91
为什么无序的UUID会导致入库性能变差呢?
这就涉及到 B+树索引的分裂:
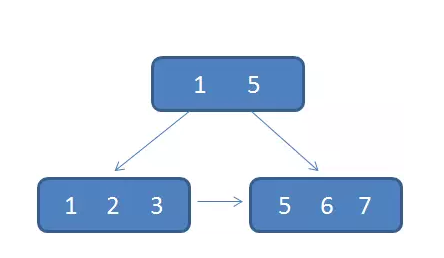
众所周知,关系型数据库的索引大都是B+树的结构,拿ID字段来举例,索引树的每一个节点都存储着若干个ID。
如果我们的ID按递增的顺序来插入,比如陆续插入8,9,10,新的ID都只会插入到最后一个节点当中。当最后一个节点满了,会裂变出新的节点。这样的插入是性能比较高的插入,因为这样节点的分裂次数最少,而且充分利用了每一个节点的空间。
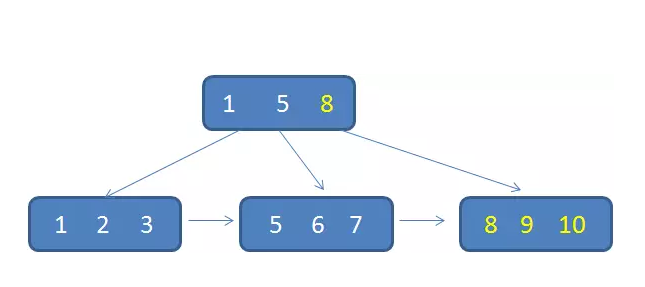
但是,如果我们的插入完全无序,不但会导致一些中间节点产生分裂,也会白白创造出很多不饱和的节点,这样大大降低了数据库插入的性能。
方法二:数据库自增主键
假设名为table的表有如下结构:
id feild
35 a
每一次生成ID的时候,访问数据库,执行下面的语句:
begin;
REPLACE INTO table ( feild ) VALUES ( 'a' );
SELECT LAST_INSERT_ID();
commit;
REPLACE INTO 的含义是插入一条记录,如果表中唯一索引的值遇到冲突,则替换老数据。
这样一来,每次都可以得到一个递增的ID。
为了提高性能,在分布式系统中可以用DB proxy请求不同的分库,每个分库设置不同的初始值,步长和分库数量相等:
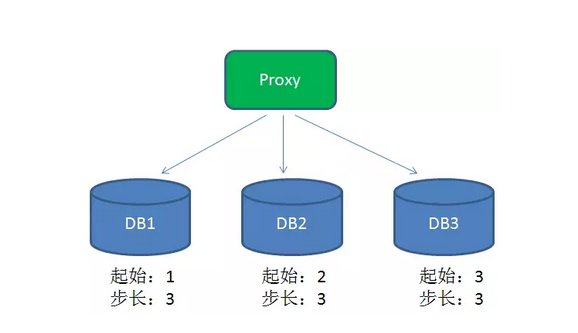
这样一来,DB1生成的ID是1,4,7,10,13....,DB2生成的ID是2,5,8,11,14.....

自增ID算法snowflake - C#版的更多相关文章
- Twitter的分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
- 分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- Twitter分布式自增ID算法snowflake原理解析
以JAVA为例 Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个 ...
- Twitter分布式自增ID算法snowflake原理解析(Long类型)
Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个Long类型的6 ...
- 分布式自增ID算法-Snowflake详解
1.Snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并 ...
- 自增ID算法snowflake(雪花)
在数据库主键设计上,比较常见的方法是采用自增ID(1开始,每次加1)和生成GUID.生成GUID的方式虽然简单,但是由于采用的是无意义的字符串,推测会在数据量增大时造成访问过慢,在基础互联网的系统设计 ...
- 基于.NET Standard的分布式自增ID算法--Snowflake
概述 本篇文章主要讲述分布式ID生成算法中最出名的Snowflake算法.搞.NET开发的,数据库主键最常见的就是int类型的自增主键和GUID类型的uniqueidentifier. 那么为何还要引 ...
- Twitter的分布式自增ID算法snowflake
snowflake 分布式场景下获取自增id git:https://github.com/twitter/snowflake 解读: http://www.cnblogs.com/relucent/ ...
随机推荐
- SQL注入学习资料总结
转载自:https://bbs.ichunqiu.com/thread-12105-1-1.html 什么是SQL注入 SQL注入基本介绍 结构化查询语言(Structured Query Lang ...
- [转]Emmet使用详解
Emmet的前身是大名鼎鼎的Zen coding,如果你从事Web前端开发的话,对该插件一定不会陌生.它使用仿CSS选择器的语法来生成代码,大大提高了HTML/CSS代码编写的速度,而且作为一款插件能 ...
- Java源码阅读的真实体会(一种学习思路)
Java源码阅读的真实体会(一种学习思路) 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈 ...
- 同步调用异步方法how-would-i-run-an-async-taskt-method-synchronously
同步调用异步方法帮助类: public static class AsyncHelpers { /// <summary> /// Execute's an async Task<T ...
- 5迪米特法则LoD
一.什么是迪米特法则 迪米特法则(Law of Demeter )又叫做最少知识 原则,也就是说,一个对象应当对其他对象尽可 能少的了解. 迪米特法则最初是用来作为面向对象的系统设 计风格的一种法则, ...
- Oracle创建表空间以及用户语句
记录一下常用的语句,便于以后使用… create tablespace TABLESPACENAMEdatafile 'E:\Data\ORACLEDATA\XXX.dbf' size 200M au ...
- Python Solve UnicodeEncodeError 'gbk' / 'ascii' / 'utf8' codec can't encode character '\x??' in position ? 解决有关Python编码的错误
在Python中,处理中文字符一直是很令人头痛的问题,一言不合就乱码,而且引起乱码的原因也不尽相同,有时候是python本身默认的编码器设置的不对,有时候是使用的IDE的解码器不对,还有的时候是终端t ...
- javascript 获取多种主流浏览器显示页面高度(转)
IE中:document.body.clientWidth ==> BODY对象宽度document.body.clientHeight ==> BODY对象高度document.docu ...
- 在vue项目里使用jquery
1.NPM 安装 jQuery,项目根目录下运行以下代码 npm install jquery --save 2.webpack配置在项目根目录下的build目录下找到webpack.base.con ...
- MVCC&PURGE&分布式事务
Ⅰ.MVCC介绍 consistent non-locking read,通过行多版本控制的方式读取当前执行时间点的记录 默认情况下innodb select没有任何锁,读到的记录在更新就通过undo ...