深入理解RDD原理
首先我们来了解一些Spark的优势:
1.每一个作业独立调度,可以把所有的作业做一个图进行调度,各个作业之间相互依赖,在调度过程中一起调度,速度快。
2.所有过程都基于内存,所以通常也将Spark称作是基于内存的迭代式运算框架。
3.spark提供了更丰富的算子,让操作更方便。
4.更容易的API:支持Python,Scala和Java
其实spark里面也可以实现Mapreduce,但是这里它并不是算法,只是提供了map阶段和reduce阶段,但是在两个阶段提供了很多算法。如Map阶段的map, flatMap, filter, keyBy,Reduce阶段的reduceByKey, sortByKey, mean, gourpBy, sort等。
那么话不多说,上源码~~~

上面是源代码中对RDD的解释:
1、是一个有分区的集合
2、在每一个切片(分区)上都有一个相应的函数,一一对应的
3、每个RDD都会依赖的上一个RDD
4、(可选)如果是(K,V)类型的RDD,会采用分区器(默认的是Hash-Partitioner,规则是key的hashCode 值除以下游模的数量)
RDD是一个抽象的数据集,并不是用来装真正要计算的数据,而装的是处理数据的描述信息(即,对哪个文件进行计算,该怎么计算),任何数据在Spark中都被表示为RDD,从编程角度来看,RDD可以简单的看成一个数组,和普通的数组的区别是,RDD中的数据是分布式存储的,这样不同分区的数据就可以分布在不同的机器上,同时可以被并行化处理。因此,Spark应用程序所做的无非是把需要处理的数据转换成RDD,(在这个过程一定要学会区分transformation和action)然后RDD进行一系列的变换和操作从而得到结果。
