Linux文件IO与通用块层的请求合并
本文参考https://mp.weixin.qq.com/s/Imt4BW-zoHPpcOpcKZs_AQ, 公众号“Linux阅码场”
请求合并就是将进程内或者进程间产生的在物理地址上连续的多个IO请求合并成单个IO请求一并处理,从而提升IO请求的处理效率。首先给出IO请求的整体框图,如下:
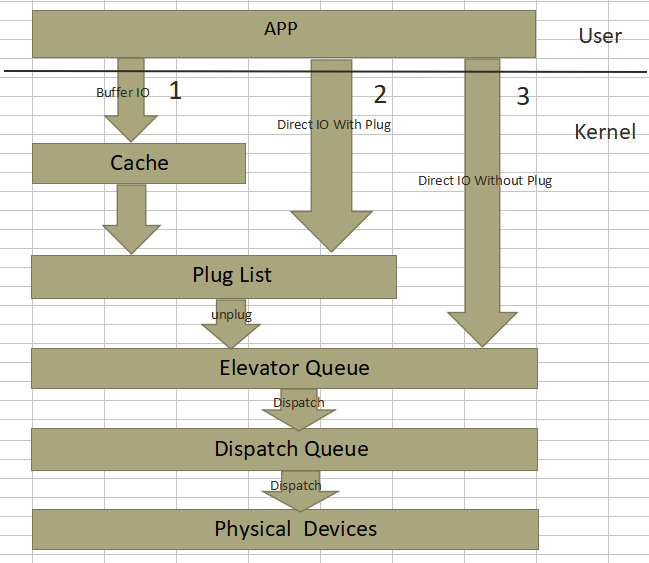
缓存IO, 对应图中的路径1,系统中绝大部分IO走的这种形式,充分利用filesystem 层的page cache所带来的优势, 应用程序产生的IO经系统调用落入page cache之后便可以直接返回,page cache中的缓存数据由内核回写线程在适当时机负责同步到底层的存储介质之上,当然应用程序也可以主动发起回写过程(如fsync系统调用)来确保数据尽快同步到存储介质上,从而避免系统崩溃或者掉电带来的数据不一致性。缓存IO可以带来很多好处,首先应用程序将IO丢给page cache之后就直接返回了,避免了每次IO都将整个IO协议栈走一遍,从而减少了IO的延迟。其次,page cache中的缓存最后以页或块为单位进行回写,并非应用程序向page cache中提交了几次IO,回写的时候就需要往通用块层提交几次IO, 这样在提交时间上不连续但在空间上连续的小块IO请求就可以合并到同一个缓存页中一并处理。再次,如果应用程序之前产生的IO已经在page cache中,后续又产生了相同的IO,那么只需要将后到的IO覆盖page cache中的旧IO,这样一来如果应用程序频繁的操作文件的同一个位置,我们只需要向底层存储设备提交最后一次IO就可以了。最后,应用程序写入到page cache中的缓存数据可以为后续的读操作服务,读取数据的时候先搜索page cache,如果命中了则直接返回,如果没命中则从底层读取并保存到page cache中,下次再读的时候便可以从page cache中命中。
非缓存IO(带蓄流),对应图中的路径2,这种IO绕过文件系统层的cache。用户在打开要读写的文件的时候需要加上“O_DIRECT”标志,意为直接IO,不让文件系统的page cache介入。从用户角度而言,应用程序能直接控制的IO形式除了上面提到的“缓存IO”,剩下的IO都走的这种形式,就算文件打开时加上了 ”O_SYNC” 标志,最终产生的IO也会进入蓄流链表(图中的Plug List)。如果应用程序在用户空间自己做了缓存,那么就可以使用这种IO方式,常见的如数据库应用。
非缓存IO(不带蓄流),对应图中的路径3,内核通用块层的蓄流机制只给内核空间提供了接口来控制IO请求是否蓄流,用户空间进程没有办法控制提交的IO请求进入通用块层的时候是否蓄流。严格的说用户空间直接产生的IO都会走蓄流路径,哪怕是IO的时候附上了“O_DIRECT” 和 ”O_SYNC”标志,用户间接产生的IO,如文件系统日志数据、元数据,有的不会走蓄流路径而是直接进入调度队列尽快得到调度。注意一点,通用块层的蓄流只提供机制和接口而不提供策略,至于需不需要蓄流、何时蓄流完全由内核中的IO派发者决定。
如果是缓存IO,应用层写的数据会存到page cache中,块层会以page为单位构造bio请求。
从应用层到物理设备之间存在3个队列,记为plug list续流队列、调度队列、分发队列。从上到下的调用依次为:
->submit_bh
->submit_bh_wbc(int rw, struct buffer_head *bh, unsigned long bio_flags, struct writeback_control *wbc) (这里还在文件系统层,将来自cache的数据封装成bio)
->submit_io(这里到了通用块层)
->generic_make_request
->make_request_fn(这里注册的为blk_queue_bio)
