HashMap在并发下可能出现的问题分析
我们都知道,HashMap在并发环境下使用可能出现问题,但是具体表现,以及为什么出现并发问题,
可能并不是所有人都了解,这篇文章记录一下HashMap在多线程环境下可能出现的问题以及如何避免。
在分析HashMap的并发问题前,先简单了解HashMap的put和get基本操作是如何实现的。
1.HashMap的put和get操作
大家知道HashMap内部实现是通过拉链法解决哈希冲突的,也就是通过链表的结构保存散列到同一数组位置的两个值,
put操作主要是判空,对key的hashcode执行一次HashMap自己的哈希函数,得到bucketindex位置,还有对重复key的覆盖操作。
对照源码分析一下具体的put操作是如何完成的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
//得到key的hashcode,同时再做一次hash操作
int hash = hash(key.hashCode());
//对数组长度取余,决定下标位置
int i = indexFor(hash, table.length);
/**
* 首先找到数组下标处的链表结点,
* 判断key对一个的hash值是否已经存在,如果存在将其替换为新的value
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
涉及到的几个方法:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
数据put完成以后,就是如何get,我们看一下get函数中的操作:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
/**
* 先定位到数组元素,再遍历该元素处的链表
* 判断的条件是key的hash值相同,并且链表的存储的key值和传入的key值相同
*/
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
看一下链表的结点数据结构,保存了四个字段,包括key,value,key对应的hash值以及链表的下一个节点:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;//Key-value结构的key
V value;//存储值
Entry<K,V> next;//指向下一个链表节点
final int hash;//哈希值
}
2.Rehash/再散列扩展内部数组长度
哈希表结构是结合了数组和链表的优点,在最好情况下,查找和插入都维持了一个较小的时间复杂度O(1),
不过结合HashMap的实现,考虑下面的情况,如果内部Entry[] tablet的容量很小,或者直接极端化为table长度为1的场景,那么全部的数据元素都会产生碰撞,
这时候的哈希表成为一条单链表,查找和添加的时间复杂度变为O(N),失去了哈希表的意义。
所以哈希表的操作中,内部数组的大小非常重要,必须保持一个平衡的数字,使得哈希碰撞不会太频繁,同时占用空间不会过大。
这就需要在哈希表使用的过程中不断的对table容量进行调整,看一下put操作中的addEntry()方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
这里面resize的过程,就是再散列调整table大小的过程,默认是当前table容量的两倍。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//初始化一个大小为oldTable容量两倍的新数组newTable
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
关键的一步操作是transfer(newTable),这个操作会把当前Entry[] table数组的全部元素转移到新的table中,
这个transfer的过程在并发环境下会发生错误,导致数组链表中的链表形成循环链表,在后面的get操作时e = e.next操作无限循环,Infinite Loop出现。
下面具体分析HashMap的并发问题的表现以及如何出现的。
3.HashMap在多线程put后可能导致get无限循环
HashMap在并发环境下多线程put后可能导致get死循环,具体表现为CPU使用率100%,
看一下transfer的过程:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
//假设第一个线程执行到这里因为某种原因挂起
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
这里引用酷壳陈皓的博文:
并发下的Rehash
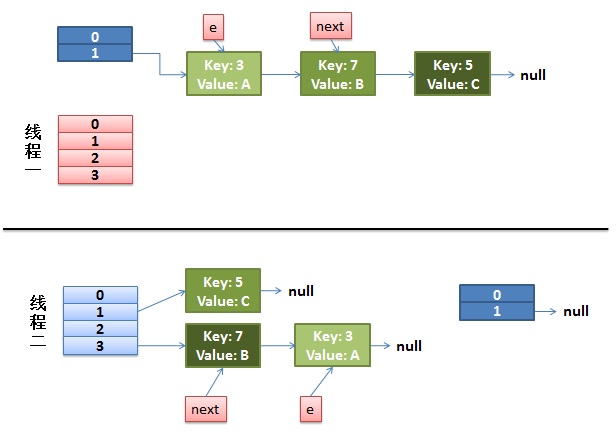
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
do{Entry<K,V> next = e.next;// <--假设线程一执行到这里就被调度挂起了inti = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}while(e !=null);而我们的线程二执行完成了。于是我们有下面的这个样子。
