BM25 调参调研
1. 搜索 ES 计算文本相似度用的 BM25,参数默认,不适合电商场景,可调整 BM25 参数使其适用于电商短文本场景
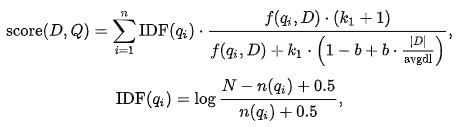
2. k1、b、tf、L、tfScore 的关系如下图红框内所示(注:这里的 tf 即上式中的 f(qi,D))。

3. k1 用来控制公式对词项频率 tf 的敏感程度。((k1 + 1) * tf) / (k1 + tf) 的上限是 (k1+1),也即饱和值。当 k1=0 时,不管 tf 如何变化,BM25 后一项都是 1;随着 k1 不断增大,虽然上限值依然是 (k1+1),但到达饱和的 tf 值也会越大;当 k1 无限大时,BM25 后一项就是原始的词项频率。一句话,k1 就是衡量高频 term 所在文档和低频 term 所在文档的相关性差异,在我们的场景下,term 频次并不重要,该值可以设小。ES 中默认 k1=1.2,可调整为 k1=0.3。
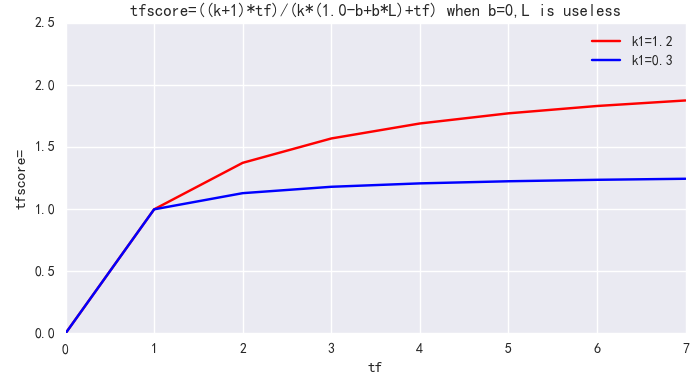
4. b 用来控制文档长度 L 对权值的惩罚程度。b=0,则文档长度对权值无影响,b=1,则文档长度对权值达到完全的惩罚作用。ES 中默认 b=0.75,可调整为 b=0.1。
5. IDF 一项无参可调,这里只说明一点,公式中当 n(q) 超过 N/2 非常大时,IDF 有得到负值的可能,Lucene’s BM25 实现时对 log 中的除式做了加 1 处理,Math.log(1 + (docCount - docFreq + 0.5D)/(docFreq + 0.5D)),使其永远大于 1,取 log 后就不会得到负值。
参考资料:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
- https://en.wikipedia.org/wiki/Okapi_BM25
- https://www.elastic.co/guide/en/elasticsearch/guide/current/pluggable-similarites.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/practical-scoring-function.html
- http://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/
- 《信息检索导论》p160
BM25 调参调研的更多相关文章
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- word2vec参数调整 及lda调参
一.word2vec调参 ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -neg ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
- 漫谈PID——实现与调参
闲话: 作为一个控制专业的学生,说起PID,真是让我又爱又恨.甚至有时候会觉得我可能这辈子都学不会pid了,但是经过一段时间的反复琢磨,pid也不是很复杂.所以在看懂pid的基础上,写下这篇文章,方便 ...
- hyperopt自动调参
hyperopt自动调参 在传统机器学习和深度学习领域经常需要调参,调参有些是通过通过对数据和算法的理解进行的,这当然是上上策,但还有相当一部分属于"黑盒" hyperopt可以帮 ...
- 调参必备---GridSearch网格搜索
什么是Grid Search 网格搜索? Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找最 ...
- random froest 调参
https://blog.csdn.net/wf592523813/article/details/86382037 https://blog.csdn.net/xiayto/article/deta ...
随机推荐
- word 加载adobe acrobat ,保存word中的清晰图片
1:先安装 adobe 并激活 https://blog.csdn.net/xintingandzhouyang/article/details/82558235 2:打开word,点击 文件&g ...
- 完成向后台添加用户的ssm项目,完整版
1:ssm框架整合 1.1添加maven依赖pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns: ...
- (转)Mybatis insert后返回主键给实体对象(Mysql数据库)
<insert id="insert" parameterType="com.zqgame.game.website.models.Team"> & ...
- 项目发布脚本-go
#!/bin/bash export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin clear printf &q ...
- col-md-*和col-sm-*
屏幕大于(≥992px) ,使用col-md-* 而不是col-sm-*如果屏幕大于(≥768px),小雨<=992px,使用col-sm-* 而不是col-md-*
- sklearn_Logistic Regression
一.什么是逻辑回归? 一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法 面试高危问题:Sigmoid函数的公式和性质 Sigmoid函数是一个S型的函 ...
- Python + logging 输出到屏幕,将log日志写入文件
日志 日志是跟踪软件运行时所发生的事件的一种方法.软件开发者在代码中调用日志函数,表明发生了特定的事件.事件由描述性消息描述,该描述性消息可以可选地包含可变数据(即,对于事件的每次出现都潜在地不同的数 ...
- mysql查询表基本操作
数据库表的创建create table <表名>( <列名> <数据类型及长度> [not null], <列名> <数据类型及长度>, . ...
- JS方法的使用
$("#yingxiang_id li").each(function () { if ($(this).find(".div-relative").attr( ...
- MySQL数据库----存储过程
存储过程 存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql -- 存储过程的优点: -- 1.程序与数据实现解耦 -- 2.减少网络传输的 ...