python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建
这次代码只需要改变pipyline就行
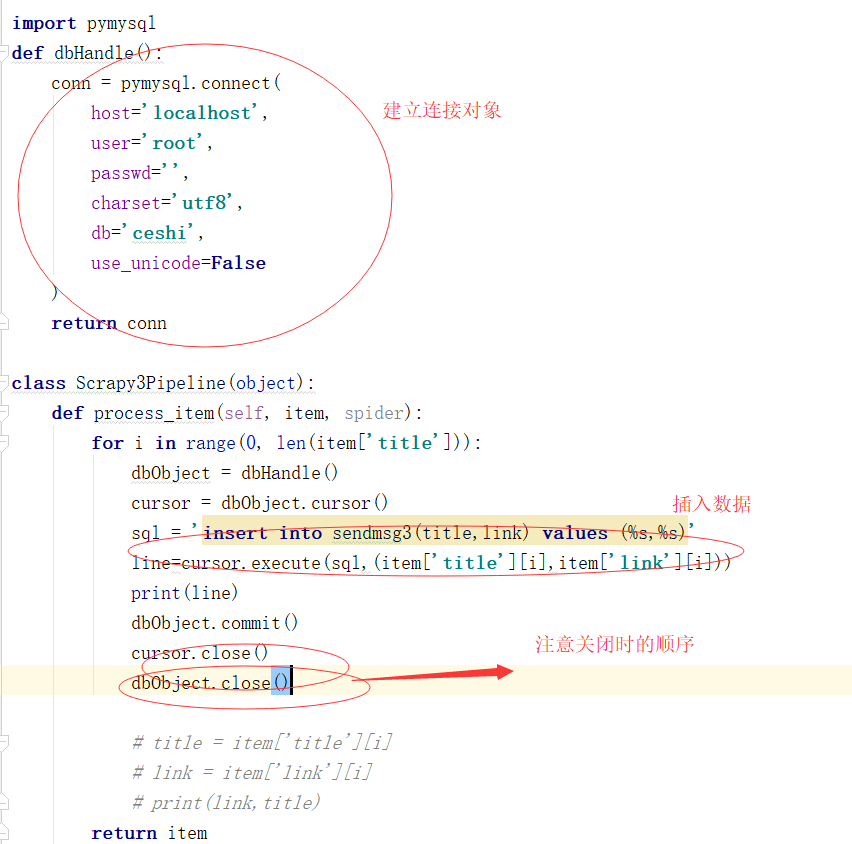
来 现在看下结果:
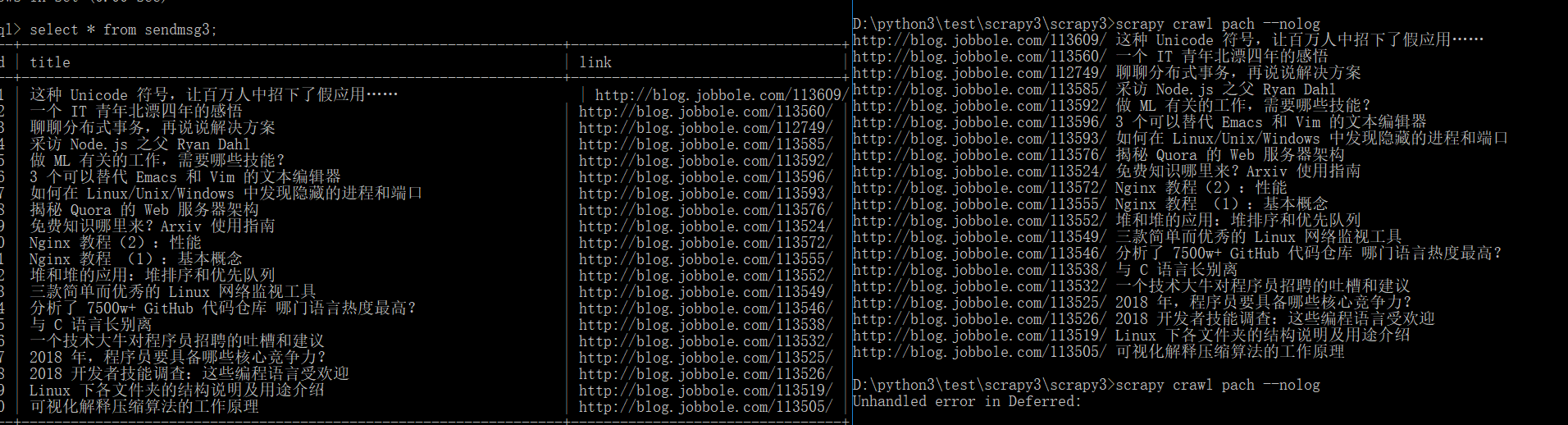
对比发现数据准确无误
python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)的更多相关文章
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- windows环境下nutch2.x 在eclipse中实现抓取数据存进mysql详细步骤
nutch2.x 在eclipse中实现抓取数据存进mysql步骤 最近在研究nutch,花了几天时间,也遇到很多问题,最终结果还是成功了,在此记录,并给其他有兴趣的人提供参考,共同进步. 对nutc ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第九卷:scrapy数据存储进JSON文件)
将爬取数据存储在JSON文件里并不难,只需修改pipelines文件 直接看代码: 来看下结果: 中文字符恶心的很 之后我会在后卷中做出修改
- python3下应用pymysql(第三卷)(数据自增-用于爬虫)
在上卷中我说出两种方法进行数据去重自增,第一种就是在数据库的字段中设置唯一字段,二是在脚本语言中设置重复判断再添加(建议,二者同时使用,真正开发中就会用到) 话不多说先上代码 第一步: 确定那一字段的 ...
- scrapy爬虫系列之开头--scrapy知识点
介绍:Scrapy是一个为了爬取网站数据.提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速抓取.Scrapy使用了Twisted异步网络框架,可以加快我们的下载速度. 0.说明: ...
- scrapy数据存储在mysql数据库的两种方式
方法一:同步操作 1.pipelines.py文件(处理数据的python文件) import pymysql class LvyouPipeline(object): def __init__(se ...
随机推荐
- 不会美工的前端不是好UE
1.UE.美工.前端的工作似乎很类似,用不同的形式去画出页面效果.UE用AXURE,美工用PS,前端用代码. 2.我是一个前端,在好几家公司都是自己默默的一个人,所以在做好本职工作的同时,近朱者赤. ...