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
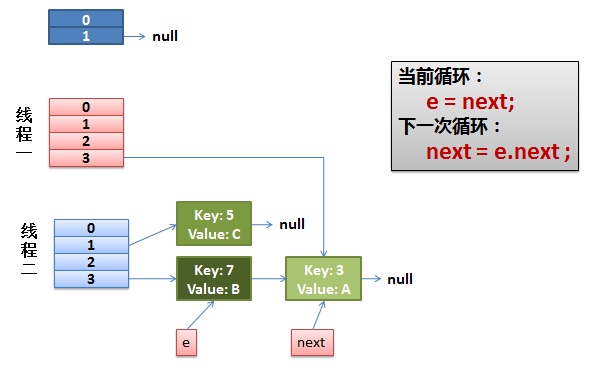
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
3)一切安好。
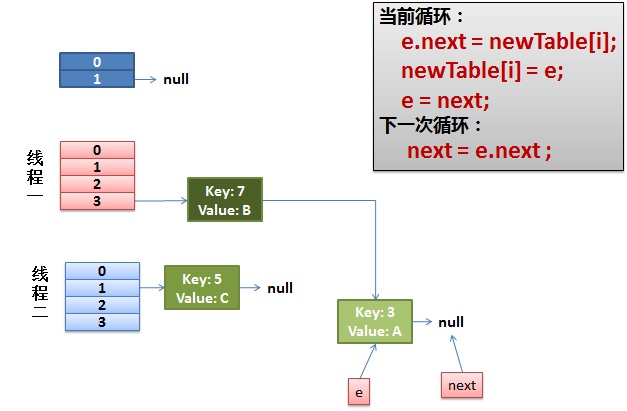
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
4)环形链接出现。
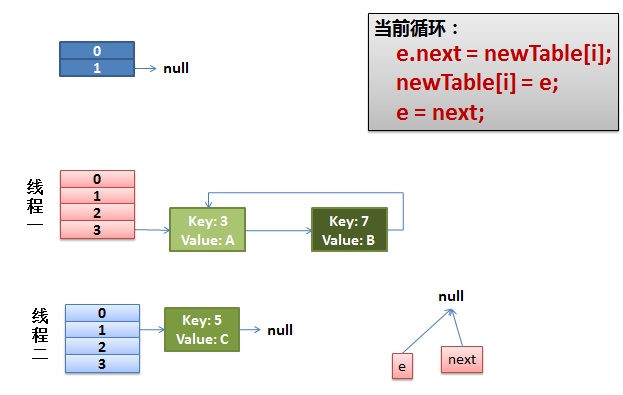
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
针对上面的分析模拟这个例子,
这里在run中执行了一个自增操作,i++非原子操作,使用AtomicInteger避免可能出现的问题:
public class MapThread extends Thread{
/**
* 类的静态变量是各个实例共享的,因此并发的执行此线程一直在操作这两个变量
* 选择AtomicInteger避免可能的int++并发问题
*/
private static AtomicInteger ai = new AtomicInteger(0);
//初始化一个table长度为1的哈希表
private static HashMap<Integer, Integer> map = new HashMap<Integer, Integer>(1);
//如果使用ConcurrentHashMap,不会出现类似的问题
// private static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<Integer, Integer>(1);
public void run()
{
while (ai.get() < 100000)
{ //不断自增
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
System.out.println(Thread.currentThread().getName()+"线程即将结束");
}
}
测试一下:
public static void main(String[] args){
MapThread t0 = new MapThread();
MapThread t1 = new MapThread();
MapThread t2 = new MapThread();
MapThread t3 = new MapThread();
MapThread t4 = new MapThread();
MapThread t5 = new MapThread();
MapThread t6 = new MapThread();
MapThread t7 = new MapThread();
MapThread t8 = new MapThread();
MapThread t9 = new MapThread();
t0.start();
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
}
注意并发问题并不是一定会产生,可以多执行几次,
我试验了上面的代码很容易产生无限循环,控制台不能终止,有线程始终在执行中,
这是其中一个死循环的控制台截图,可以看到六个线程顺利完成了put工作后销毁,还有四个线程没有输出,卡在了put阶段,感兴趣的可以断点进去看一下:
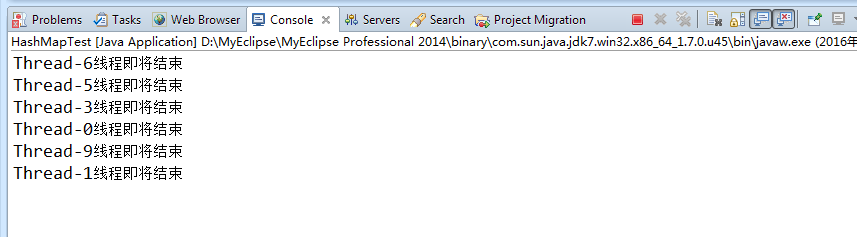
上面的代码,如果把注释打开,换用ConcurrentHashMap就不会出现类似的问题。
4.多线程put的时候可能导致元素丢失
HashMap另外一个并发可能出现的问题是,可能产生元素丢失的现象。
考虑在多线程下put操作时,执行addEntry(hash, key, value, i),如果有产生哈希碰撞,
导致两个线程得到同样的bucketIndex去存储,就可能会出现覆盖丢失的情况:
void addEntry(int hash, K key, V value, int bucketIndex) {
//多个线程操作数组的同一个位置
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
5.使用线程安全的哈希表容器
那么如何使用线程安全的哈希表结构呢,这里列出了几条建议:
使用Hashtable 类,Hashtable 是线程安全的;
使用并发包下的java.util.concurrent.ConcurrentHashMap,ConcurrentHashMap实现了更高级的线程安全;
或者使用synchronizedMap() 同步方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作。
HashMap在并发下可能出现的问题分析的更多相关文章
