spark streaming 实战
最近在学习spark的相关知识, 重点在看spark streaming 和spark mllib相关的内容。
关于spark的配置: http://www.powerxing.com/spark-quick-start-guide/
这篇博客写的很全面:http://www.liuhaihua.cn/archives/134765.html
spark streaming:
是spark系统中处理流数据的分布式流处理框架,能够以最低500ms的时间间隔对流数据进行处理,延迟大概1s左右,
是一个准实时的流处理框架。
spark streaming 可以和 spark SQL、MLlib 和GraphX相结合,共同完成基于实时处理的复杂系统。
spark steaming 的原理:

如上图所示, spark streaming 将输入的数据按时间分割为若干段,每一段对应以恶spark job, 最后将处理后的任务按返回,就像流水一样。
DStram:
是 Spark Streaming 对内部持续的实时数据流的抽象描述,即我们处理的一个实时数据流,在 Spark Streaming 中对应于一个 DStream 实例,
通俗的讲Dstream 一系列是RDD的集合。
spark Streaming 编程模型:
DStream ( Discretized Stream )作为 Spark Streaming 的基础抽象,它代表持续性的数据流。这些数据流既可以通过外部输入源赖获取,也可以通过现有的 Dstream 的 transformation 操作来获得。在内部实现上, DStream 由一组时间序列上连续的 RDD 来表示。每个 RDD 都包含了自己特定时间间隔内的数据流, 如下图所示:

而对DStream 的操作,也是映射到其内部的RDD上的,如下图,通过转换操作生存新的DStram:

spark Streaming 的三种运行场景:
1. 无状态操作
2. 有状态操作(updateStateByKey)
3. window操作
接下来分别说明。

