【faster-rcnn】训练自己的数据集时的坑
注:本文写于早期学习摸索阶段,不免有错误、不到位的理解,仅用做遇到相同错误的人参考。后续一直在使用RBG大神的py-faster-rcnn。
既然faster-rcnn原版发表时候是matlab版代码,那就用matlab版代码吧!不过遇到的坑挺多的,不知道python版会不会好一点。
======= update =========
总体上包括这些步骤,请注意检查:
1 获取数据;(标准数据集/比赛数据/自行收集数据)
2 整理图片名和标注信息格式、指定训练集和测试集;(转voc格式,同时记得修改vocinit.m中类别信息;或者自己修改代码中读取数据的地方)
3 正确使用均值图像:手动算一个或用默认的减去128,别用错
4 选择网络与设定网络参数(solver和net);(根据业务需求和显存大小设定;修改网络中目标类别数量)
5 检查batch_size;
6 检查anchor;
7 清空cache目录;
8 开始训练;
9 确保电脑供电且不会休眠睡眠;
10 执行测试;整理测试结果
======= update =========
anyway,这里记录一下我遇到的几个错误和解决办法
这里假设你已经配置好了faster-rcnn。我是在win10下配置的,显卡GTX 970,使用ZF网络。
0. 准备数据集
官方训练时用的是voc2007系列数据,那就转换成这个系列的好了,主要包括:0.下载数据集 1.整理图片 2.xml格式的annotation文件 3.txt格式指定训练集、测试集、验证集、训练验证集,以及每个类别各自的这四种文件
0.0 下载数据集
看具体情况,比如做某个比赛,那就下载;如果是自己收集的数据集,那就统一放到一起
0.1 整理图片
主要是图片格式统一,比如都是png
以及,命名规范,比如统一是6位长度的数字:000001.png,并且序号是连续的
训练图片和测试图片都放在一个JPEGImages目录里
0.2 xml格式的annotation文件
其实voc2007这种方式:为每张图片编写一个xml文件,记录图片各种元信息(作者、文件名、宽度高度深度、来源),以及bounding box坐标信息(左上、右下定点)等,很蛋疼啊,图片多的话每次处理xml文件读写I/O就增大了。anyway,遵守标准的好处是省的自己造各种工具。
这里贴一个例子好了,000001.xml:
<annotation>
<folder>VOC2007</folder>
<filename>000001.png</filename>
<source>
<database>My Database</database>
<annotation>VOC2007</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>chriszz</name>
</owner>
<size>
<width>1280</width>
<height>720</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>369</xmin>
<ymin>403</ymin>
<xmax>409</xmax>
<ymax>418</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>434</xmin>
<ymin>375</ymin>
<xmax>443</xmax>
<ymax>401</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>461</xmin>
<ymin>368</ymin>
<xmax>471</xmax>
<ymax>395</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>571</xmin>
<ymin>473</ymin>
<xmax>593</xmax>
<ymax>490</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>674</xmin>
<ymin>470</ymin>
<xmax>683</xmax>
<ymax>478</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>693</xmin>
<ymin>471</ymin>
<xmax>714</xmax>
<ymax>480</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>976</xmin>
<ymin>413</ymin>
<xmax>998</xmax>
<ymax>438</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1004</xmin>
<ymin>396</ymin>
<xmax>1011</xmax>
<ymax>410</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1024</xmin>
<ymin>388</ymin>
<xmax>1031</xmax>
<ymax>405</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1046</xmin>
<ymin>388</ymin>
<xmax>1071</xmax>
<ymax>406</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1114</xmin>
<ymin>390</ymin>
<xmax>1143</xmax>
<ymax>410</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>913</xmin>
<ymin>431</ymin>
<xmax>928</xmax>
<ymax>458</ymax>
</bndbox>
</object>
</annotation>
记得所有xml文件的文件名要和图片序号一一对应:000001.xml对应000001.png
并且,所有xml文件放到Annotations目录中
0.3 txt文件指定训练集、测试集等
在ImageSets/Main目录下保存这些文件。比如我的任务是检测交通标识,只有一个类别需要检测,或者说是二分类问题,只需要判断一个bbox区域是否为交通标识(sign),那么我创建sign对应的4个文件;以及4个表示总体的训练、验证、训练验证、测试的txt文件:
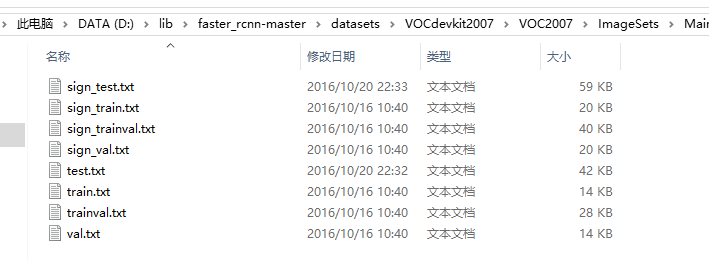
其中,sign_train、sign_test、sign_trainval、sign_val每行格式相同
图片id(不带后缀,不用全路径) +1或-1(表示这张图片中是否包含sign类别的区域)
对于我的情况,类别标签都是+1
然后是train、val、trainval、test文件,其中trainval是train和val的拼接。
这里我是需要
1 修改faster-rcnn的几个代码细节
1.0 experiments\script_faster_rcnn_VOC2007_ZF.m第30、31行
这里默认居然是用select search生成region proposal,我也是醉了。
改成:
dataset = Dataset.voc2007_trainval(dataset, 'train', use_flipped);
dataset = Dataset.voc2007_test(dataset, 'test', false);
1.1 experiments\+Dataset\voc2007_test.m第11行、第14行,test改成val
这个真的是太坑了,在这里我卡了大半天。为什么会卡在这个地方,然后程序一直运行出错呢?以及,程序出错大概如下:
错误使用 proposal_prepare_image_roidb>scale_rois (line 110) 两个输入数组的单一维度必须相互匹配,...