那么我们该如何创建RDD呢?
RDD可以从普通数组创建出来,也可以从文件系统或者HDFS的文件创建出来。
方式1、举例:从普通数组创建RDD,里面包含了1到9这9个数字,他们分别在3个分区中。
scala>val a=sc.parallelize(1 to 9, 3) //3是指有三个分区,parallelize是把数据并行化
a:org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:12
方式2、举例:读取文件README.md来创建RDD,文件中的每一行就是RDD中的一个元素
scala> val b = sc.textFile("README.md")
b: org.apache.spark.rdd.RDD[String] = MappedRDD[3] at textFile at <console>:12
scala>val distFile = sc.textFile("data.txt")
distFile:RDD[String]= MappedRDD@1D4CEE08
distFile.map(s =>s.length).reduce((a+b) =>a+b)
虽然还有别的方式可以创建RDD,但在本文中我们主要使用上述两种方式来创建RDD以说明RDD的API.
下面带给大家一个WordCount例子的图解
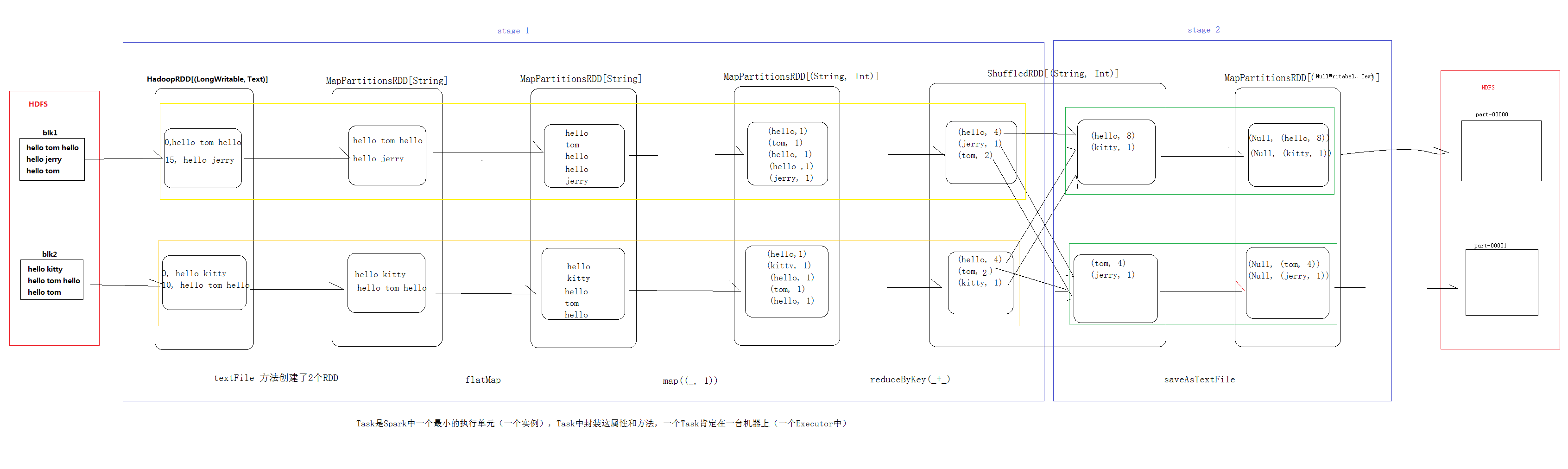
分区和分区器的区别:
分区代表并行度,分区越多,并行度越高,一个分区相当于一个task
自定义分区器,决定了在shuffle时候,上游的数据要到下游的哪一个分区
数据均匀分散在多个分区里,每个分区会对应一个task进行计算

在这里,再次描述Spark任务执行流程:
1.把一个Spark程序打成一个Jar包,然后用spark-submit运行,提交到集群 --> Application
2.RDD经过一些转换后,触发Action,这样就形成一个完整的DAG --> Job
3.对DAG根据窄宽依赖(shuffle)进行切分,会生成很多阶段 --> Stage
4.一个Stage会生成多个任务(任务就是一个Java实例,里面有属性和方法)--> Task
注:Task是Spark中最小的执行单元,在资源充足的情况下,Task数量越多(并行),任务执行的越快
Task中方法的计算逻辑是串行的(严格遵循调用顺序)
一个Job(DAG)可以有一个到多个Stage,Stage的提交,要严格的按照先后顺序
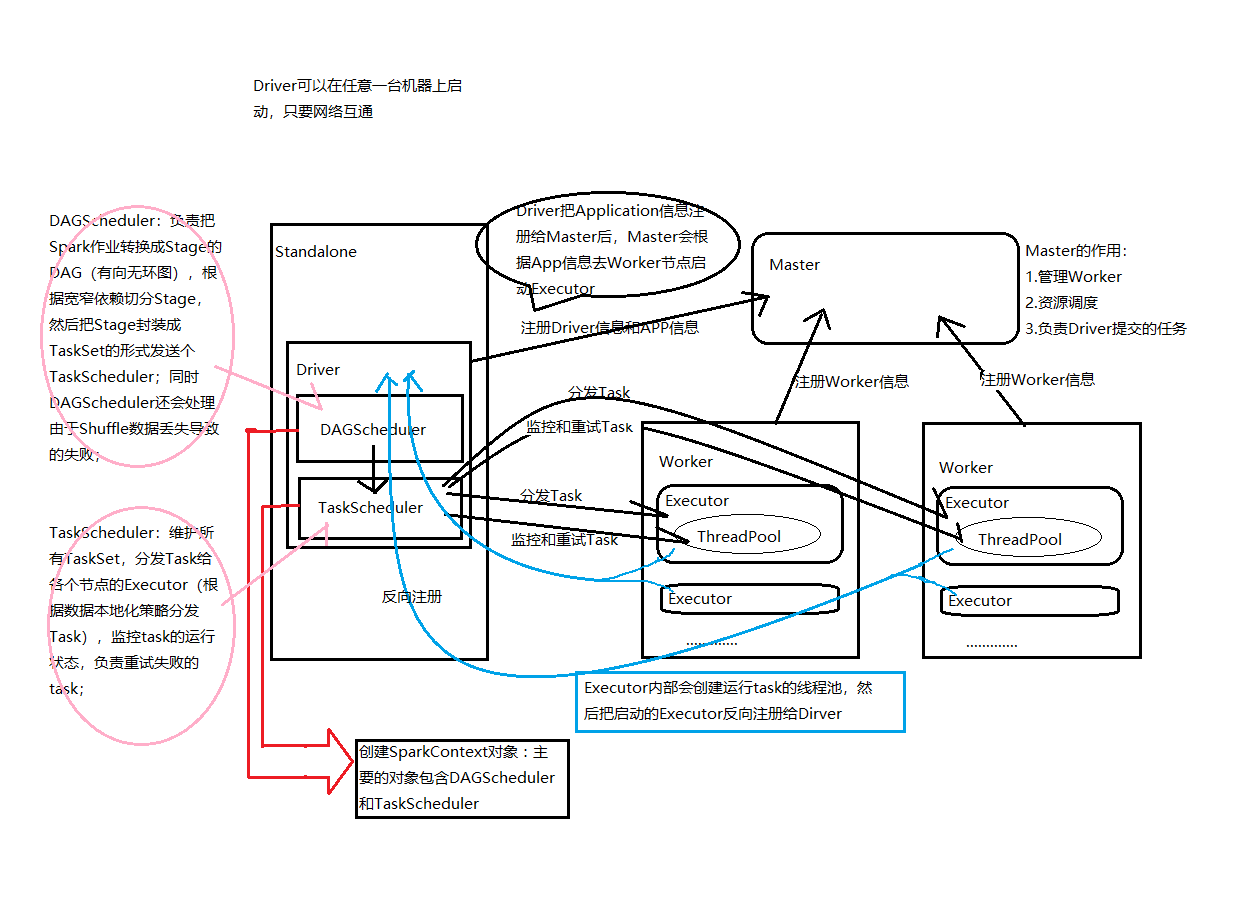
具体流程
1、构建DAG:DAGScheduler负责把Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图)
2、DAGScheduler根据宽窄依赖切分Stage,然后把Stage封装成TaskSet的形式发送个TaskScheduler;