- java-通过 HashMap、HashSet 的源码分析其 Hash 存储机制
通过 HashMap.HashSet 的源码分析其 Hash 存储机制 集合和引用 就像引用类型的数组一样,当我们把 Java 对象放入数组之时,并非真正的把 Java 对象放入数组中.仅仅是把对象的 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- HashMap实现原理及源码分析之JDK8
继续上回HashMap的学习 HashMap实现原理及源码分析之JDK7 转载 Java8源码-HashMap 基于JDK8的HashMap源码解析 [jdk1.8]HashMap源码分析 一.H ...
- 每天学会一点点(HashMap实现原理及源码分析)
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希 ...
- HashMap高并发下存在的问题
原文链接:https://blog.csdn.net/bjwfm2011/article/details/81076736 1.什么是HashMap? HashMap底层原理 HashMap是存储键值 ...
- HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- HashMap实现原理及源码分析(JDK1.7)
转载:https://www.cnblogs.com/chengxiao/p/6059914.html 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技 ...
- Java7/8 中 HashMap 和 ConcurrentHashMap的对比和分析
大家可能平时用HashMap比较多,相对于ConcurrentHashMap 来说并不是很熟悉.ConcurrentHashMap 是 JDK 1.5 添加的新集合,用来保证线程安全性,提升 Map ...
- HashMap实现原理及源码分析之JDK7
攻克集合第一关!! 转载 http://www.cnblogs.com/chengxiao/ 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如m ...
随机推荐
- lintcode 447 Search in a Big Sorted Array
Given a big sorted array with positive integers sorted by ascending order. The array is so big so th ...
- leetcode 142. Linked List Cycle II
Given a linked list, return the node where the cycle begins. If there is no cycle, return null. Note ...
- c++ 操作符重载和友元
操作符重载(operator overloading)是C++中的一种多态,C++允许用户自定义函数名称相同但参数列表不同的函数,这被称为函数重载或函数多态.操作符重载函数的格式一般为: operat ...
- Codeforces Gym 101138 D. Strange Queries
Description 给你一下长度为 \(n\) 的序列. \(a_i=a_j\) \(l_1 \leqslant i \leqslant r_1\) \(l_2 \leqslant i \leqs ...
- BZOJ 2412: 电路检修
Description [0,x]中全是1,其余全是0,每个点有一个权值,求最坏情况下得到x的最小权值. Sol DP+单调队列. 你可以去看我的这篇Blog...开这篇纯属为了骗访问... http ...
- PyQt4自定义事件
listview控件与updateText 相关联 self.listview.updateText.connect(self.viewlist) updateText = QtCore.pyqt ...
- 通过Nginx和Nginx Plus阻止DDoS攻击
分布式拒绝服务攻击(DDoS)指的是通过多台机器向一个服务或者网站发送大量看似合法的数据包使其网络阻塞.资源耗尽从而不能为正常用户提供正常服务的攻击手段.随着互联网带宽的增加和相关工具的不断发布,这种 ...
- Linux CAT与ECHO命令详解 <<EOF EOF
Linux CAT与ECHO命令详解 cat命令是Linux下的一个文本输出命令,通常是用于观看某个文件的内容的: cat主要有三大功能: .一次显示整个文件. $ cat filename .从键盘 ...
- Linux下查看机器公网IP
http://jimingsong.iteye.com/blog/1188905 curl http://ifconfig.me
- win8内置管理员用户无法激活此应用
在运行中输入:“gpedit.msc”,就会启动组策略编辑器, 计算机配置 --> Windows设置 --> 安全设置 --> 本地策略 --> 安全选项 :::: 用 ...