BM25 调参调研
1. 搜索 ES 计算文本相似度用的 BM25,参数默认,不适合电商场景,可调整 BM25 参数使其适用于电商短文本场景
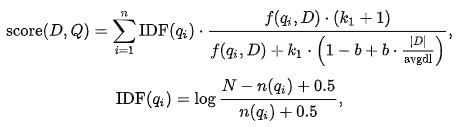
2. k1、b、tf、L、tfScore 的关系如下图红框内所示(注:这里的 tf 即上式中的 f(qi,D))。

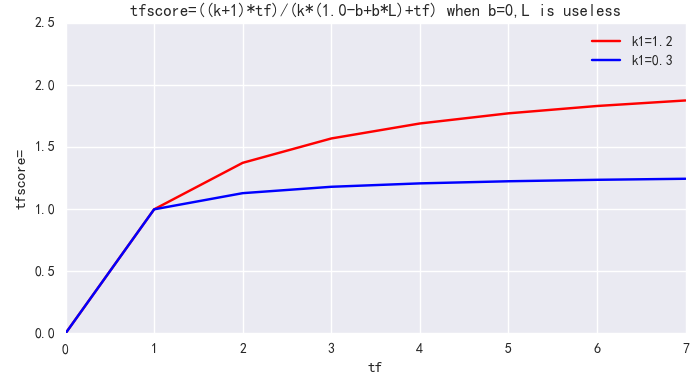
3. k1 用来控制公式对词项频率 tf 的敏感程度。((k1 + 1) * tf) / (k1 + tf) 的上限是 (k1+1),也即饱和值。当 k1=0 时,不管 tf 如何变化,BM25 后一项都是 1;随着 k1 不断增大,虽然上限值依然是 (k1+1),但到达饱和的 tf 值也会越大;当 k1 无限大时,BM25 后一项就是原始的词项频率。一句话,k1 就是衡量高频 term 所在文档和低频 term 所在文档的相关性差异,在我们的场景下,term 频次并不重要,该值可以设小。ES 中默认 k1=1.2,可调整为 k1=0.3。
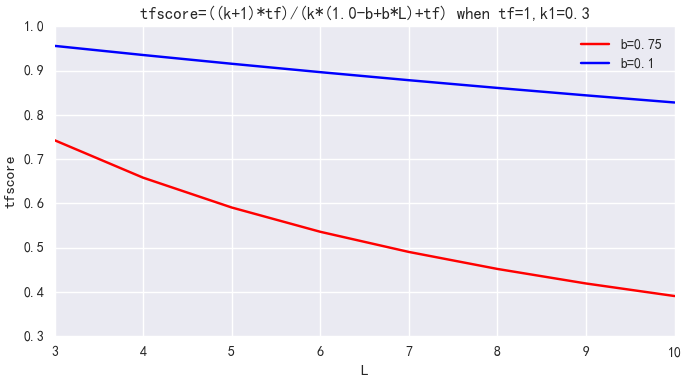
4. b 用来控制文档长度 L 对权值的惩罚程度。b=0,则文档长度对权值无影响,b=1,则文档长度对权值达到完全的惩罚作用。ES 中默认 b=0.75,可调整为 b=0.1。
5. IDF 一项无参可调,这里只说明一点,公式中当 n(q) 超过 N/2 非常大时,IDF 有得到负值的可能,Lucene’s BM25 实现时对 log 中的除式做了加 1 处理,Math.log(1 + (docCount - docFreq + 0.5D)/(docFreq + 0.5D)),使其永远大于 1,取 log 后就不会得到负值。
参考资料:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
- https://en.wikipedia.org/wiki/Okapi_BM25
- https://www.elastic.co/guide/en/elasticsearch/guide/current/pluggable-similarites.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/practical-scoring-function.html
- http://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/
- 《信息检索导论》p160
BM25 调参调研的更多相关文章
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- word2vec参数调整 及lda调参
一.word2vec调参 ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -neg ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
- 漫谈PID——实现与调参
闲话: 作为一个控制专业的学生,说起PID,真是让我又爱又恨.甚至有时候会觉得我可能这辈子都学不会pid了,但是经过一段时间的反复琢磨,pid也不是很复杂.所以在看懂pid的基础上,写下这篇文章,方便 ...
- hyperopt自动调参
hyperopt自动调参 在传统机器学习和深度学习领域经常需要调参,调参有些是通过通过对数据和算法的理解进行的,这当然是上上策,但还有相当一部分属于"黑盒" hyperopt可以帮 ...
- 调参必备---GridSearch网格搜索
什么是Grid Search 网格搜索? Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找最 ...
- random froest 调参
https://blog.csdn.net/wf592523813/article/details/86382037 https://blog.csdn.net/xiayto/article/deta ...
随机推荐
- abap关键字
1:abap将提升的关键字快捷输入 按tab键,提示的关键字将会自动输入. 2:shift tab 用于对其格式 3:ctrl+d 将改行复制到下一行.
- pem转cer
openssl x509 -inform pem -in fullchain.pem -outform der -out fullchain.cer
- Java多线程的下载器(1)
实现了一个基于Java多线程的下载器,可提供的功能有: 1. 对文件使用多线程下载,并显示每时刻的下载速度. 2. 对多个下载进行管理,包括线程调度,内存管理等. 一:单个文件下载的管理 1. 单文件 ...
- Jason使用
Jason是一种数据传输时候的一种格式,类似XML. package liferay; import java.beans.IntrospectionException; import java.be ...
- mysql表空间文件
1.共享表空间文件.默认表空间文件是ibdata1,大小为10M,且可拓展.共享表空间可以由多个文件组成,一个表可以跨多个文件而存在,共享表空间的最大值限制是64T. 2.独立表空间文件.独立表空间只 ...
- STA分析(二) multi_cycle and false
multicycle path:当FF之间的组合逻辑path propagate delay大于一个时钟cycle时,这条combinational path能被称为multicycle path. ...
- 解决nginx下不能require根目录以外的文件
我们常规的做法是将统一入口文件.css.js这些放在网站根木,其他php文件放到根目录外部,这个时候nginx访问是require不到的,需要设定一下 1.vi /usr/local/nginx/c ...
- Repeater 控件使用总结
关于Repeater控件使用的一些总结,希望能对将来有机会看到这篇日志的同事有所帮助.也是为了在自己开发有所遗忘的时候能够参考一下.前言:Repeater是一个迭代控件,什么是迭代控件呢?书本上的 ...
- linux常用命令:chgrp 命令
在 lunix系统里,文件或目录的权限的掌控以拥有者及所诉群组来管理.可以使用chgrp指令变更文件与目录所属群组,这种方式采用群组名称或群组识别 码都可以.chgrp命令就是change group ...
- js dom 操作技巧
1.创建元素 创建元素:document.createElement() 使用document.createElement()可以创建新元素.这个方法只接受一个参数,即要创建元素的标签名.这个标签名在 ...