- python pandas写入excel文件
pandas读取.写入csv数据非常方便,但是有时希望通过excel画个简单的图表看一下数据质量.变化趋势并保存,这时候csv格式的数据就略显不便,因此尝试直接将数据写入excel文件. pandas ...
- WINSCP 使用笔记
前期准备: 1.官网下载:http://winscp.net/eng/docs/lang:chs 官网C#示例:http://winscp.net/eng/docs/library#csharp 当然 ...
- rpc框架解释
远程过程调用协议RPC(Remote Procedure Call Protocol) RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方 ...
- spring学习之spring入门
一 spring的基础 1:什么是spring spring是由Rod Johnson组织和开发的一个分层 的Java SE/EE 一站式轻量级开源框架,它以Ioc(控制反转)和 AOP(面向切面编程 ...
- jsp动作标签学习
<jsp:useBean> <jsp:useBean>标签用于在指定的域范围内查找指定名称的JavaBean对象,如果存在则直接返回该JavaBean对象的引用,如果不存在则实 ...
- 多分类度量gini index
第一份工作时, 基于 gini index 写了一份决策树代码叫ctree, 用于广告推荐. 今天想起来, 好像应该有开源的其他方法了. 参考 https://www.cnblogs.com/mlhy ...
- 在scala命令行中加入类库
在scala命令行中加入scala的类库. scala -toolcp $HOME/.ivy2/cache/org.scalanlp/breeze_2.12/jars/breeze_2.12-0.13 ...
- R语言 批量下载财务报表
getsheets <- function(symbol,type,file){ pre="http://money.finance.sina.com.cn/corp/go.php/v ...
- 安装完Ubuntu后没有设置过root密码,想要进入root账户怎么办?
安装完Ubuntu后没有设置过root密码,想要进入root账户怎么办? Ubuntu的默认root密码是随机的,即每次开机都有一个新的root密码.我们可以在终端输入命令 sudo passwd,然 ...