最终调用到了blk_queue_bio,这个函数将bio构造为request并负责写入plug list续流链表中,如果bio可以和plug list中的request合并,则进行合并,如果不能合并,则构造新的request。(这里面起始很复杂,还会涉及到调度队列,会尝试和调度队列中的request合并),blk_queue_bio的主要处理流程如下图所示:
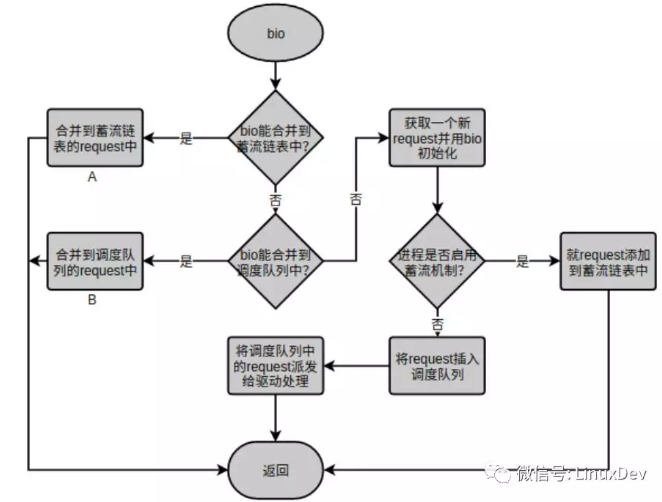
在内核卸流(unplug)的时候,plug list续流链表中的请求(request)会批量提交给调度器,调度器维护了很多数据结构,卸流函数blk_flush_plug_list回调用调度器的elevator_add_req_fn() 回调函数,它将plug list中的request合并到调度队列,这个合并主要为进程间的合并,并根据各个请求的轻重缓急、对硬盘的访问顺序等因素,把这些请求排序,维护在调度器的数据结构中。卸流函数blk_flush_plug_list(调用elevator_add_req_fn() )先将plug list中所有的request派发到调度队列再一次性queue_unplugged(调用elevator_dispatch_fn())派发到分发队列。当最后真正执行请求访问硬盘的时候,request_fn() 回调函数被调用,从分发队列取出请求去执行。看到这里,可以认为分发队列是调度器里面的一个队列,是调度器的一部分,它和调度器中的其他数据结构共同完成请求的处理。这个分发队列也就是写驱动程序时注册的request_queue,而驱动程序中也会注册一个request处理函数,这个函数正是request_fn的回调函数。
驱动中一般会执行以下函数:
struct request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);
这个函数会初始化一个请求队列,也就是上面说到的分发队列,并把默认的调度器挂到这个队列上(调度器和这个队列可以认为是一体的,把这个队列留给用户来设置只是为了给用户留出接口用来从队列中取reauest,我们上面说的调度队列可以认为是调度器中维护的一些数据结构,而驱动中注册的request_queue可以认为是分发队列),这样的话这三个队列就连起来了,再来捋一遍:
内核调用调度器的elevator_add_req_fn() 将plug list中的请求派发到调度器的数据结构中(调度队列),然后调用elevator_dispatch_fn()将调度队列中的请求派发到分发队列,最后调用request_fn从分发队列中取出请求并执行请求访问硬盘。
对硬盘类的块设备操作时,需要对请求进行合并、调度,会用到三个队列,但是SSD类的存储设备可以随机访问,可以在拿到bio后直接执行,这是就不需要三个队列的存在、也不需要调度了,这时的驱动程序编写就需要用另一种方法了,而不是用blk_init_queue(request_fn_proc *rfn, spinlock_t *lock)函数了,一般操作如下:
xxx_queue = blk_alloc_queue(GFP_KERNEL);
blk_queue_make_request(xxx_queue, xxx_make_request);
这里虽然申请了队列,但是用不到,用户只需要在xxx_make_request中直接处理文件系统层送过来的bio即可,这样就不会涉及到任何队列了。使用硬盘块设备时会用到三个队列,xxx_make_request也是内核默认的,这时的xxx_make_request会将bio请求构造成request送到plug list中。
以上知识点为参考了多篇公众号文章后的总结,如有理解错误之处请留言,不胜感激,文章开头处有原文链接。
Linux文件IO与通用块层的请求合并的更多相关文章
- 转:Linux 文件IO理解
源地址http://blog.csdn.net/lonelyrains/article/details/6604851 linux文件IO操作有两套大类的操作方式:不带缓存的文件IO操作,带缓存的文件 ...