3、TaskScheduler:维护所有TaskSet,分发Task给各个节点的Executor,spark在提交Application时,可以指定总共占用的内核数(可以简单理解为线程数量),同时也可以指定task的数量,一个task占用一个线程,如果,task的数量大于内核的数量,则没有占用到内核的task会等待其他的task执行完毕,释放资源后,再占用。(原谅我举个不雅的例子,仔细想有没有就像厕所入坑的一样,所有坑被占用时,其他人会等待....)
4、excutor根据数据本地化策略分发Task到线程池,开始执行run方法
5、TaskScheduler监控task的运行状态,负责重试失败的task;
6、所有task运行完成后,SparkContext向Master注销,释放资源;
那么现在我们理解了RDD,也理解了Spark执行流程,最后,我们再把RDD放在流程中,相信你可以有所收获的
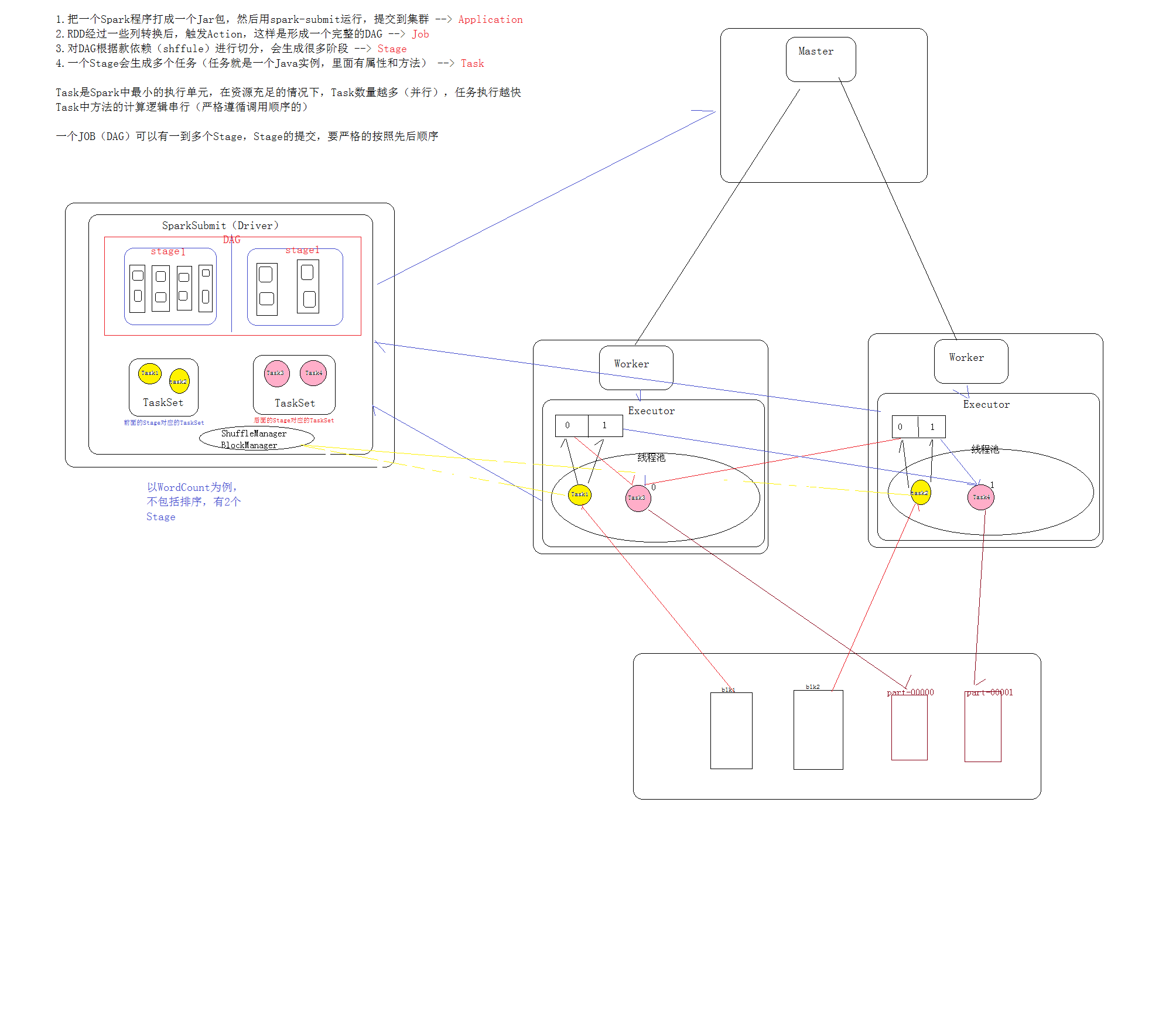
坚持资源共享的原则,写的有错的地方多谢指正。。。。。
深入理解RDD原理的更多相关文章
- node.js学习(三)简单的node程序&&模块简单使用&&commonJS规范&&深入理解模块原理
一.一个简单的node程序 1.新建一个txt文件 2.修改后缀 修改之后会弹出这个,点击"是" 3.运行test.js 源文件 使用node.js运行之后的. 如果该路径下没有该 ...
- Atitit 图像处理 深刻理解梯度原理计算.v1 qc8
Atitit 图像处理 深刻理解梯度原理计算.v1 qc8 1.1. 图像处理 梯度计算 基本梯度 内部梯度 外部梯度 方向梯度1 2. 图像梯度就是图像边缘吗?2 1.1. 图像处理 梯度计算 ...