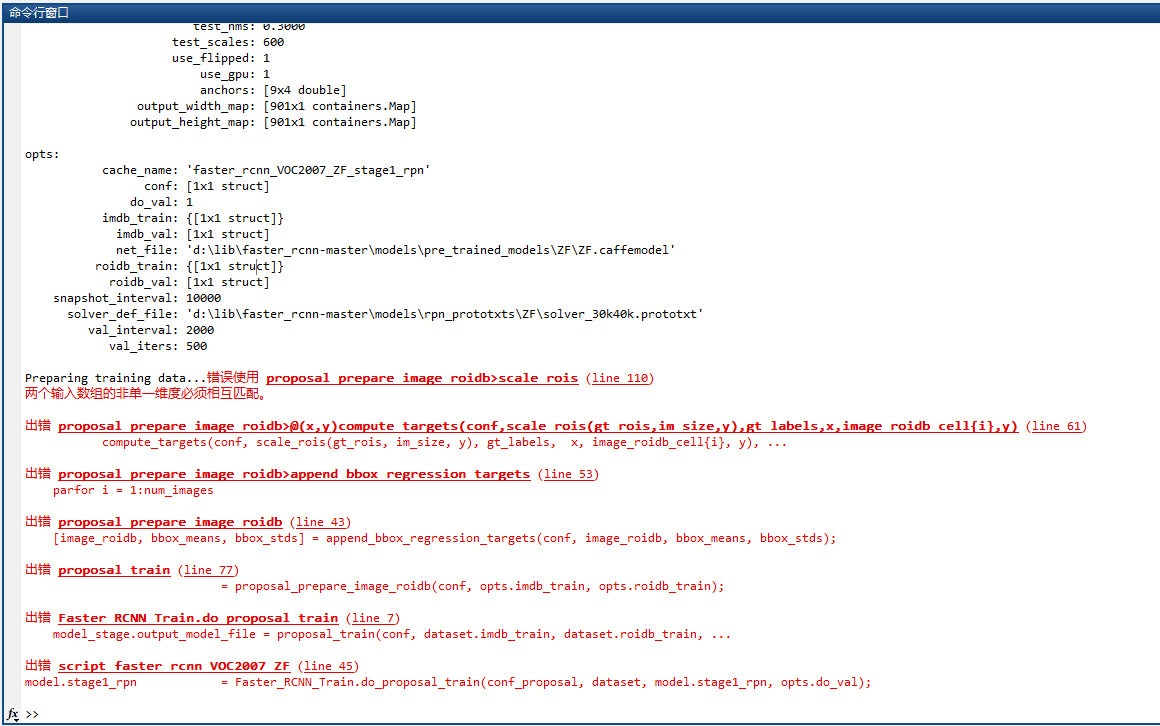
设断点debug后发现,roidb_train里各种字段都有值(比如gt、坐标、阈值、类别等);而roidb_val里面是空的。
实际上是在experiments\+Faster_RCNN_Train\do_proposal_train.m里面,把dataset.roidb_test赋值给roidb_val了:
function model_stage = do_proposal_train(conf, dataset, model_stage, do_val)
if ~do_val
dataset.imdb_test = struct();
dataset.roidb_test = struct();
end
model_stage.output_model_file = proposal_train(conf, dataset.imdb_train, dataset.roidb_train, ...
'do_val', do_val, ...
'imdb_val', dataset.imdb_test, ...
'roidb_val', dataset.roidb_test, ... # 尼玛,在这里赋值了
'solver_def_file', model_stage.solver_def_file, ...
'net_file', model_stage.init_net_file, ...