- 转 漫谈linux文件IO
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO.本篇文件打算详细全面,深入浅出.剖析文件IO的细节.从多个角度探索如何提高IO性能.本文尽量用 ...
- 漫谈linux文件IO
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO.本篇文件打算详细全面,深入浅出.剖析文件IO的细节.从多个角度探索如何提高IO性能.本文尽量用 ...
- <摘录>linux文件IO
这篇文章写的比较全面,也浅显易懂,备份下.转载自:http://blog.chinaunix.net/uid-27105712-id-3270102.html 在Linux 开发中,有几个关系到性能的 ...
- linux 文件IO
1.文件描述符 (1)文件描述符的本质是一个数字,这个数字本质上是进程表中文件描述符表的一个表项,进程通过文件描述符作为index去索引查表得到文件表指针,再间接访问得到这个文件对应的文件表.(2)文 ...
- 2.Linux文件IO编程
2.1Linux文件IO概述 2.1.0POSIX规范 POSIX:(Portable Operating System Interface)可移植操作系统接口规范. 由IEEE制定,是为了提高UNI ...
- linux文件io与标准io
文件IO实际是API,Linux对文件操作主要流程为:打开(open),操作(write.read.lseek),关闭(close). 1.打开文件函数open(): 涉及的头文件: #includ ...
- Linux文件IO操作
来源:微信公众号「编程学习基地」 目录 文件操作 Linux文件类型 Linux文件权限 修改文件权限 Linux error 获取系统调用时的错误描述 打印错误信息 系统IO函数 open/clos ...
- linux文件IO操作篇 (一) 非缓冲文件
文件IO操作分为 2 种 非缓冲文件IO 和 缓冲文件IO 它们的接口区别是 非缓冲 open() close() read() write() 缓冲 fopen() fclose() fread() ...
随机推荐
- Python 以指定宽度格式化输出
当对一组数据输出的时候,我们有时需要输出以指定宽度,来使数据更清晰.这时我们可以用format来进行约束 mat = "{:20}\t{:28}\t{:32}" print(mat ...
- js 捕捉滚轮的滚动
滚动方向区分为正负: <!DOCTYPE html> <html> <head lang="en"> <meta charset=&quo ...
- gulp4小demo
本来想着用gulp搭建一个自动化构建工具,结果一顿报错,后来发现我重新安装的gulp版本是4.0.0,与3版本还是不太一样的,遂记之. Gulp 3版本Demo: const gulp = requi ...
- Codeforces 757B - Bash's Big Day(分解因子+hashing)
757B - Bash's Big Day 思路:筛法.将所有因子个数求出,答案就是最大的因子个数,注意全为1的特殊情况. 代码: #include<bits/stdc++.h> usin ...
- Python map/reduce
2017-07-31 18:20:59 一.map函数 map():会根据提供的函数对指定序列做映射.第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 ...
- spring boot 2.0 + 静态资源被拦截,怎么办?
问题描述:使用springboot 2.0后,按照springboot 1.5版本(以下简称旧版)的方式去配置项目.结果发现静态资源访问不到了,本文对此情况分析.处理 项目结构: 直接上图 如果是在旧 ...
- centos7: iptables保存(配置完nginx的web规则后)
centos7: iptables保存(配置完nginx的web规则后) 以本地虚拟机为例: 添加规则:入站规则 iptables -I INPUT -p tcp --dport 80 -j ACCE ...
- 在 Confluence 6 中的 Jira 设置
名字(Name) 输入一个有意义的服务器名字,会让你在 JIRA 服务器中更好的识别你的目录服务器: Jira Service Desk Server My Company Jira 服务器URL(S ...
- Java中/r和/n的区别
/n换行符,效果是新换一行,光标在原有位置下一行 /r回车符,效果是光标来到下一行行首
- PHP函数总结 (五)
<?php /** * 回调函数: * 指调用函数时并不是传递一个标准的变量作为参数,而是将另一个函数作为参数传递到调用的函数中 * 使用回调函数可以 将一段自己定义的功能传到函数内部使用 * ...