- 深入理解PHP原理之变量作用域
26 Aug 08 深入理解PHP原理之变量作用域(Scope in PHP) 作者: Laruence( ) 本文地址: http://www.laruence.com/2008/08/26 ...
- 深入理解PHP原理之变量分离/引用
19 Sep 08 深入理解PHP原理之变量分离/引用(Variables Separation) 作者: Laruence( ) 本文地址: http://www.laruence.com/20 ...
- 《深入理解mybatis原理》 MyBatis事务管理机制
MyBatis作为Java语言的数据库框架,对数据库的事务管理是其很重要的一个方面.本文将讲述MyBatis的事务管理的实现机制. 首先介绍MyBatis的事务Transaction的接口设计以及其不 ...
- 《深入理解mybatis原理》 Mybatis初始化机制具体解释
对于不论什么框架而言.在使用前都要进行一系列的初始化,MyBatis也不例外. 本章将通过下面几点具体介绍MyBatis的初始化过程. 1.MyBatis的初始化做了什么 2. MyBatis基于XM ...
- 《深入理解mybatis原理》 MyBatis的架构设计以及实例分析
作者博客:http://blog.csdn.net/u010349169/article/category/2309433 MyBatis是目前非常流行的ORM框架,它的功能很强大,然而其实现却比较简 ...
- 轻松理解Redux原理及工作流程
轻松理解Redux原理及工作流程 Redux由Dan Abramov在2015年创建的科技术语.是受2014年Facebook的Flux架构以及函数式编程语言Elm启发.很快,Redux因其简单易学体 ...
- 深入理解mybatis原理, Mybatis初始化SqlSessionFactory机制详解(转)
文章转自http://blog.csdn.net/l454822901/article/details/51829785 对于任何框架而言,在使用前都要进行一系列的初始化,MyBatis也不例外.本章 ...
随机推荐
- Codeforces Round #486 (Div. 3) F. Rain and Umbrellas
Codeforces Round #486 (Div. 3) F. Rain and Umbrellas 题目连接: http://codeforces.com/group/T0ITBvoeEx/co ...
- ASP.NET WebApi JObject 使用
ASP.NET WebApi 中使用非Get请求,传递参数需要用对象包裹起来,比如: [HttpPost] public async Task<IActionResult> PostVal ...
- 一个简单的将Markdown二级标题进行排序的脚本
我在写博客<Linux的1000个命令>的时候,相对二级标题进行一下排序,方便阅读和查找,于是就有了这个小程序. #! /usr/bin/env python3 import os imp ...
- 记web模拟手机环境已经微信开发者工具中可正常运行,实体机运行报错问题
问题描述: 有个手机微信OA的项目 用户信息采用cookie方式保存.发布后使用chorme浏览器进行模拟访问测试发现一切运行顺畅,使用微信开发者工具进行测试也一切正常. 采用实体机进行测试时,用微信 ...
- Mybatis框架三:DAO层开发、Mapper动态代理开发
这里是最基本的搭建:http://www.cnblogs.com/xuyiqing/p/8600888.html 接下来做到了简单的增删改查:http://www.cnblogs.com/xuyiqi ...
- Linux - 获取命令帮助信息
Manual Page Chapter List 1:所有用户可以操作的指令或可执行文件 2:系统核心调用的函数与工具 3:子调用,常用的函数与函数库 4:设备,硬件文件说明,通常是/dev/的文件 ...
- underscore.js源码解析【函数】
// Function (ahem) Functions // ------------------ // Determines whether to execute a function as a ...
- 前端进击的巨人(六):知否知否,须知this
常见this的误解 指向函数自身(源于this英文意思的误解) 指向函数的词法作用域(部分情况) this的应用环境 1. 全局环境 无论是否在严格模式下,全局执行环境中(任何函数体外部)this都指 ...
- python3中的range函数返回的是列表吗?
注意,这里说的Python3里面的range函数,和Python2是不同的,返回的不是列表,是可迭代对象. 在python3中,如果执行下面的语句 print(range(10)) 得到结果是 ran ...
- Spring Cloud Gateway入门
1.什么是Spring Cloud GatewaySpring Cloud Gateway是Spring官方基于Spring 5.0,Spring Boot 2.0和Project Reactor等技 ...