概率图模型之EM算法
一、EM算法概述
EM算法(Expectation Maximization Algorithm,期望极大算法)是一种迭代算法,用于求解含有隐变量的概率模型参数的极大似然估计(MLE)或极大后验概率估计(MAP)。EM算法是一种比较通用的参数估计算法,被广泛用于朴素贝叶斯、GMM(高斯混合模型)、K-means(K均值聚类)和HMM(隐马尔科夫模型)的参数估计。
隐变量是指不能被直接观察到,但是对系统的状态和能被观察到的变量存在影响的变量,比如经典的三硬币模型中,能被观察到的变量是在某次实验中,先后丢两枚硬币的最终结果,比如1或0(1表示正面朝上,0表示背面朝上),而隐变量是第一枚硬币抛掷后的结果(假设是别人抛的,我们不能看到抛第一枚硬币的结果)。用HMM进行词性标注时,可以观察到的变量是词语,而隐变量是每个词的词性。
二、EM算法的迭代步骤
用Y表示可观测随机变量的数据,Z表示隐随机变量的数据,则Y和Z的数据合起来称为完全数据,而单独的观测数据Y称为不完全数据。
给定观测数据Y,θ为需要估计的参数。假设Y和Z的联合概率分布为P(Y, Z|θ),那么完全数据的对数似然函数是logP(Y, Z|θ);假设Y的概率分布为P(Y| θ),那么不完全数据Y的对数似然函数是L(θ)=logP(Y|θ)。
EM算法的目标是什么呢?EM算法的目标是通过迭代,求不完全数据的对数似然函数L(θ)=logP(Y, Z|θ)的极大似然估计,这可以转化为求完全数据的对数似然函数logP(Y, Z|θ)的期望的极大似然估计。
EM算法迭代的步骤如下:
输入:观测变量数据Y,隐变量数据Z,联合分布P(Y, Z|θ),条件分布P(Z|Y,θ);
输出:模型参数θ。
1、选择参数的初始值 θ(0),开始迭代;
2、E步:求期望。记第i次迭代后参数 θ的估计值为θ(i),在第i+1次迭代时,计算完全数据的对数似然函数logP(Y, Z|θ)的期望。
这个期望的完整表述非常长:在给定观测数据Y和第i轮迭代的参数θ(i)时,完全数据的对数似然函数logP(Y, Z|θ)的期望,计算期望的概率是隐随机变量数据Z的条件概率分布P(Z|Y, θ(i))。我们把这个期望称为Q函数。

一般我们求期望是用n个样本的概率分布去求,而这里是用隐随机变量数据Z的条件概率分布去求。(在三硬币模型中,这个Z的条件概率分布是抛掷第一枚硬币得到正面或反面的概率:Z∈{正面,反面},P(Z=正面|Y, θ(i))=π,P(Z=反面|Y, θ(i))=1-π。)
3、M步:求极大。求使得Q(θ ,θ(i))极大化的θ,确定第i+1次迭代的参数估计值θ(i+1)。
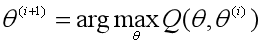
4、重复第2步和第3步,直到收敛而停止迭代。停止迭代的条件是,对于较小的正数ε1、ε2,满足:

其中,函数Q(θ ,θ(i))是EM算法的核心,是完全数据的对数似然函数logP(Y, Z|θ)的期望,我们把求不完全数据的对数似然函数L(θ)=logP(Y, Z|θ)的极大似然估计的问题,转化为求Q函数的极大化问题
三、EM算法的推导
(一)Jensen不等式
EM算法的推导需要用到Jensen不等式,一般以凸函数为例来介绍Jensen不等式。
设f(x)是一个定义域在实数集上的函数,如果在x∈R上满足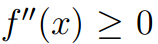 ,那么称f(x)为凸函数,进一步如果
,那么称f(x)为凸函数,进一步如果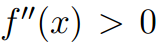 对于所有的x都成立,那么f(x)为严格凸函数。假设X是随机变量,那么凸函数的Jensen不等式定义为:
对于所有的x都成立,那么f(x)为严格凸函数。假设X是随机变量,那么凸函数的Jensen不等式定义为:

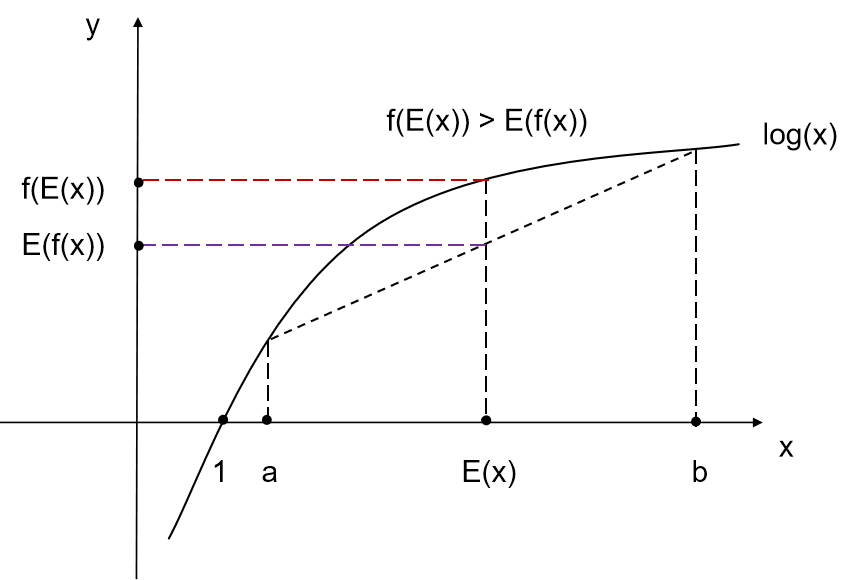
从下图中可以非常直观地理解这个不等式。
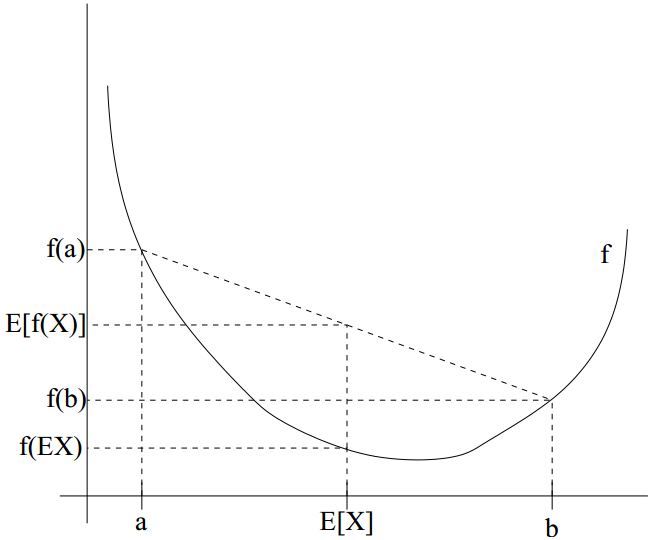
而凹函数的Jensen不等式的不等号方向相反。EM算法中的对数似然函数log(x)的二阶导数为(-1/x2)< 0,底数取自然对数e,那么不等号方向与上面凸函数的相反。EM算法中的Jensen不等式的公式和图如下:
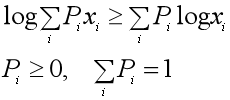
(二) EM算法的推导
EM算法是用Q函数的极大化,来近似实现对不完全数据Y的对数似然函数的极大似然估计,下面我们从不完全数据Y的对数似然函数的极大似然估计问题来导出EM算法。
1、原始目标:对于含有隐变量的概率模型,极大化不完全数据Y关于参数θ的对数似然函数,即极大化:
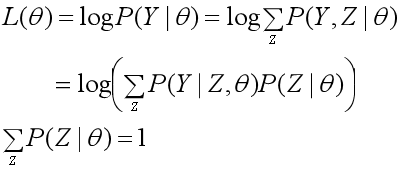
2、假设在第i次迭代后参数θ的估计值是θ(i),EM算法就是让新的估计值θ使L(θ)增加,即L(θ)>L(θ(i)),并逐步逼近极大值。为此,计算二者的差:
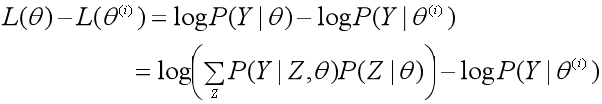
3、用Jensen不等式得到差值的下界:

于是L(θ)的下界为:

4、选择下一个参数θ(i+1),极大化L(θ)的下界B(θ, θ(i)):
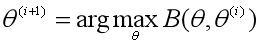
省略掉对参数极大化而言是常数的项,就得到了极大化Q函数Q(θ, θ(i))的表达式:

于是我们得到了第i+1次迭代时的Q函数:

5、不断求解下界的极大化或者说Q函数的极大化,来逼近对数似然函数L(θ)=logP(Y|θ)的极大化。
四、EM算法收敛性的证明
证明EM算法会收敛,其实就是证明不完全数据Y的对数似然函数L(θ)=logP(Y|θ)是单调递增的,即L(θ(i+1)) ≥ L(θ(i)),而且有上界,那么必然会收敛到一个值。而P(Y|θ)作为概率的乘积,必然小于1,有上界,所以EM算法的收敛性也就是证明Y的似然函数P(Y|θ)是单调递增的,即P(Y|θ(i+1)) ≥ P(Y|θ(i))。于是有以下的证明。
1、定理:设L(θ)=logP(Y|θ)是观测数据Y的对数似然函数,θ(i)(i=1,2,...,n)是EM算法得到的参数估计序列,L(θ(i))为对应的对数似然函数序列,则L(θ(i))=logP(Y|θ(i))必定会收敛到某一值L*。
2、证明思路:只要证明log(x)是单调递增函数(以e为底),且x有上界即可。在EM算法中,P(Y|θ)是有上界的,又log(x)单调递增,因此只要证明P(Y|θ)是单调递增的。
3、证明观测数据Y的似然函数P(Y|θ)是单调递增的,即P(Y|θ(i+1)) ≥ P(Y|θ(i)):
由于:
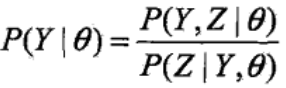
取对数得到:

已知Q函数为:
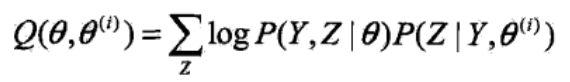
再构造一个H函数:

由:
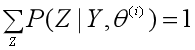
于是对数似然函数可以写成:
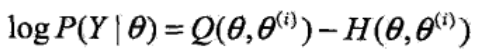
分别取θ为θ(i)、θ(i+1),让对数似然函数相减,有:

对于等式右端的第一项,由于θ(i+1)是使Q(θ, θ(i+1))达到极大所得到的,所以有:

再看等式右端的第二项,同样运用Jensen不等式:
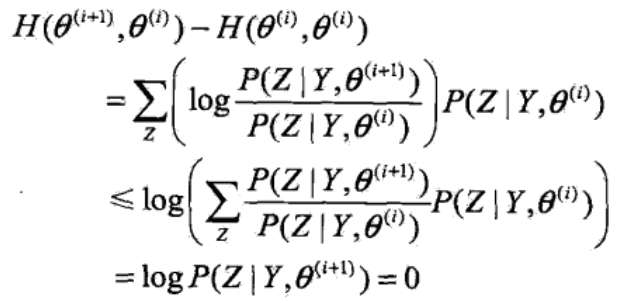
于是得到:
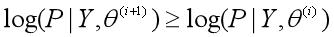
参考资料:
1、李航:《统计学习方法》
2、CS229:《The EM algorithm 》
概率图模型之EM算法的更多相关文章
- 含隐变量模型求解——EM算法
1 EM算法的引入1.1 EM算法1.2 EM算法的导出2 EM算法的收敛性3EM算法在高斯混合模型的应用3.1 高斯混合模型Gaussian misture model3.2 GMM中参数估计的EM ...
- 聚类之高斯混合模型与EM算法
一.高斯混合模型概述 1.公式 高斯混合模型是指具有如下形式的概率分布模型: 其中,αk≥0,且∑αk=1,是每一个高斯分布的权重.Ø(y|θk)是第k个高斯分布的概率密度,被称为第k个分模型,参数为 ...
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- EM算法[转]
最大期望算法:EM算法. 在统计计算中,最大期望算法(EM)是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量. 最大期望算法经过两个步骤交替进行计算: 第 ...
- 机器学习-EM算法笔记
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断,混合高斯模型 ...
- EM 算法-对鸢尾花数据进行聚类
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍过K 均值算法,它是一种聚类算法.今天介绍EM 算法,它也是聚类算法,但比K 均值算法更加灵活强大. ...
- 文本主题模型之LDA(三) LDA求解之变分推断EM算法
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法 本文是LDA主题模型的第三篇,读这一篇之前 ...
- NLP —— 图模型(零):EM算法简述及简单示例(三硬币模型)
最近接触了pLSA模型,该模型需要使用期望最大化(Expectation Maximization)算法求解. 本文简述了以下内容: 为什么需要EM算法 EM算法的推导与流程 EM算法的收敛性定理 使 ...
- 记录:EM 算法估计混合高斯模型参数
当概率模型依赖于无法观测的隐性变量时,使用普通的极大似然估计法无法估计出概率模型中参数.此时需要利用优化的极大似然估计:EM算法. 在这里我只是想要使用这个EM算法估计混合高斯模型中的参数.由于直观原 ...
随机推荐
- 手搓SSM
相关资料,网上的资料很多,但是文章看不懂,看别人写好的代码比较好理解 ssm-example mysssm 整个流程和原理 一个入口类,入口类需要在tomcat启动的时候执行 通过扫描文件加把文件取出 ...
- SQL注入之SQLmap
注意:sqlmap只是用来检测和利用sql注入点的,并不能扫描出网站有哪些漏洞,使用前请先使用扫描工具扫出sql注入点. 1.
- P3919 【模板】可持久化数组 -初步探究主席树
本篇blog主要是给自己(大家)看的. 感谢longlongzhu123奆佬(此人初二LCT)的指点,使本蒟蒻可以快速开始主席树入门. what is 主席树? $ $主席树这个名字只不 ...
- ubuntu18.04下安装node
安装Node.js Ubuntu 18.04在其默认存储库中包含一个版本的Node.js,可用于在多个系统间提供一致的体验. 在撰写本文时,存储库中的版本是8.10.0. 这不会是最新的版本,但它应该 ...
- C#中集合接口关系笔记
IEnumerable IEnumerable接口是所有集合类型的祖宗接口,其作用相当于Object类型之于其它类型.如果某个类型实现了IEnumerable接口,就意味着它可以被迭代访问,也就可以称 ...
- python基础面试题1
Python面试重点(基础篇) 注意:只有必答题部分计算分值,补充题不计算分值. 第一部分 必答题(每题2分) 简述列举了解的编程语言及语言间的区别? c语言是编译型语言,运行速度快,但翻译时间长py ...
- 如何知道某个ACTIVITY是否在前台?
本文链接:http://zengrong.net/post/1680.htm 有一个Android应用包含包含一个后台程序,该程序会定期连接服务器来实现自定义信息的推送.但是,当这个应用处于前台的时候 ...
- Windows7 wampServer3.0.6 Mutillidae2.7.12
在Mac上访问虚拟机中的mutillidae,报403: By default, Mutillidae only allow access from localhost ***: Parallels ...
- 题解 UVA10298 【Power Strings】
此题我写的是后缀数组SA解法,如果不会后缀数组的可以跳过本篇blog了. 参考文献:罗穗骞 2009集训队后缀数组论文 前记 最近学后缀数组,肝了不少题,也分出了后缀数组的几个题型,看这题没有后缀数组 ...
- 无线渗透--wifiphisher之wifi钓鱼获取wifi密码
本来是想试验一下暴力破解的,但是由于字典太大,跑的时间也比较长,于是使用了钓鱼的方法. 先说一下wifiphisher钓鱼获取wifi密码的原理: wifiphisher对于你在攻击中选定的wifi会 ...