无状态操作:每次计算的时间,仅仅计算当前时间切片的内容,如,每次只计算1s时间内产生的RDD
有状态操作:不断的把当前的计算和历史时间切片的RDD进行累计,如,计算某个单词出现的次数,需要把当前的状态与历史的状态相累加,随着时间的流逝, 数据规模会越来越大
基于window的操作:针对特定的时间段,并以特定的时间间隔为单位的滑动操作,如每隔10秒,统计一下过去30秒过来的数据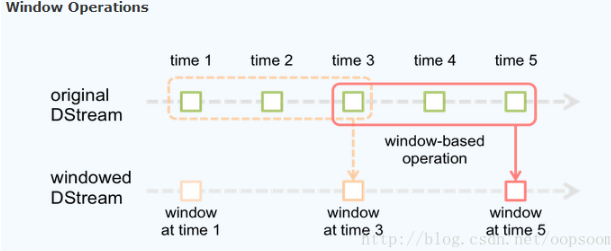
如上图,红色的圈代表一个window,里面包含3个时间,并且window 每隔2个时间滑动一次,因此:
所以基于窗口的操作,需要指定2个参数:
- window length - The duration of the window (3 in the figure)
- slide interval - The interval at which the window-based operation is performed (2 in the figure).
编程实战:
官方提供的wordCount的实例:
package org.apache.spark.examples.streaming import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.storage.StorageLevel /**
* Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
*
* Usage: NetworkWordCount <hostname> <port>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
*
* To run this on your local machine, you need to first run a Netcat server
* `$ nc -lk 9999`
* and then run the example
* `$ bin/run-example org.apache.spark.examples.streaming.NetworkWordCount localhost 9999`
*/
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < ) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit()
} StreamingExamples.setStreamingLogLevels() // Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds()) // Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
val lines = ssc.socketTextStream(args(), args().toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, )).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
首先运行
nc -lk 9999
然后打开另一个窗口,在spark的目录下 运行
./bin/run-example streaming.NetworkWordCount localhost 9999
spark streaming 实战的更多相关文章
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
- Spark Streaming实战
1.Storm 和 SparkStreaming区别 Storm 纯实时的流式处理,来一条数据就立即进行处理 SparkStreaming 微批处理,每次处理 ...
- 倾情大奉送--Spark入门实战系列
这一两年Spark技术很火,自己也凑热闹,反复的试验.研究,有痛苦万分也有欣喜若狂,抽空把这些整理成文章共享给大家.这个系列基本上围绕了Spark生态圈进行介绍,从Spark的简介.编译.部署,再到编 ...
- 《大数据Spark企业级实战 》
基本信息 作者: Spark亚太研究院 王家林 丛书名:决胜大数据时代Spark全系列书籍 出版社:电子工业出版社 ISBN:9787121247446 上架时间:2015-1-6 出版日期:20 ...
- Spark入门实战系列
转自:http://www.cnblogs.com/shishanyuan/p/4699644.html 这一两年Spark技术很火,自己也凑热闹,反复的试验.研究,有痛苦万分也有欣喜若狂,抽空把这些 ...
- 日志=>flume=>kafka=>spark streaming=>hbase
日志=>flume=>kafka=>spark streaming=>hbase 日志部分 #coding=UTF-8 import random import time ur ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二十一之铭文升级版
铭文一级: DataV功能说明1)点击量分省排名/运营商访问占比 Spark SQL项目实战课程: 通过IP就能解析到省份.城市.运营商 2)浏览器访问占比/操作系统占比 Hadoop项目:userA ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十八之铭文升级版
铭文一级: 功能二:功能一+从搜索引擎引流过来的 HBase表设计create 'imooc_course_search_clickcount','info'rowkey设计:也是根据我们的业务需求来 ...
随机推荐
- JavaScript学习中的挑战
当人们尝试学习 JavaScript , 或者其他编程技术的时候,常常会遇到同样的挑战: 有些概念容易混淆,特别是当你学习过其他语言的时候.很难找到学习的时间(有时候是动力).一旦当你理解了一些东西的 ...
- #MySQL for Python(MySQLdb) Note
#MySQL for Python(MySQLdb) Note #切记不要在python中创建表,只做增删改查即可. #步骤:(0)引用库 -->(1)创建连接 -->(2)创建游标 -- ...
- tomcat内存溢出 PermGen space
1. java.lang.OutOfMemoryError: PermGen space ---- PermGen space溢出. PermGen space的全称是Permanent Gene ...
- 使用 dynamic 标记解析JSON字符串
string jsonStr = "{\"data\": {\"ssoToken\": \"70abd3d8a6654ff189c482fc ...
- tar
必要参数有如下: -A 新增压缩文件到已存在的压缩 -B 设置区块大小 -c 建立新的压缩文件 -d 记录文件的差别 -r 添加文件到已经压缩的文件 -u 添加改变了和现有的文件到已经存在的压缩文件 ...
- Python decode与encode
字符串在Python内部的表示是unicode编码(8-bit string),因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicod ...
- 从jsTree演示代码中提取的在线文件查看
从jsTree演示代码中提取的在线文件查看 jsTree 请参考:https://www.jstree.com/ 效果如下: 代码下载:http://files.cnblogs.com/files/z ...
- 【支付专区】之对字符串数据进行Base64位加密,解密
加密,解密 String pwd="测试"; byte[] bytes = pwd.getBytes("UTF-8"); //加密 String pwdNew= ...
- Java事务处理全解析(七)—— 像Spring一样使用Transactional注解(Annotation)
在本系列的上一篇文章中,我们讲到了使用动态代理的方式完成事务处理,这种方式将service层的所有public方法都加入到事务中,这显然不是我们需要的,需要代理的只是那些需要操作数据库的方法.在本篇中 ...
- Android学习笔记(五)
Intent不仅用来启动一个活动,Intent还可以在启动活动的时候传递参数. 1.向下一个活动传递数据 启动活动的时候传递数据,Intent提供了一系列putExtra()方法的重载,可以把要传递的 ...