day83
今日内容
rest_framework序列化
首先序列化需要对写一个类继承serializers.Serializer
方式一:在models的publish写一个__str__方法返回出版社名字
publish = serializers.CharField()
方式二:可以用source指定一个models中的方法
publish = serializers.CharField(source='publish.test')
方式三:直接用publish.他的字段名
publish = serializers.CharField(source='publish.name')
'''
class author_serializers(serializers.Serializer):
name = serializers.CharField()
age = serializers.CharField() class Books_serializers(serializers.Serializer):
xxx = serializers.CharField(source='name')
yyy = serializers.CharField(source='price')
# 方式一:在models的publish写一个__str__方法返回出版社名字
# publish = serializers.CharField()
# 方式二: 可以用source指定一个models中的方法
# publish = serializers.CharField(source='publish.test')
# 方式三:直接用publish.他的字段名
# publish = serializers.CharField(source='publish.name')
# SerializerMethodField可以指定一个方法,该方法需要时get_该字段名 publish = serializers.SerializerMethodField()
def get_publish(self, obj):
dic = {'name': obj.publish.name, 'price': obj.publish.email}
return dic # 可以继续使用序列化
authors = serializers.SerializerMethodField() # def get_authors(self, obj):
author = obj.authors.all()
pub = author_serializers(author, many=True)
return pub.data
''' class author_serializers(serializers.Serializer):
name = serializers.CharField()
age = serializers.CharField() class Books_serializers(serializers.ModelSerializer):
class Meta:
model = models.Book
# 查询所有字段
# fields = '__all__'
# 查询列表中的字段
fields = ['nid','name']
# 除了这几个字段不要,查询其余字段
# exclude = ['publish', 'authors']
# 指定查询深度
# depth = 1
# publish = serializers.CharField(source='publish.name')
# authors = serializers.SerializerMethodField()
# def get_authors(self, obj):
# authors = obj.authors.all()
# Authors = author_serializers(authors, many=True)
# return Authors.data
视图函数:
class Books(APIView):
def get(self, request):
db_books = models.Book.objects.all()
BOOKS = books(db_books, many=True)
return JsonResponse(BOOKS.data, safe=False) def delete(self, request):
id = request.query_params.get('id')
models.Book.objects.filter(pk=id).delete()
dic = {'status': 100, 'msg': '删除成功'}
return JsonResponse(dic) def put(self, request):
id = request.query_params.get('id')
name = request.data.get('name')
price = request.data.get('price')
models.Book.objects.filter(pk=id).update(name=name, price=price)
dic = {'status': 100, 'msg': '修改成功'}
return JsonResponse(dic, safe=False) def post(self, request):
p_name = request.data.get('name')
p_price = request.data.get('price')
p_publish = request.data.get('publish')
p_authors = request.data.get('authors')
book = models.Book.objects.create(name=p_name, price=p_price, publish_id=p_publish)
p_authors = p_authors.split(',')
for p_author in p_authors:
author = models.Author.objects.filter(pk=p_author).first()
print(author)
book.authors.add(author)
print(book)
ret = books(book, many=False)
return JsonResponse(ret.data, safe=False)
HyperlinkedIdentityField(用的很少)
-1 publish = serializers.HyperlinkedIdentityField(view_name='ttt',lookup_field='publish_id',lookup_url_kwarg='pky')
-2 view_name:路由的别名,lookup_field:根据表的哪个字段,来拼路径,lookup_url_kwarg:反向解析有名分组的名字
-3 写路由:url(r'^publish/(?P<pky>\d+)', views.Publish.as_view(),name='ttt'),
-4 实例化序列化类的时候,需要把request对象传过去
book_ser=BookSerializer(ret,many=True,context={'request': request})
设置:
class book_serializers(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = '__all__' url = serializers.HyperlinkedIdentityField(source='name', view_name='book', lookup_field='nid',
lookup_url_kwarg='pk')
# 该设置与form校验类似,都可设置一些参数(max_length,error_messages)
name = serializers.CharField(max_length=20, error_messages={'required': '必填', 'max_length': '太长'})
authors = serializers.CharField(required=False)
视图函数使用:
class BOOK(APIView):
def get(self, request, *args, **kwargs):
books = models.Book.objects.all()
bs = SER.book_serializers(books, many=True, context={'request': request})
return JsonResponse(bs.data, safe=False)
序列化组件的数据校验
-类比forms组件
-字段是否必填,通过required,来控制 authors=serializers.CharField(required=False)
-数据校验,生成一个序列化类的对象
-对象.is_valid()
-新增数据:
-对象.save()
-修改数据:
-在生成对象的时候,需要传instanse=查询出来的对象
-对象.save()
视图函数中使用:
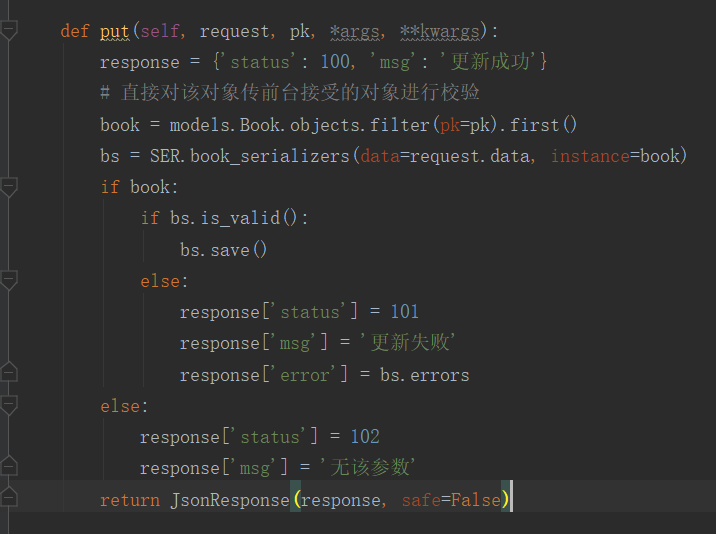
设置时:
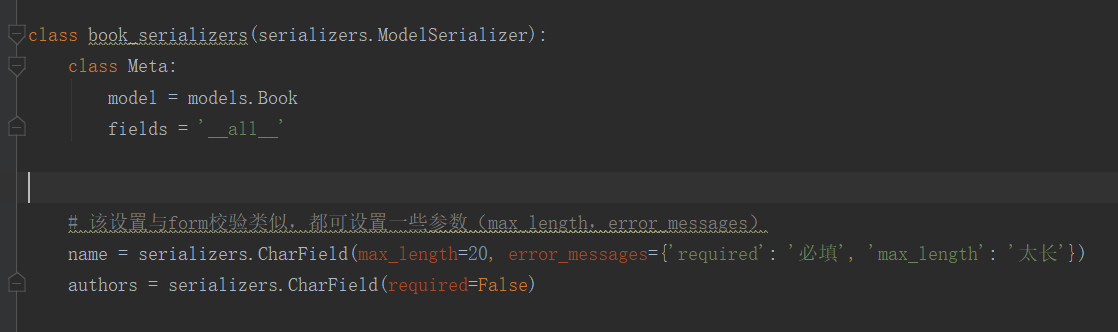
校验中的局部、全局钩子
def validate_name(self, value):
user = models.UserInfo.objects.filter(name=value).first()
if user:
raise ValidationError('用户名存在')
else:
return value def validate(self, attrs):
name = attrs.get('name')
pwd = attrs.get('pwd')
if name and pwd:
if name == pwd:
raise ValidationError('用户密码不能相同')
else:
return attrs
return attrs
day83的更多相关文章
- python 全栈开发,Day83(博客系统子评论,后台管理,富文本编辑器kindeditor,bs4模块)
一.子评论 必须点击回复,才是子评论!否则是根评论点击回复之后,定位到输入框,同时加入@评论者的用户名 定位输入框 focus focus:获取对象焦点触发事件 先做样式.点击回复之后,定位到输入框, ...
- day83:luffy:添加购物车&导航栏购物车数字显示&购物车页面展示
目录 1.添加购物车+验证登录状态 2.右上方购物车图标的小红圆圈数字 3.Vuex 4.购物车页面展示-后端接口 5.购物车页面展示-前端 6.解决一个购物车数量显示混乱的bug 1.添加购物车+验 ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
- 老男孩Python高级全栈开发工程师三期完整无加密带课件(共104天)
点击了解更多Python课程>>> 老男孩Python高级全栈开发工程师三期完整无加密带课件(共104天) 课程大纲 1.这一期比之前的Python培新课程增加了很多干货:Linux ...
- 国内某Python大神自创完整版,系统性学习Python
很多小伙伴纠结于这个一百天的时间,我觉得完全没有必要,也违背了我最初放这个大纲上来的初衷,我是觉得这个学习大纲还不错,自学按照这个来也能相对系统的学习知识,而不是零散细碎的知识最后无法整合,每个人的基 ...
- 22期老男孩Ptython全栈架构师视频教程
老男孩Ptython全栈架构师视频教程 Python最新整理完整版22期视频教程 超60G课程容量<ignore_js_op> <ignore_js_op> <ignor ...
随机推荐
- 微信小程序实现验证码倒计时效果
效果图 wxml <input class='input-pwd' placeholder="新密码" placeholder-style='color: #000' pas ...
- 【代码笔记】Web-ionic单选框
一,效果图. 二,代码. <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- XML语言学习随笔
XML和HTML都是W3C的定制的标准,XML的诞生本身是为了替代不成熟的HTML,但是因为现实的环境,XML替代HTML并未成功.之后W3C为了代码严谨性的决心,又发布了升级版的标记语言XHTML, ...
- ES6模块化与常用功能
目前开发环境已经普及使用,如vue,react等,但浏览器环境却支持不好,所以需要开发环境编译,下面介绍下开发环境的使用和常用语法: 一,ES6模块化 1,模块化的基本语法 ES6 的模块自动采用严格 ...
- cve-list
dlink CVE-2018-17786 CVE-2018-17787 CVE-2018-17880 CVE-2018-17881 mongoose CVE-2018-10945 openwrt CV ...
- JVM内核优化
1.垃圾回收器 JVM垃圾回收器有串行和并行两种. 1.1 Serial收集器(串行,单线程),现在使用较少 Serial一般收集新生代 SerialOld一般收集老年代(采用标记压缩算法) 1.2 ...
- EntityFramework Code-First 简易教程(七)-------领域类配置之Fluent API
Fluent API配置: 前面我们已经了解到使用DataAnotations特性来覆写Code-First默认约定,现在我们来学习Fluent API. Fluent API是另一种配置领域类的方法 ...
- Elasticsearch安装图形化界面工具Head插件
1.Head插件介绍以及下载 Head插件是Elasticsearch的图形化界面工具,通过此插件可以很方便的对数据进行增删改查等数据交互操作.在Elasticsearch5.x版本以后,head插件 ...
- Django 项目连接数据库Mysql要安装mysqlclient驱动出错 : Failed building wheel for mysqlclient:
1,如果直接用 CMD命令:pip install mysqlclient ,会安装出错. 2,解决问题,参考了这个博友的帖子:https://blog.csdn.net/qq_29784441/ar ...
- February 10th, 2018 Week 6th Saturday
It is not enough to have a good mind. The main thing is to use it well. 头脑聪明还不够,重要的是好好运用. From Rene ...