'cache_name', model_stage.cache_name);
end
问题就是在这里了,不多说。那么接下来就是把experiments\+Dataset\voc2007_test.m第11行、第14行,test改成val,保证以后在imdb\cache目录下有val的mat数据存在,roidb_val也不会说里面内容都为空的了。
2 修改网络参数
看到下面这张图应该知道要改那几个文件了:
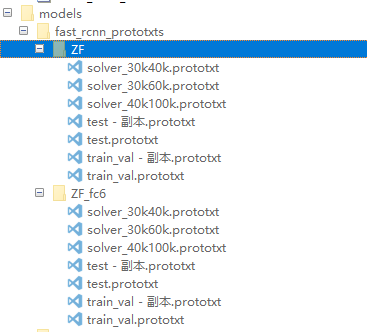
具体可以参考小咸鱼的faster-rcnn matlab版的配置
【faster-rcnn】训练自己的数据集时的坑的更多相关文章
- faster rcnn训练自己的数据集
采用Pascal VOC数据集的组织结构,来构建自己的数据集,这种方法是faster rcnn最便捷的训练方式
- Fast R-CNN训练自己的数据集时遇到的报错及解决方案
最近使用Fast R-CNN训练了实验室的数据集,期间遇到一些报错,主要还是在配置环境上比较麻烦,但可以根据提示在网上找到解决这些错误的办法.这里我只记录一些难改的报错,以后再遇见这些时希望能尽快解决 ...
- Faster Rcnn训练自己的数据集过程大白话记录
声明:每人都有自己的理解,动手实践才能对细节更加理解! 一.算法理解 此处省略一万字.................. 二.训练及源码理解 首先配置: 在./lib/utils文件下....运行 p ...
- caffe学习三:使用Faster RCNN训练自己的数据
本文假设你已经完成了安装,并可以运行demo.py 不会安装且用PASCAL VOC数据集的请看另来两篇博客. caffe学习一:ubuntu16.04下跑Faster R-CNN demo (基于c ...
- 如何才能将Faster R-CNN训练起来?
如何才能将Faster R-CNN训练起来? 首先进入 Faster RCNN 的官网啦,即:https://github.com/rbgirshick/py-faster-rcnn#installa ...
- Fast RCNN 训练自己的数据集(3训练和检测)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https://github.com/YihangLou/fas ...
- python3 + Tensorflow + Faster R-CNN训练自己的数据
之前实现过faster rcnn, 但是因为各种原因,有需要实现一次,而且发现许多博客都不全面.现在发现了一个比较全面的博客.自己根据这篇博客实现的也比较顺利.在此记录一下(照搬). 原博客:http ...
- faster rcnn训练详解
http://blog.csdn.net/zy1034092330/article/details/62044941 py-faster-rcnn训练自己的数据:流程很详细并附代码 https://h ...
- caffe 用faster rcnn 训练自己的数据 遇到的问题
1 . 怎么处理那些pyx和.c .h文件 在lib下有一些文件为.pyx文件,遇到不能import可以cython 那个文件,然后把lib文件夹重新make一下. 遇到.c 和 .h一样的操作. 2 ...
随机推荐
- Apache配置中的ProxyPass 和 ProxyPassReverse
apache中的mod_proxy模块用于url的转发,即具有代理的功能.应用此功能,可以很方便的实现同tomcat等应用服务器的整合,甚者可以很方便的实现web集群的功能. 例如使用apache作为 ...
- 在C#中将String转换成Enum:
一: 在C#中将String转换成Enum: object Enum.Parse(System.Type enumType, string value, bool ignoreCase); 所以,我 ...
- Jquery操作下拉框(DropDownList)实现取值赋值
Jquery操作下拉框(DropDownList)想必大家都有所接触吧,下面与大家分享下对DropDownList进行取值赋值的实现代码 1. 获取选中项: 获取选中项的Value值: $('sele ...
- android:ToolBar详解(手把手教程)(转)
来源 http://blog.mosil.biz/2014/10/android-toolbar/ 编辑推荐:稀土掘金,这是一个针对技术开发者的一个应用,你可以在掘金上获取最新最优质的技术干货,不仅仅 ...
- Linux shell实战(ipcs工具)
#!/bin/bash -o $# -gt ] then echo "参数个数不正确!" exit - fi WHOAIM=`whoami` function release { ...
- ReactNative真机运行指南
ReactNative真机运行指南 注意在iOS设备上运行React Native应用需要一个Apple Developer account并且把你的设备注册为测试设备.本向导只包含React Nat ...
- 跟我学习Storm_Storm简介
Storm是由专业数据分析公司BackType开发的一个分布式实时数据处理软件,可以简单.高效.可靠地处理大量的数据流.Twitter在2011年7月收购该公司,并于2011年9月底正式将Storm项 ...
- HomeKit 与老旧设备
苹果推了HomeKit,已经有很多厂商在做,可以达到Siri控制所有设备的功能. 但是Siri也不是万能的,对人类的语义理解也会产生差错,不过我相信未来这个问题会解决掉. 如果家里有老旧的电视 ...
- 怎样修改 Openstack Horizon(Dashboard)的显示界面 (二)
上一篇文章介绍了 Dashboard 的基本结构框架,那接下来的问题就是如何在这个框架中加入我们自己想要的内容了.在真正动手之前,让我们先来看看官方的页面是怎么做出来的.首先我们进入 /usr/sha ...
- 学堂在线 UWP 首版
好久没有写博客了,主要是最近在写一个小小的App.<( ̄︶ ̄)> 不知道看各位有木有爱看慕课的,作为一名资深的大三学渣的我有看慕课的习惯.一直在看学堂在线的慕课,感觉质量确实还可以,但是遗 ...